
From Helper Scripts to Causal Inference Programming
AI code generation has quietly moved from novelty to everyday tool. Developers, analysts, and researchers now lean on systems like ChatGPT to draft Python helpers, translate between R and Stata, or quickly debug error messages. The real question is no longer whether AI can produce code at all, but whether it can be trusted with complex, methodology-heavy tasks. A recent case study focuses on exactly this point: can ChatGPT-4.0 Pro correctly implement advanced causal inference programming workflows, not just toy examples? Instead of asking for simple regressions or basic data cleaning, the researchers push the model to handle demanding econometric analyses that mix data preparation, model specification, and interpretation. As reliance on AI coding assistants grows, this kind of stress test illustrates a crucial shift: code quality now depends not only on human skill, but also on how reliably an opaque model executes sophisticated statistical logic.
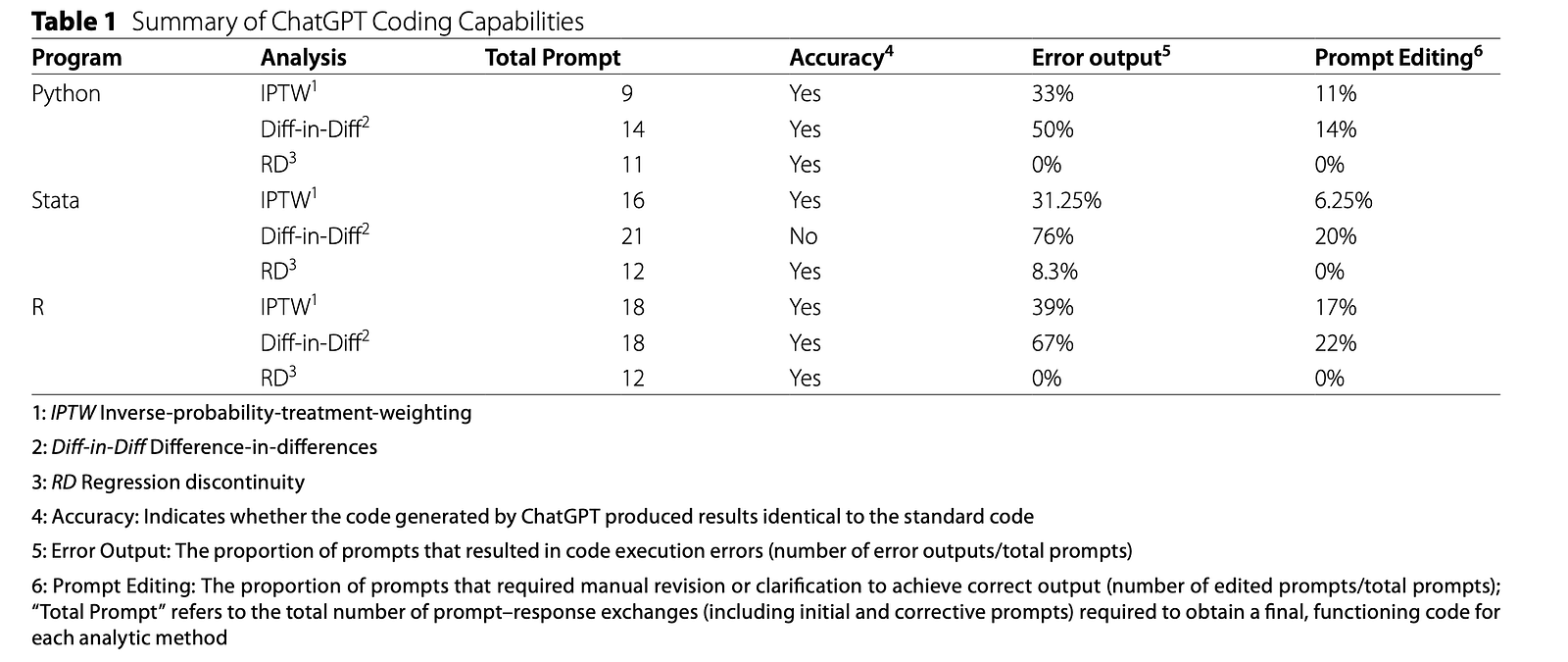
Testing ChatGPT on Difference-in-Differences, IPTW, and RD
The new study, published in Health Economics Review as “Can AI write your code? A case study of ChatGPT’s statistical coding capabilities for quantitative research,” evaluates ChatGPT-4.0 Pro on three cornerstone causal inference methods: Difference-in-Differences, Inverse Probability Treatment Weighting, and Regression Discontinuity. Using problem sets and benchmark solutions from Scott Cunningham’s Causal Inference: The Mixtape, the authors assess performance across Python, R, and Stata. Crucially, they do not rely on subjective impressions of whether the generated code “looks right.” Instead, they execute ChatGPT’s code in reference environments and compare the resulting outputs to standardized benchmarks. Prompts range from specific tasks, such as estimating dynamic treatment effects in a Diff-in-Diff setting, to full workflows that include data management and figure generation. This design mimics real research practice, where an AI assistant must navigate entire analytical pipelines rather than isolated commands.
Why Output Verification Matters for AI Code Generation
The study’s most important methodological contribution lies in how it evaluates ChatGPT coding reliability. Instead of treating human judgment as the final arbiter, the authors require the AI-generated code to reproduce benchmark tables and figures. This approach turns AI output verification into a concrete, testable process: does the code run, and does it match known causal estimates? For quantitative researchers, this matters because causal inference programming is highly sensitive to model specification and data handling details. A syntactically correct script can still implement the wrong weighting scheme, misalign treatment timing, or misconfigure a regression discontinuity window. As AI code generation tools become embedded in everyday workflows, developers and data scientists need standardised ways to validate that the model has implemented the intended econometric design, not just produced plausible-looking code that passes superficial inspection.
A New Control Method to Check If AI Really Does What You Ask
The need for reliable checks is not limited to academic code. In high‑risk domains, an incorrect AI instruction can translate into unsafe behaviour. Responding to this challenge, Master’s student Panagiotis Kalogeropoulos and lecturer‑researcher Herman Jurjus have developed a control method that acts as a double safety check for AI systems. Before an AI‑driven component becomes operational, their framework verifies two things: whether the AI has correctly understood the human instruction and whether the proposed action is safe. The system first has the AI generate code for the task, then evaluates that code and produces a risk assessment from multiple stakeholder perspectives. Humans can then approve or reject the code based on this assessment. In parallel, a panel of multiple AI systems can add further scrutiny. This design moves beyond blind trust in a single “black box” and toward structured, auditable oversight.
Implications for Debugging, Governance, and Enterprise Adoption
Taken together, the ChatGPT causal inference study and the new control framework highlight an emerging norm: AI‑assisted coding must be paired with robust verification. For practitioners, this means treating AI suggestions as draft code that must be benchmarked, tested, and risk‑assessed, especially when implementing complex statistical methods. For organizations, it points to the need for governance structures that combine human expertise, automated checks, and possibly multi‑model panels to monitor AI behaviour. In enterprise environments, where code underpins critical analytics or embedded systems, such frameworks could determine whether AI code generation accelerates innovation or introduces hidden vulnerabilities. Rather than asking whether AI can replace human programmers, the more productive question becomes how to design workflows where AI coding tools are powerful collaborators whose outputs are systematically validated before they influence real‑world decisions.