What Gemini 3.5 Live Translate Is and Why Timing Matters
Gemini 3.5 Live Translate is Google’s AI audio model for real-time voice translation that processes speech continuously, aims to stay only seconds behind the speaker, and preserves natural voice cues so multilingual conversations feel more like normal dialogue than turn-taking between humans and machines. The model targets the timing gap that has long limited multilingual speech translation tools: earlier systems waited for a sentence or long phrase to finish before translating, forcing speakers to pause and breaking conversational rhythm. By contrast, Gemini 3.5 Live Translate starts working almost as soon as someone speaks, generating translated audio while the sentence is still unfolding. Google describes this as a deliberate trade-off: it prefers speed and fluid conversation over waiting for perfect context, then corrects on the fly when later words change the meaning. That approach reframes real-time voice translation as a streaming process rather than a sequence of completed chunks.

Continuous Speech Processing: How Google Shrinks Translation Lag
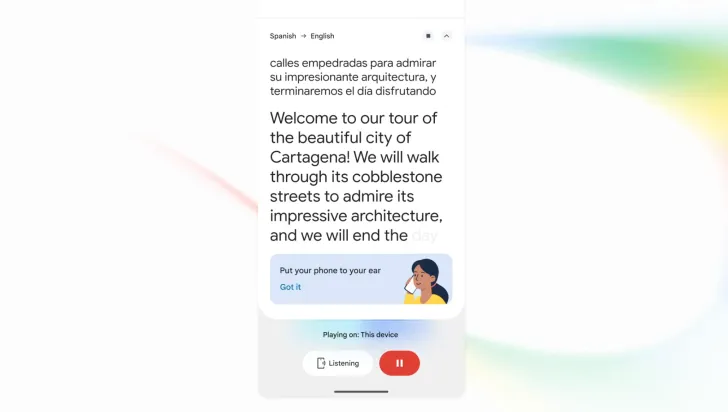
The core change in Gemini 3.5 Live Translate is continuous speech processing. Instead of the familiar pattern where a user talks, stops, then hears a translated block, the model keeps listening and speaking with only a small delay. Google says the system stays a few seconds behind the speaker throughout a session, rather than waiting for full sentences, which reduces the awkward silence that used to define many real-time voice translation tools. This streaming design lets the model adjust mid-sentence if later words alter the intended meaning, much like human simultaneous interpreters who revise as they go. The output is not only fast but also expressive: Gemini 3.5 Live Translate preserves intonation, pacing, and pitch so translations sound more lifelike. Noise handling and automatic language detection further help it cope with real-world calls, where speakers may switch languages or talk in busy environments without configuring settings first.
From Google Meet to Translate: Real-Time Voice Translation at Platform Scale
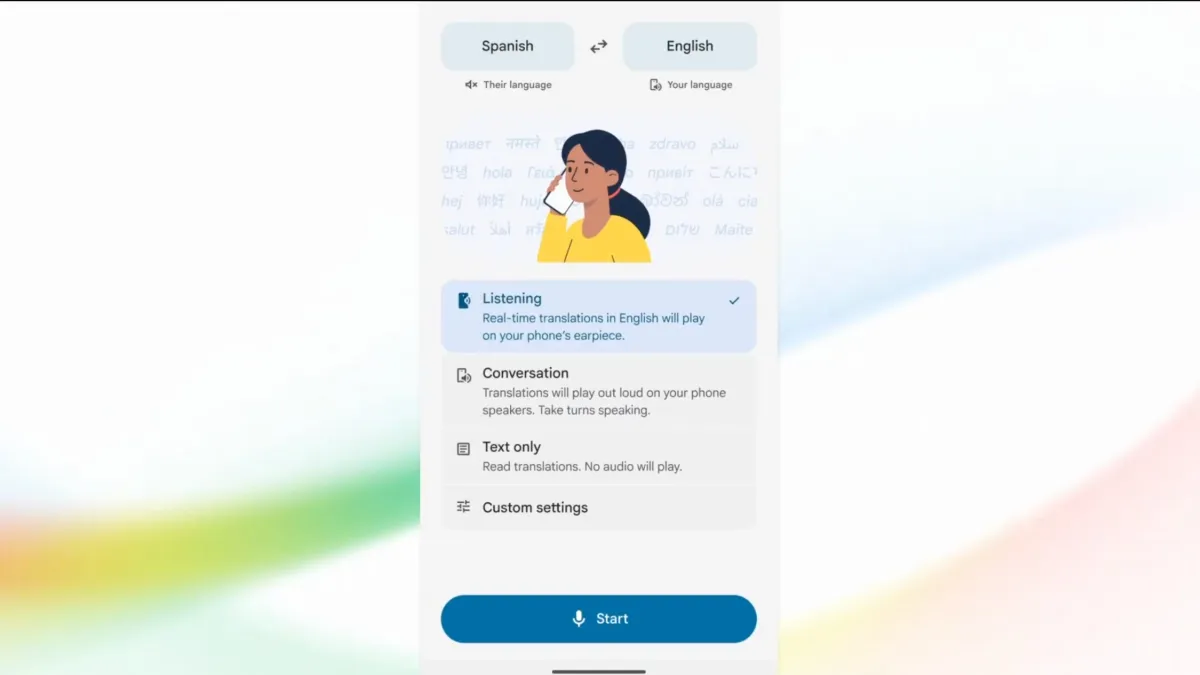
Gemini 3.5 Live Translate supports more than 70 languages and is arriving across Google’s stack as a platform, not a niche feature. It is accessible through the Gemini Live API and Google AI Studio in public preview, is rolling out in the Google Translate app on Android and iOS, and is entering private preview for Google Meet before a broader release later. This unified audio model means Google Meet translation no longer needs English as a required pivot language and can support over two thousand language pair combinations in a single meeting. According to Google, that shift turns Meet from an English-centered tool into an environment where many languages can coexist in one call. At the same time, Grab is piloting the system to handle more than 10 million monthly in-app voice calls between drivers and riders, testing whether continuous speech processing holds up in short, noisy, high-stakes conversations.
Listening Mode, Watermarking, and Developer Access
Alongside speed and coverage, Google is adding features that shape how people and developers will use Gemini 3.5 Live Translate. On Android, a new listening mode lets users hold the phone to their ear like a call, routing translated audio through the earpiece instead of speakers or headphones. This makes ad hoc multilingual speech translation more discreet in public places and more practical when earbuds are not available. All AI-generated audio carries SynthID watermarking, embedded in the sound but inaudible, so organizations can verify that output comes from an AI model without disturbing listeners. For builders, Gemini 3.5 Live Translate is exposed through the Gemini Live API and Google AI Studio with enterprise-focused controls, enabling integration into customer-support lines, conferencing platforms, or industry tools that need continuous speech processing. Together, these choices show Google treating multilingual speech translation as infrastructure for communication products rather than an experimental add-on.





