Claude AI Code Generation Redefines Anthropic’s Engineering Work
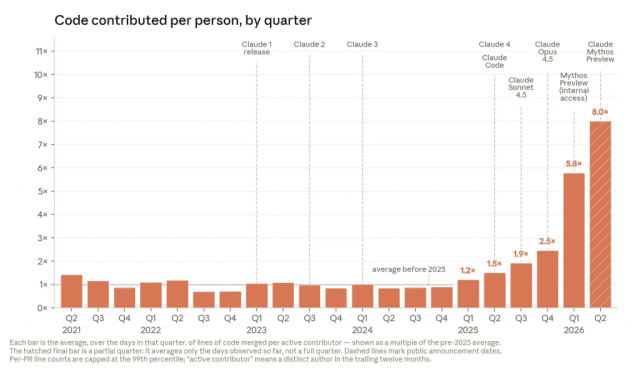
Claude AI code generation refers to Anthropic’s use of its Claude models to create most of the software code that powers its products, with human engineers shifting from writing code themselves to reviewing, steering, and integrating AI-generated changes into production systems. Anthropic reports that the average lines of code merged per active contributor have reached around eight times the pre‑2025 baseline, marking a sharp break from the flat productivity levels seen from 2021 through 2024. According to OfficeChai, this surge maps closely to Claude Code’s release timeline and internal model upgrades, with productivity climbing across consecutive quarters. By late 2025, some engineers were allowing Claude Code to generate entire first drafts, then editing and merging them instead of starting from an empty editor. That change signals a broader restructuring of engineering work: the model produces the bulk of implementation details, while people focus on problem selection, architecture, and final approval.
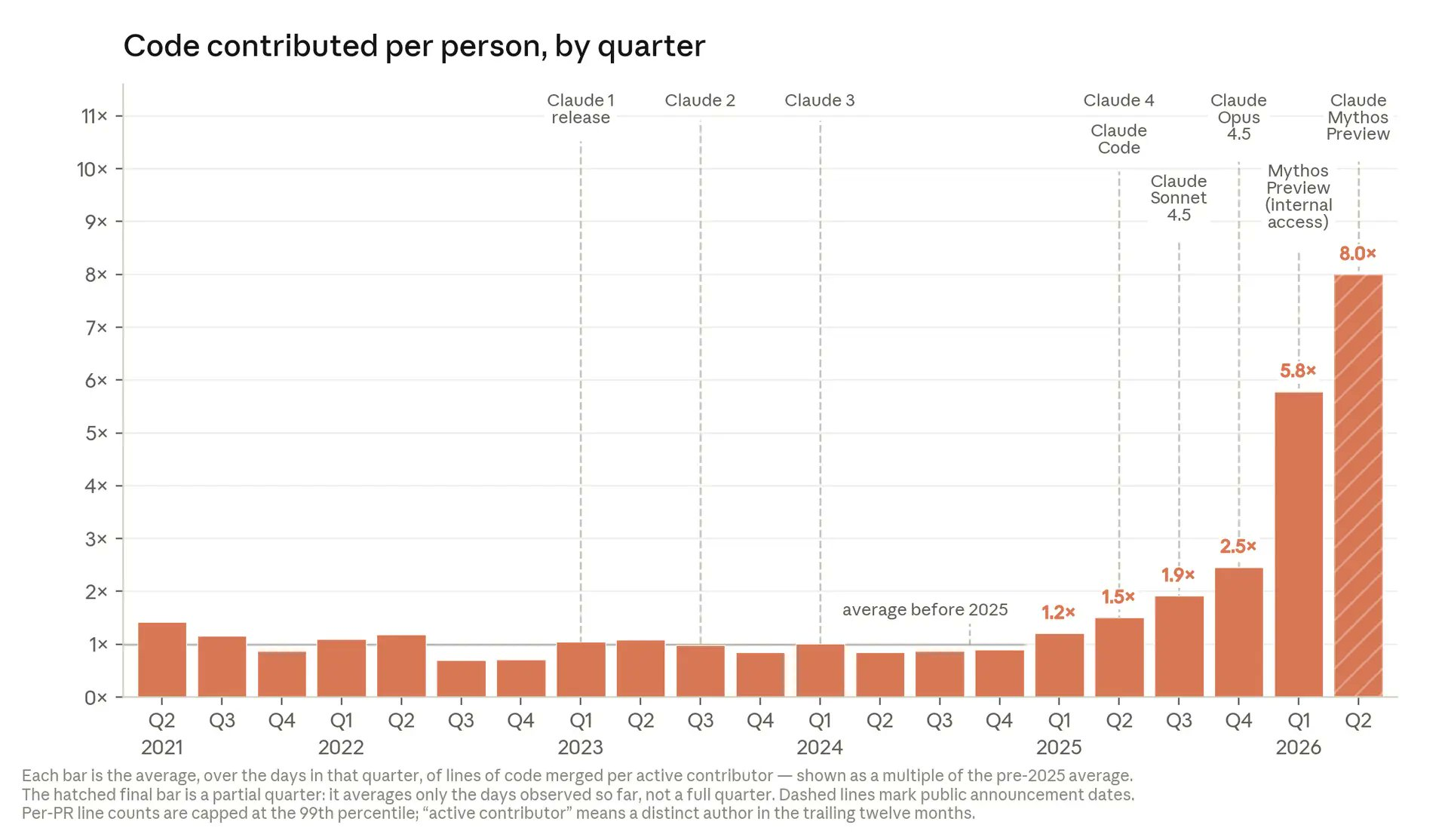
From 8x AI Productivity Gains to Self-Improving AI Systems
Anthropic’s internal numbers suggest more than 80% of production code merged in May was authored by Claude, aligning with the reported eightfold increase in code shipped per engineer. This level of automation hints at early self-improving AI systems, where models help develop, test, and refine the very software stack they run on. Anthropic notes that Claude’s success rate on its open‑ended internal engineering tasks hit 76%, after a rapid rise over six months, which supports treating the model as a development partner rather than a simple assistant. Yet the company stresses that full recursive self‑improvement remains a future possibility, not a current feature. For now, human engineers remain responsible for task selection, high‑level design, and final merges. A notable example is an internal repair project in which one engineer used Claude to ship hundreds of fixes for persistent API errors, cutting error rates dramatically while still keeping humans in charge of goals and risk.
AI Oversight Mechanisms: When Validation Becomes the Bottleneck
As Claude AI code generation accelerates output, the main risk has shifted from whether models can write code to whether humans and tools can review it in time. Anthropic emphasizes that engineers stay in the loop: they choose tasks, supervise Claude’s proposals, and control what reaches production. An automated reviewer scans suggested changes for bugs, security flaws, and other defects before merging, and Claude Code asks for permission before modifying files or running commands. This architecture builds layered AI oversight mechanisms: audit trails for each change, security checks, rollback paths, and enforced human approval gates. Local tools and strict merge discipline remain central. The practical bottleneck is no longer typing speed but validation capacity—how quickly teams can test, reason about, and approve AI-written code without missing subtle failures. For enterprise users of Claude, the same challenge appears: AI productivity gains only pay off if review pipelines grow as fast as generative capacity.
Anthropic’s Call for AI Development Safeguards and Pause Options
While celebrating productivity, Anthropic is also warning about the long‑term risks of self‑improving AI systems. The company says its research shows AI is already helping improve software and parts of its own development, raising the prospect that future systems could help create more powerful versions of themselves. That possibility drives Anthropic’s call for optional AI development safeguards, including the ability to temporarily pause advanced AI progress if capabilities move too quickly. According to the European Business Review, Anthropic wants policymakers, researchers, civil society, and other AI companies to explore mechanisms for stronger oversight and international cooperation. Critics argue the company may overstate potential dangers, while supporters see a needed counterweight to market pressure. In either case, the idea of a coordinated pause acknowledges that capability scaling is no longer a purely technical or commercial decision; it is also a governance and safety question.
Competitive Pressure vs. Control: An Industry-Wide Governance Test
Anthropic’s stance captures a wider paradox across the AI industry: companies race to deploy capable models that deliver huge AI productivity gains, even as they ask for brakes on uncontrolled capability growth. Claude’s role in writing most of Anthropic’s code shows how quickly AI can become central to core infrastructure, making any self‑improving loop both valuable and potentially risky. The firm’s push for AI development safeguards, such as pause options and stronger oversight, sits in tension with commercial incentives to keep releasing more powerful coding agents. Enterprises adopting Claude now face mirrored trade‑offs. They gain speed and scale from AI‑written code, but must invest in review capacity, security testing, and governance frameworks to keep control. How companies and regulators resolve this tension—between competitive deployment and cautious oversight—will shape whether self‑improving AI systems remain a managed tool or drift toward uncontrolled escalation.





