
Why Storage Architecture Matters More Than Logo Choice
Time-series database design is less about which engine you pick and more about how you store the data inside it. Every system—whether built on PostgreSQL, a dedicated time-series database, or a columnar format like Parquet—must answer the same questions: how are rows laid out, which fields are compressed, and how is data partitioned over time and space. These storage architecture optimization decisions directly determine how much disk you consume, how fast queries complete, and how far the system can scale before costs explode. In time-series workloads, the pattern is deceptively simple: timestamp, identifiers, and metrics repeated millions or billions of times. At enterprise AI scale, this repetition dominates both storage and compute. When models rely on up-to-the-second telemetry for predictions and automation, poorly chosen layouts or partitions can turn straightforward analytics into an I/O bottleneck, regardless of the database brand stamped on the box.
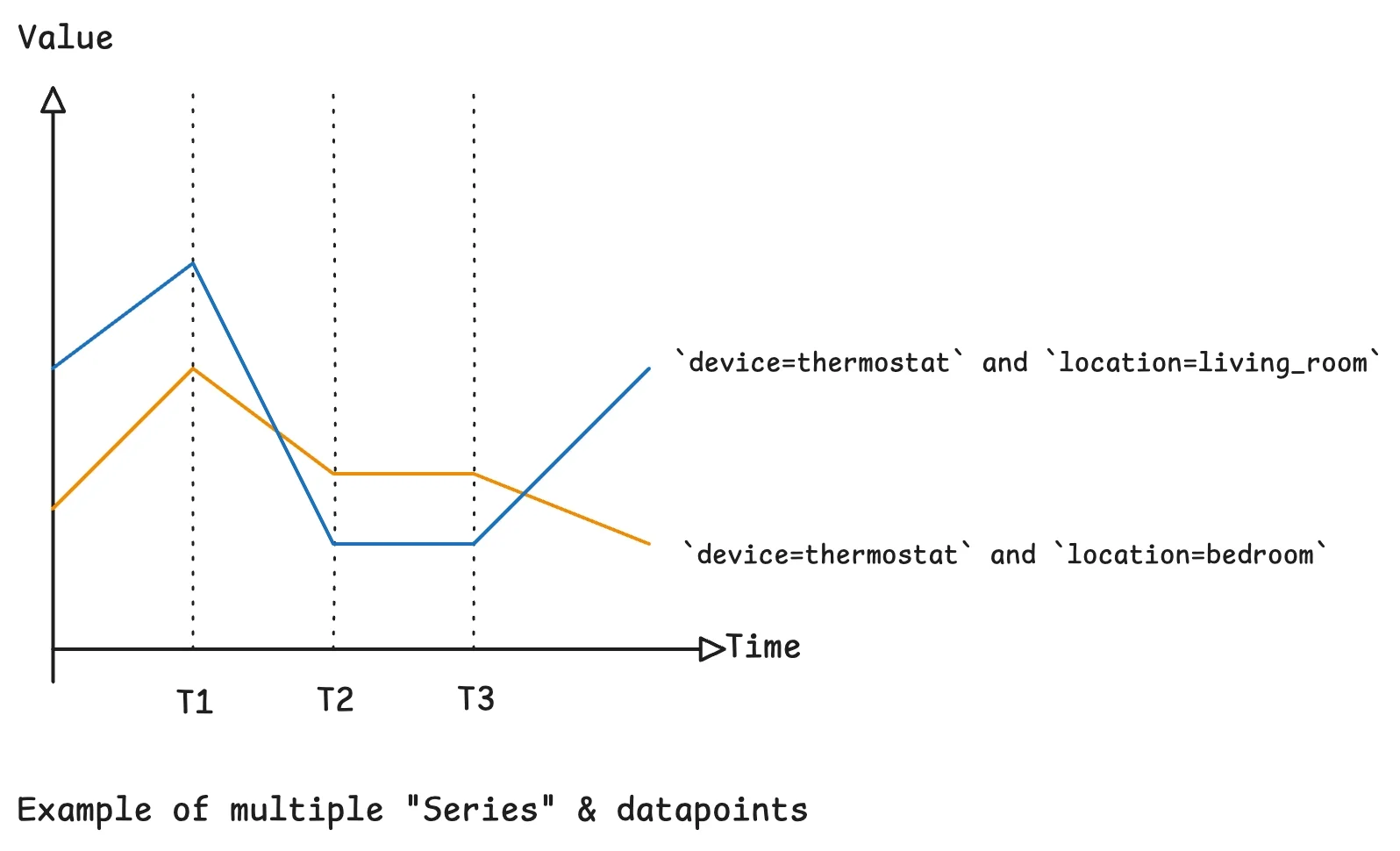
Modeling Time-Series: Series Identity, Metrics, and High Cardinality
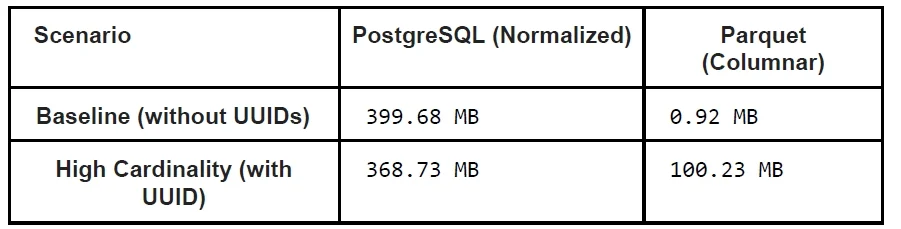
Effective time-series database design starts with modeling series identity separately from metrics. A series is typically defined by stable dimensions such as device ID, location, or region, while metrics hold the changing values you aggregate—temperatures, latencies, or utilization percentages. Queries filter and group on dimensions but compute over metrics, so getting this split right is critical for query performance tuning. A powerful pattern is to normalize these dimensions into a metadata table and reference them via compact numeric IDs in the main measurements table. Experiments show this can reduce storage by about forty-two percent because dimension strings are stored once per series instead of once per row. However, high-cardinality fields like request IDs or session tokens should not be part of series identity. When each event introduces a unique combination of dimensions, the number of series approaches the number of rows, collapsing normalization benefits and inflating both storage and index costs.
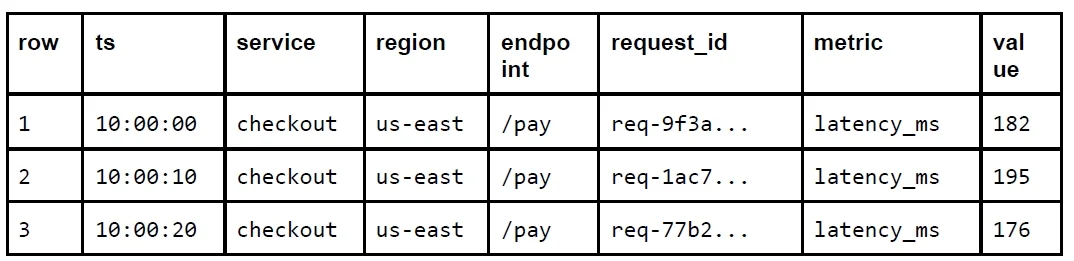
Row Layout and Compression: From Flat Tables to Normalized Storage
At the physical layer, row layout has an outsized impact on storage efficiency and query behavior. A flat schema repeats every dimension—device ID, location, region—on each row. This is easy to implement but multiplies dimension bytes by the total number of rows. In contrast, a normalized schema keeps a separate series table, assigns each identity combination a small integer, and stores only this ID alongside timestamp and metric values. In one PostgreSQL experiment containing roughly 2.8 million rows and one thousand series, normalization reduced storage usage by approximately forty-two percent without degrading range query latency and even improving some aggregate queries. Compression amplifies these gains: smaller, more uniform row structures compress better and fit more data into memory and cache, which reduces disk I/O and accelerates scans. For enterprise AI workloads that continuously ingest telemetry, this combination of normalization and thoughtful database compression strategies is a foundational lever for both cost control and high-throughput analytics.

Partitioning, Downsampling, and Lifecycle-Aware Storage
Partitioning defines how data is sliced across physical storage, and in time-series databases, time-based partitioning is usually the first axis. Segmenting data by day or hour enables constant-time expiration of old partitions and allows the query planner to prune large swaths of history for time-bounded queries. However, pure time partitioning creates a write hotspot on the current window. Adding a second axis—such as series identity or device group—distributes writes more evenly and narrows the range scans for focused queries. Beyond partitioning, downsampling and rollups are essential lifecycle tools. Aggregating raw five-second measurements into one-hour summaries reduces row counts by a factor of 720, freeing storage and accelerating historical analytics. Enterprise AI systems can keep high-resolution data only for recent windows feeding real-time decision loops, while serving longer-term trend analysis from pre-aggregated tables, striking a balance between fidelity, performance, and storage cost.
Designing Time-Series Storage for Enterprise AI Scalability
Enterprise AI workloads depend on streaming observability, user behavior logs, and operational metrics to feed models, trigger alerts, and adapt decisions in real time. All of this is time-series data, and its usefulness hinges on the underlying storage architecture. Optimized time-series database design combines normalized series identity, carefully chosen dimensions to avoid runaway cardinality, deliberate indexing on commonly filtered fields, and lifecycle-aware strategies like partitioning and downsampling. Together, these choices keep hot data in fast, compact structures while pushing colder, aggregated history into cost-efficient formats. For AI engineers and data platform teams, the lesson is clear: storage is not an afterthought. The same data, modeled differently, can mean the difference between sub-millisecond range queries and overloaded clusters. Investing in storage architecture optimization early ensures that as event volumes and model demands grow, the system remains both economically sustainable and performant enough for real-time intelligence.