
What Claude Fable 5 Is and Why It Matters
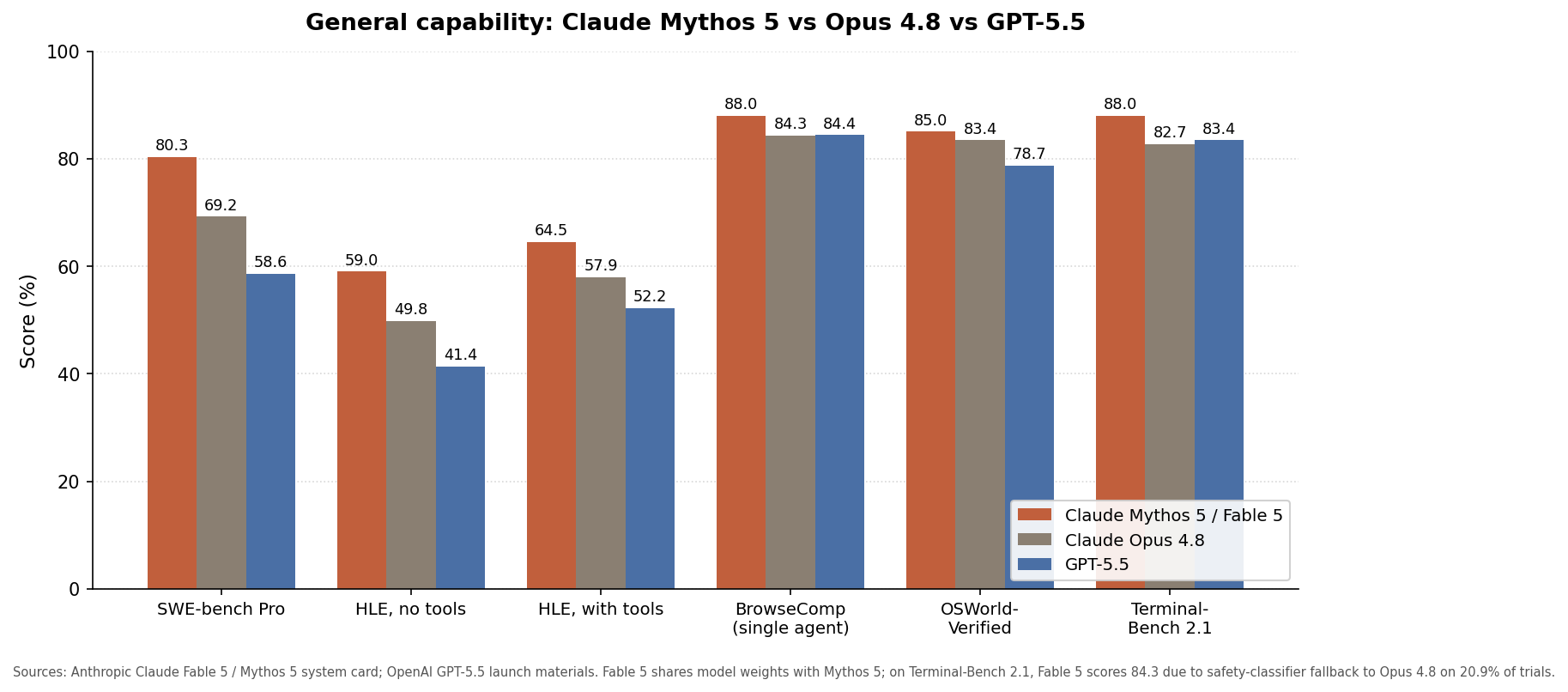
Claude Fable 5 is Anthropic’s first publicly available Mythos-class AI model that pairs higher coding and analytical performance with stricter safety routing, meaning it can feel substantially more capable than earlier Claude versions while still falling back to safer baselines for some security-sensitive tasks. Built on the same underlying weights as Mythos 5, Fable 5 adds classifiers that redirect high‑risk cybersecurity and biology prompts to Claude Opus 4.8. Anthropic positions it as a flagship for long, complex workflows, scoring 80.3% on SWE‑Bench Pro versus Opus 4.8’s 69.2% and exceeding 90% on a long‑running analytical benchmark from Hex. This uplift comes with clear AI model tradeoffs: higher token prices, faster session credit drain, and behavior that can silently switch models mid‑conversation. Understanding these tradeoffs is central to making smart choices about Claude Fable 5 performance in daily work.
Visible Output Gains: From Browser Games to Full Themes
Early tests show Fable 5’s coding AI capabilities extend beyond correctness into layout, structure, and visual polish. Given the same request to “Create a small ping pong game .html for me to play on the browser,” Fable 5 produced a navy playfield, distinct paddle colors, and a clean score display, while Opus 4.8 returned a more neutral arcade layout. Both games worked; Fable’s version looked designed. This pattern matches third‑party evaluations. Genspark reported stronger performance on UI design and game coding, and Anthropic says Fable 5 can rebuild a web app’s source code from a screenshot alone. According to Anthropic, “Fable 5 achieved the highest score among frontier models on Cognition’s FrontierCode evaluation.” In one test from Automattic’s Jamie Marsland, the model generated a fully editable WordPress block theme from a screenshot and URL in a single shot, underscoring its project‑level awareness.
Performance Versus Price: The Real Model Cost Comparison
The biggest practical tradeoff is cost. Anthropic prices Claude Fable 5 and Mythos 5 at USD 10 (approx. RM46) per million input tokens and USD 50 (approx. RM230) per million output tokens, exactly double the rate for Opus 4.8 at USD 5 (approx. RM23) and USD 25 (approx. RM115). On the same ping‑pong game prompt, Fable 5 consumed 109,035 session credits versus Opus’s 81,225, leaving 13.9 messages in the free tier compared with 18.7. Token counts were similar, which means the higher drain stems from pricing and accounting, not bloat. For teams planning dense coding sessions or long analytical runs, the model cost comparison is clear: Fable 5 offers better Claude Fable 5 performance, but you pay for every improvement in reasoning and design. That makes model choice less about single prompts and more about how many iterations your workflow can afford.

Security Fallbacks: When Fable 5 Quietly Becomes Opus 4.8
Fable 5’s Mythos‑class strength forced Anthropic to add aggressive safety controls, and those affect real‑world use. The model runs on Mythos 5 weights but auto‑routes many cybersecurity and biology‑related queries to Opus 4.8. In practice, this means your “Fable 5” tab can respond with Opus‑level capabilities whenever a task is classified as high‑risk. RDWorld notes that Anthropic previously kept Mythos off‑limits because it was too capable in cybersecurity, offering access only through a controlled Glasswing program for defense organizations. The public Fable 5 inherits that caution, limiting where its strongest reasoning can be used. For security engineers or red‑teaming tasks, the fallback undercuts the value of paying for a Mythos‑class session. Workflows that depend on end‑to‑end security reasoning should plan around this behavior or switch to tools that are designed for such use cases.
When Fable 5 Outperforms Opus—and When It Does Not
Across long coding runs, complex app work, and sustained analytical tasks, Fable 5 often makes older models feel slow. Stripe reported that it used Fable 5 to run a codebase‑wide migration across a 50‑million‑line Ruby codebase in a single day, compressing what it estimated as months of engineering work. Physical Superintelligence called it the strongest model it tested on frontier physics research while using about a third of the reasoning tokens. These gains and higher scores on finance, document reasoning, and complex analysis benchmarks mean Fable 5 is ideal when you need a project partner rather than a snippet generator. In contrast, for short answers, routine writing, or any workflow dominated by cybersecurity prompts, the extra cost and safety fallback reduce its advantage. A pragmatic strategy is to reserve Fable 5 for long‑running builds, refactors, and deep analysis, and keep Opus 4.8 as the cheaper default for everyday prompts.





