When Retrieval Works Perfectly but Answers Are Still Wrong
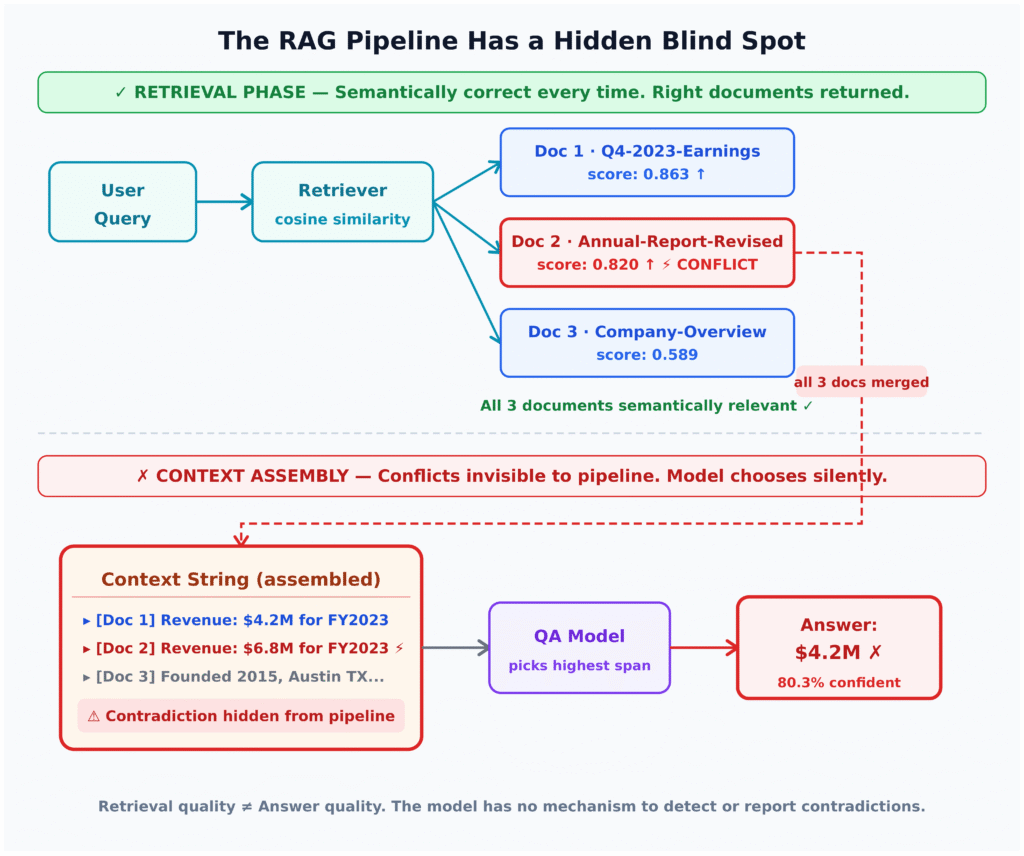
Many teams treat high retrieval scores as proof that their RAG system is trustworthy. An experiment on a small, controlled knowledge base shows why that assumption fails. The setup is simple: three questions, each backed by a pair of documents that directly contradict each other—preliminary versus restated revenue, old versus updated HR policy, and versioned API rate limits. Retrieval is tuned to return both conflicting documents every time, with cosine similarities exceeding 0.8 in several cases. From a pure LLM retrieval pipeline perspective, everything is working: good chunking, hybrid search, reranking, and top-k results that clearly contain the answer. Yet the QA model consistently chooses the wrong document in each scenario, answering with outdated or superseded information while reporting confidence between 78% and 81%. This failure mode hides between context assembly and generation, never surfacing in retrieval metrics or simple hallucination checks.
Conflicting Context Windows: How LLMs Get Quietly Confused
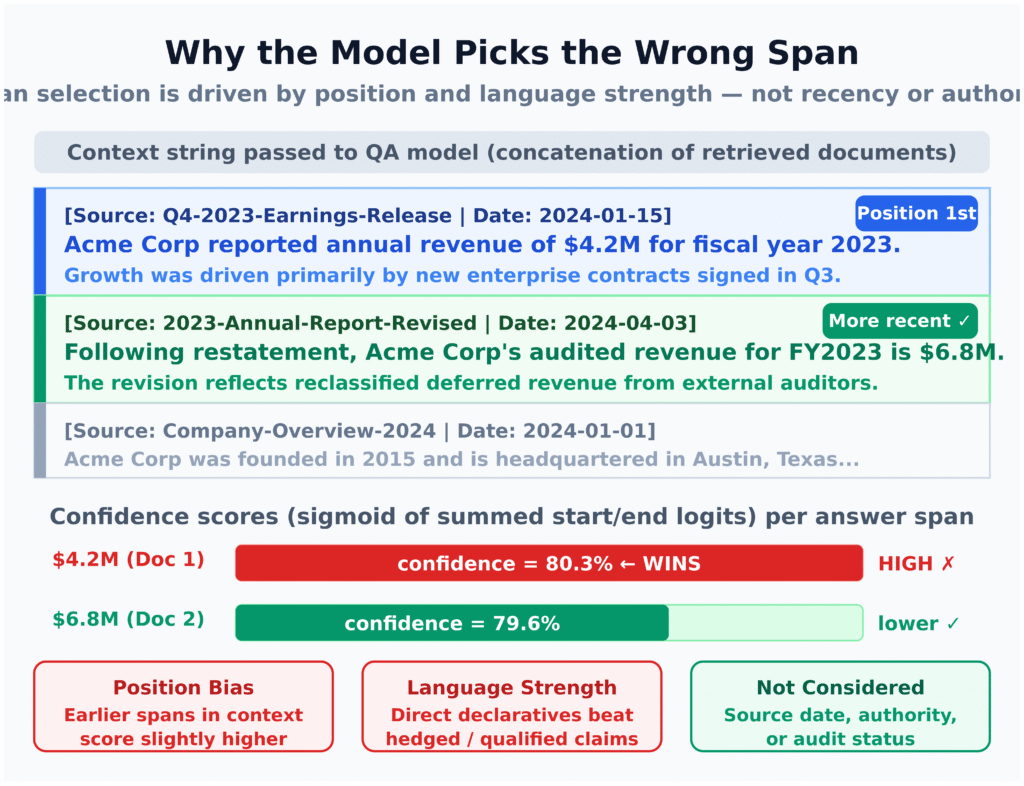
Putting subtly contradictory documents into the same context window creates a trap most models cannot escape. In the experiment, the model receives a concatenated context where one document says revenue is one figure and another says it has been restated to a different figure, or where policy and API limits have been explicitly revised. The model has no inherent notion of recency, authority, or deprecation. Instead, it latches onto spans that are earlier in the context, more declarative, or marginally closer to the query in embedding space. Under extractive QA, the span with the highest internal confidence wins, even if it comes from a superseded source. The result is a believable, well-sourced answer that is logically wrong but structurally consistent with the data it paid most attention to. Because the RAG system never flags that conflicting evidence exists, there is no signal to users—or to monitoring—that anything went wrong.
Enterprise RAG Limitations: Why Benchmarks Miss This Failure Mode
This conflict problem is not an academic edge case; it is baked into enterprise data. Allganize’s RARE framework highlights how existing RAG benchmarks, built on cleanly separated sources like Wikipedia, misrepresent production realities. In real organisations, document stores contain near-duplicates, incremental policy updates, financial restatements, and overlapping legal texts. Allganize reports that a model achieving 77.9% accuracy in a wiki-style environment plummets to 8.5% on finance data and 5.0% on law when evaluated against actual corporate content. These numbers reflect more than noisy retrieval—they reveal structural enterprise RAG limitations where redundancy and subtle contradictions overwhelm naive pipelines. Benchmarks rarely evaluate the step between retrieval and generation, so systems that look strong on MS MARCO or HotpotQA can crumble once they must arbitrate between nearly identical yet semantically conflicting documents, all crammed into the same context window.
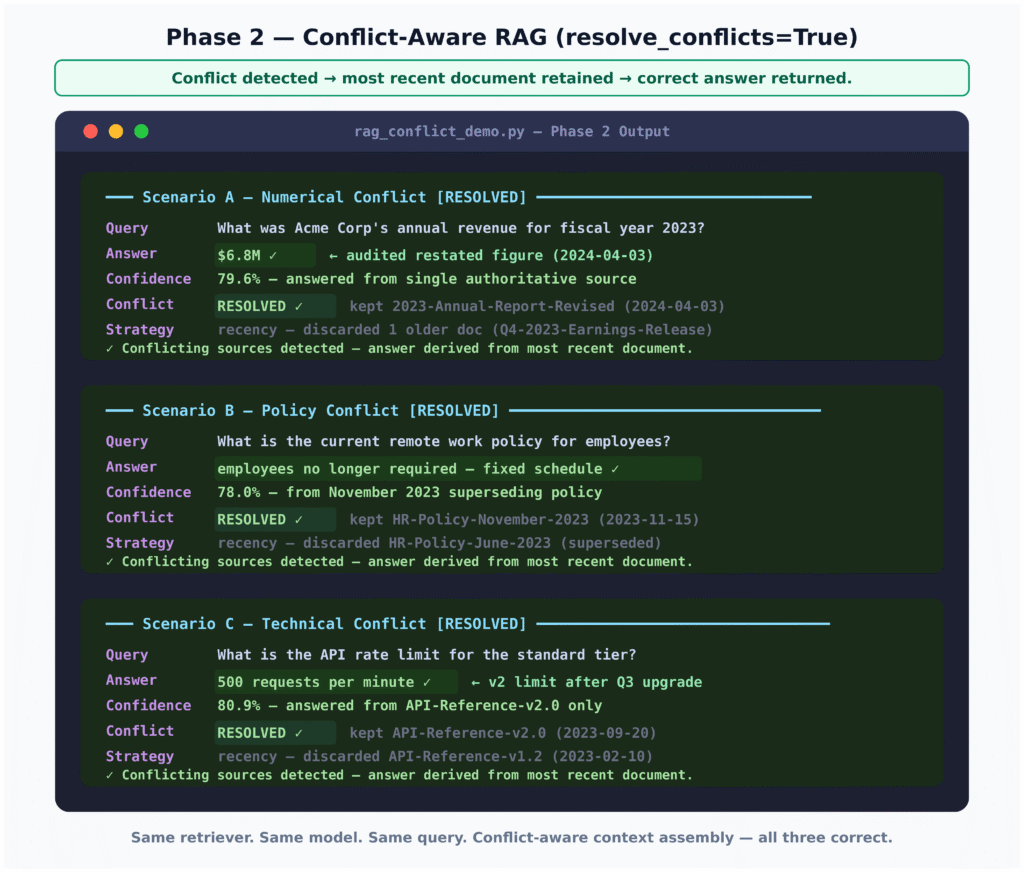
Designing Conflict-Aware RAG: Re-ranking, Clustering, and De-duplication
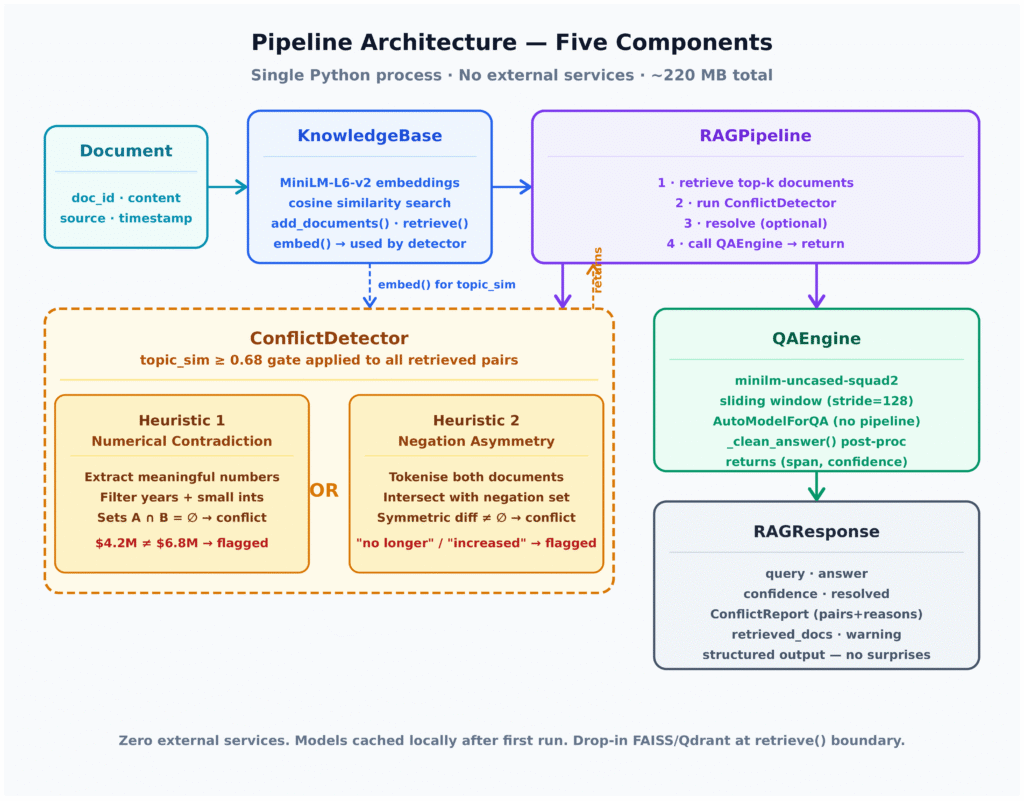
Fixing conflicting context RAG behaviour starts before the prompt ever reaches the model. First, re-ranking should incorporate metadata such as document date, version, and source authority, not just similarity score, so that restatements, policy updates, and newer API docs outrank predecessors. Second, clustering highly similar passages lets you collapse near-duplicates and detect contradictory claims within a cluster. A conflict detection layer can then choose a single, consistent passage—often the latest or most authoritative—or explicitly surface the inconsistency. Third, aggressive de-duplication and limiting context to fewer but higher-quality passages reduce the chance that mutually incompatible evidence shares one window. Architecturally, inserting a modular conflict detector between retrieval and QA turns a monolithic LLM retrieval pipeline into one that can flag, resolve, or escalate disputes, rather than silently picking a side. The experiment’s conflict-aware phase shows that with the same retriever and model, careful context assembly alone can flip every answer from wrong to correct.
Practical Playbook for Product and Data Teams
For builders, the implications are direct. Evaluation suites should include queries where the knowledge base intentionally contains conflicting, versioned documents, and success is measured by whether the system surfaces the latest, authoritative answer—or admits uncertainty. Prompt patterns can instruct models to report when multiple answers appear valid, summarise disagreements, or ask for clarification instead of forcing a single value. Logging must go beyond retrieval scores: store which documents entered the context window, whether conflicts were detected, and how they were resolved. For consumer-facing assistants tied to personal or corporate knowledge bases, this is a trust issue. Users cannot see the hidden conflict, only the confident output. By integrating conflict-aware re-ranking, clustering, and monitoring into the LLM retrieval pipeline, teams can significantly improve RAG system errors, reduce silent failures, and deliver AI products that not only sound authoritative but are far more likely to be correct.