Why Independent AI Code Generation Benchmarks Matter
AI code generation benchmarks are neutral, repeatable measurements of how AI-assisted development changes real engineering output, expressed through consistent metrics rather than vendor marketing claims or self-reported surveys. As AI coding assistants spread through engineering teams, most productivity stories still come from internal trials, hand-picked case studies, and opaque developer productivity metrics. Vendors often highlight uplift percentages without revealing baselines, sample sizes, or how they defined "productivity" in the first place. For leaders deciding between tools from OpenAI, Microsoft, Google, Meta, and Anthropic, this creates a credibility gap: budget decisions rest on evidence they cannot inspect. Independent benchmarks step into that gap by standardizing how coding tool comparison is done, measuring what ships to production instead of counting prompts or demos. The question is shifting from whether AI coding works in theory to which tools show consistent gains in production code.
Inside Navigara’s 500 OSS Performance Index
Navigara’s 500 OSS Performance Index is a live benchmark that tracks engineering output for Microsoft, Meta, OpenAI, Vercel, Google, and Cloudflare across open source projects. Rather than counting lines of code or raw commit numbers, it uses an Engineering Throughput Value (ETV) score that weighs structural complexity, the surface area a developer needed to understand, the feature’s position in the architecture, and whether a change fixes a defect. Navigara reports a 124.8% rise in average output over a 90-day rolling series, from 0.86 to 1.94 ETV per developer per month, and a sixfold spread between the highest and lowest performers. Output is split into three non-additive buckets—Growth, Maintenance, and Fixes—to reduce gaming. The scoring engine is deterministic and publicly documented, giving engineering leaders a transparent baseline for AI vendor performance and a consistent way to compare their own teams.
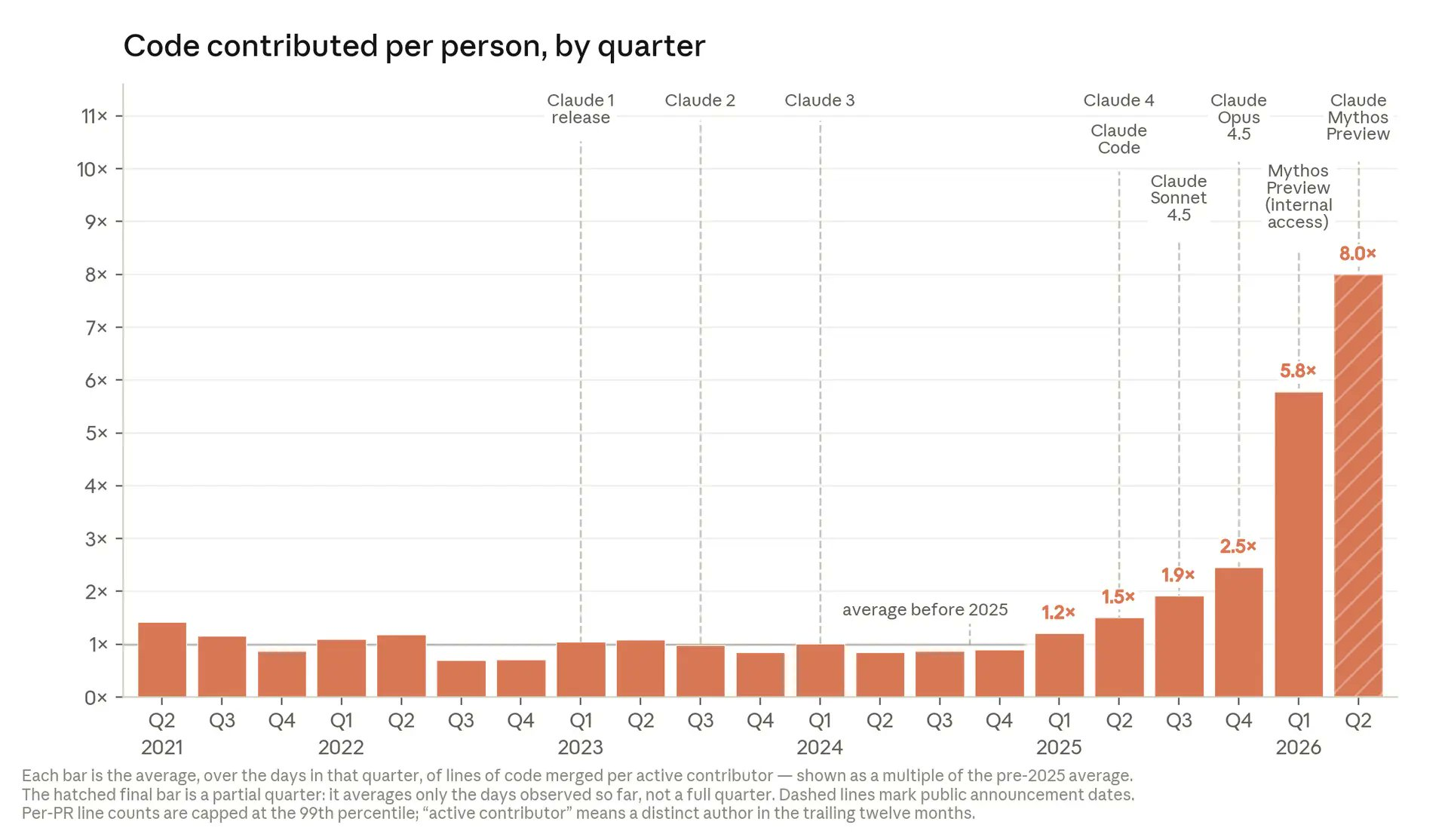
Anthropic’s 8x Code Output Claim and Its Limits
Anthropic has published internal numbers claiming that average lines of code merged per active contributor have reached 8x the pre-2025 baseline. The company links this curve tightly to its Claude coding model releases, with output stepping from 1.2x in early 2025 to 2.5x by late 2025, then to 5.8x in early 2026 and 8x in the current partial quarter. According to Anthropic, a majority of its code is now written by AI, and some engineers have stopped opening code editors, instead editing AI-generated drafts. These figures show how aggressive AI adoption can transform developer workflows, but they are still an internal benchmark: lines of code are capped by percentile rules, contributors are defined by a trailing twelve-month window, and the methodology is controlled by one company. For buyers, that raises questions about how transferable these gains are outside Anthropic’s stack and culture.
Bridging the Credibility Gap for Engineering Leaders
Engineering leaders face pressure to choose AI coding tools while defending large budgets to finance teams and boards. Many AI vendor performance claims still rely on controlled trials that do not resemble production conditions or on self-reported surveys that lack shared baselines. Navigara’s founder Jirka Bachel argues that "the market is full of productivity claims built on controlled trials that do not resemble production conditions" and that leaders need metrics based on what actually merges. Independent coding tool comparison frameworks like the 500 OSS Performance Index help by offering a public AI Spend Calculator that ties cost to ETV across Growth, Maintenance, and Fixes. Combined with internal data such as Anthropic’s 8x output figures, leaders can triangulate: compare neutral AI code generation benchmarks, scrutinize vendor methodologies, and run their own trials against transparent metrics, instead of relying on unverified marketing numbers.





