From Code Generation to Codebase Restructuring
AI coding tools have largely been evaluated on how well they generate snippets or solve isolated programming prompts. Scale Labs’ Refactoring Leaderboard marks a shift toward measuring agents on codebase restructuring instead of simple code completion. Refactoring demands a different skill set: understanding existing architecture, preserving behavior, and coordinating edits across multiple files. Rather than treating models as autocomplete engines, Scale Labs frames them as software engineers working inside real repositories. This leaderboard sits within SWE Atlas, a broader research suite that already assesses codebase comprehension and test writing. With the new benchmark, AI code refactoring is elevated to a first-class capability, highlighting how well agents can improve legacy systems without breaking them. For organizations evaluating coding agent benchmarks, this represents a more realistic way to compare tools that claim to handle complex engineering work.
What the Refactoring Leaderboard Actually Measures
The Refactoring Leaderboard focuses on whether AI agents can restructure production-style code while preserving existing behavior. Instead of one-off tasks, the benchmark evaluates how agents navigate large repositories, edit multiple files, and keep tests passing after significant structural changes. SWE Atlas Refactoring tasks require about twice as many lines of code changes and 1.7 times more file edits than SWE-Bench Pro, making them a higher-pressure test of multi-file software engineering. The benchmark covers four core types of codebase restructuring: decomposing monolithic implementations, strengthening weak interfaces with cleaner abstractions, extracting duplicated or misplaced logic into shared modules, and relocating code to sharpen module boundaries. Each attempt is graded both by whether tests pass and by rubric-based review of maintainability, artifact cleanup, and documentation quality. In effect, the leaderboard evaluates not just correctness but also engineering discipline in AI code refactoring.
Cleanup, Reliability, and the Gap Between Models
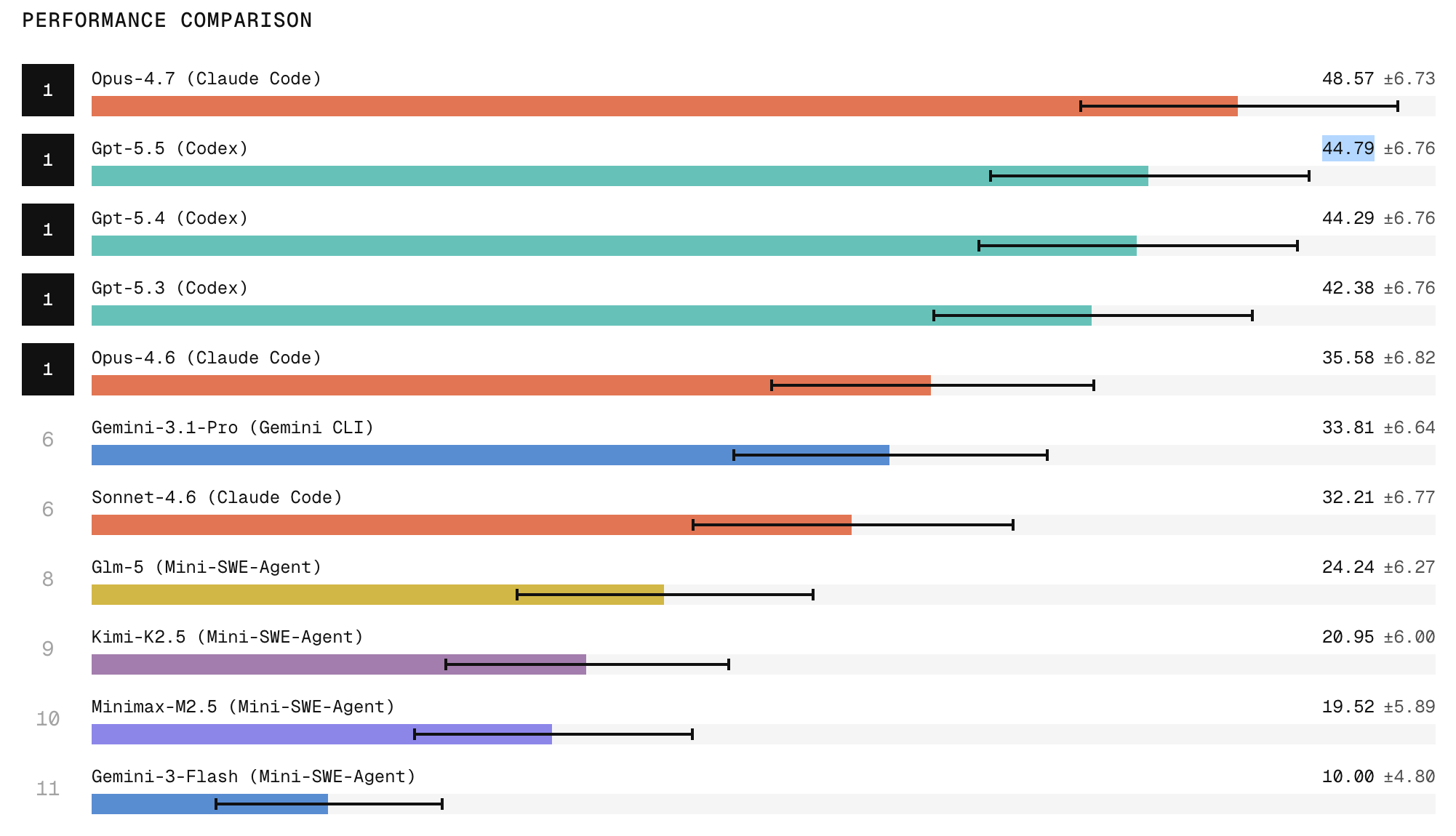
Scale Labs’ findings highlight that passing tests is not enough for trustworthy AI code refactoring. Models often achieve green test suites yet fail engineering-quality checks, leaving behind dead code, stale imports, duplicated implementations, outdated comments, or missed call sites. This cleanup problem becomes a key differentiator in coding agent benchmarks, separating agents that merely complete visible tasks from those that produce production-grade changes. Reliability is another central concern. When models attempt the same refactoring three times, they are two to three times more likely to succeed once than in all three runs, underscoring inconsistent behavior. Frontier closed models lead performance, with Claude Code with Opus 4.7 ranking first and ChatGPT 5.5 in second place, while open-weight systems lag on tasks demanding broad repository exploration and careful behavior preservation. The leaderboard thus exposes both capability and repeatability gaps that still limit autonomous use.
Implications for Legacy Code Modernization
For teams tackling legacy code modernization, the Refactoring Leaderboard offers a new lens for selecting AI tools. Refactoring-heavy projects require agents that can safely restructure large systems, not just generate fresh code. By benchmarking agents on decomposing monoliths, improving interfaces, and consolidating duplicate logic, Scale Labs provides a standardized way to compare solutions for codebase restructuring tasks. The results suggest that top frontier models can deliver strong refactors but still struggle with consistency and thorough cleanup, limiting their suitability for fully autonomous workflows. Instead, they are best viewed as high-powered assistants that augment human engineers on complex migrations and architecture improvements. As SWE Atlas positions AI agents more like software engineers than code generators, this leaderboard gives organizations clearer evidence about which tools handle real-world refactoring challenges and where human oversight remains indispensable.