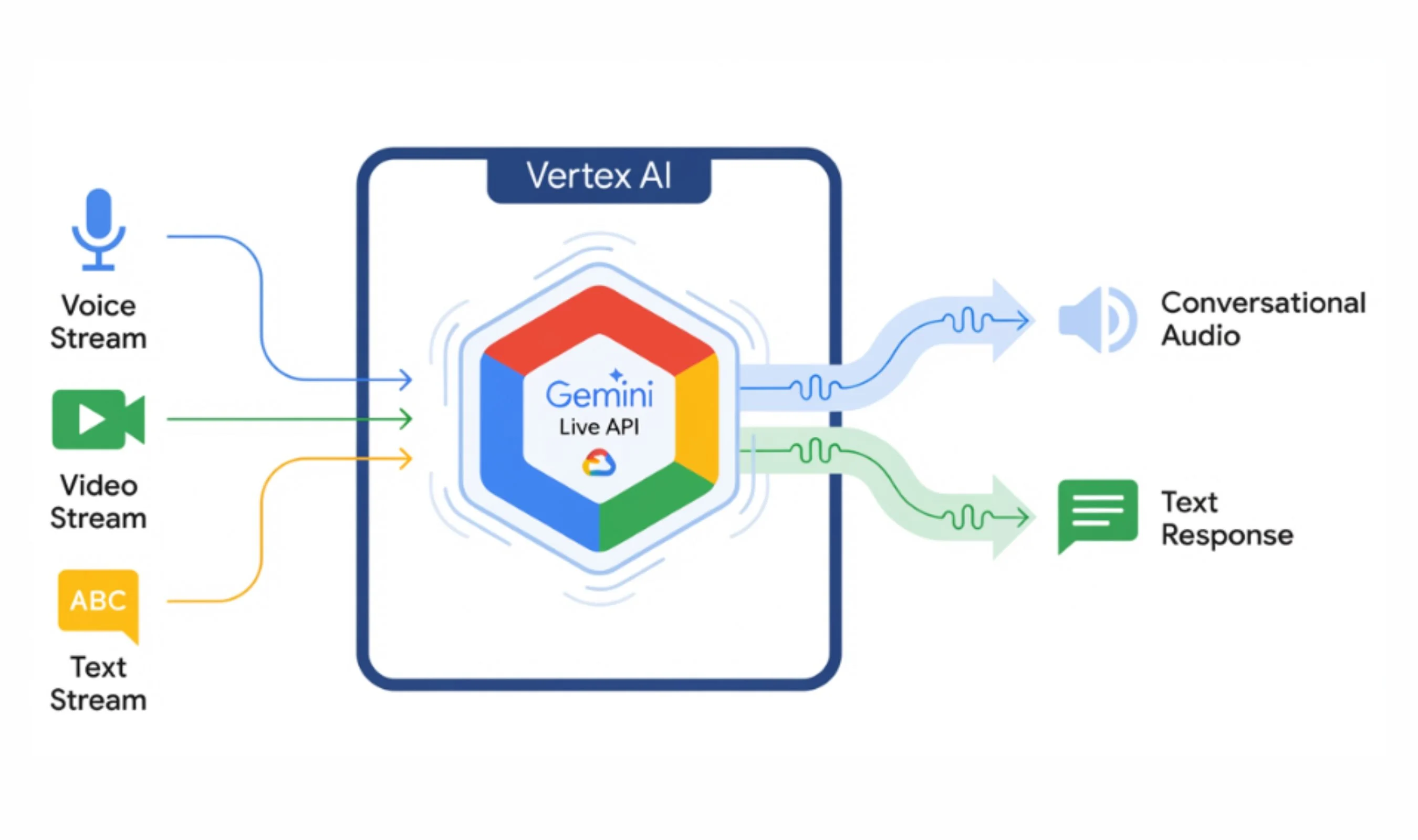
Seven Secret Gemini Live Models Come to Light
A hidden model selector in the Google app has exposed a quietly expanding universe of Gemini Live models. Buried behind a server-side flag, the menu lists seven distinct options: Default, A2A_Rev25_RC2, A2A_Rev25_RC2_Thinking, A2A_Rev23_P13n, A2A_Nitrogen_Rev23, A2A_Capybara, A2A_Capybara_Exp, and A2A_Native_Input. The “A2A” label is widely interpreted as Audio-to-Audio, indicating systems that process speech directly instead of relying on intermediate text. Two models, tagged Rev25_RC2, appeared overnight on May 8, signaling they are close to production rather than early prototypes. Early tests show each model responds differently, with some able to access live weather data via the user’s location while others cannot. Because this selector is controlled from Google’s servers, the company can dynamically swap or add models, a setup that practically begs for a high-profile reveal at its upcoming I/O conference.
Inside the Thinking Variant and Personalized Gemini Live
Among the new Gemini Live models, one stands out: A2A_Rev25_RC2_Thinking, an explicit thinking variant designed for deeper reasoning. Test prompts show this model behaves differently from the default Gemini Live system, hinting at stepped or deliberative reasoning pipelines similar to other advanced reasoning AI approaches. Another notable entry, A2A_Rev23_P13n, appears tailored for personalization. Instead of assuming a time zone when asked for the current time, it first clarifies the user’s location. More significantly, it remembers personal details shared earlier and weaves them naturally into later responses, something the current default Gemini Live reportedly avoids. The Capybara model is equally intriguing, identifying itself as “Gemini 3.1 Pro” rather than the usual Flash Live configuration. Taken together, these variants suggest Google is segmenting Gemini Live into specialized profiles for reasoning depth, personalization, and possibly premium performance tiers.
A Strategy to Match Advanced Reasoning Rivals
The appearance of a thinking variant inside Gemini Live signals how seriously Google is treating advanced reasoning AI as a competitive battleground. While the company has publicly highlighted speed-focused models for everyday chat, this hidden lineup points to a more nuanced strategy: mix ultra-fast, lightweight models with heavier, reflective systems that can tackle multi-step logic, proofs, and planning. The RC2 labels imply these models are nearing finalization, not just experimental sandboxes. Multi-model access within a single interface also mirrors a broader shift in the AI race, where vendors dynamically route user requests to different engines based on task complexity and cost. By quietly preparing Audio-to-Audio models that can reason and remember with more nuance, Google is positioning Gemini Live as a flexible front end that can compete directly with other AI platforms emphasizing chain-of-thought reasoning and long-horizon task handling.
Gemini Omni and the Push into Video Intelligence
The hidden Gemini Live models are only one piece of Google’s emerging AI stack. A Reddit user recently encountered “Gemini Omni,” described in-app as a new video model and apparently built on top of the Veo foundation. In tests, Omni generated complex scenes such as a professor writing a trigonometric proof on a chalkboard, demonstrating strong temporal and spatial reasoning even as it still exhibited familiar video glitches in a dinner scene. Attempts to recreate the notorious “Will Smith eating spaghetti” prompt were blocked by safety guardrails, underscoring a more conservative content policy. The model is resource-intensive: just two video generations reportedly consumed 86% of a user’s daily allowance under a Google AI Pro plan, aligning with new usage limits being rolled out for Gemini. Omni, coupled with Gemini Live’s model selector, shows Google preparing an ecosystem where audio, text, and video intelligence are tightly integrated.
Toward a Multi-Model Gemini Future
These discoveries point to a broader reshaping of Gemini as a multi-model, task-aware platform rather than a single monolithic AI. Backend infrastructure already supports switchable voice and Audio-to-Audio models, while labels like RC2 suggest Google is readying them for public exposure. On top of this, the newly announced Gemini Intelligence aims to automate workflows across apps and the web, with features such as Chrome auto-browse arriving soon. In that context, a thinking variant for complex reasoning and a personalization-focused model capable of memory make strategic sense: one handles intricate logic, the other maintains continuity across tasks and sessions. Combined with the video-centric Gemini Omni, Google appears intent on positioning Gemini as a unified layer that can listen, see, reason, remember, and act. The pre-announcement leaks simply reveal how close that strategy is to becoming a mainstream reality.