An Open AI Voice Benchmark with Alarming Results
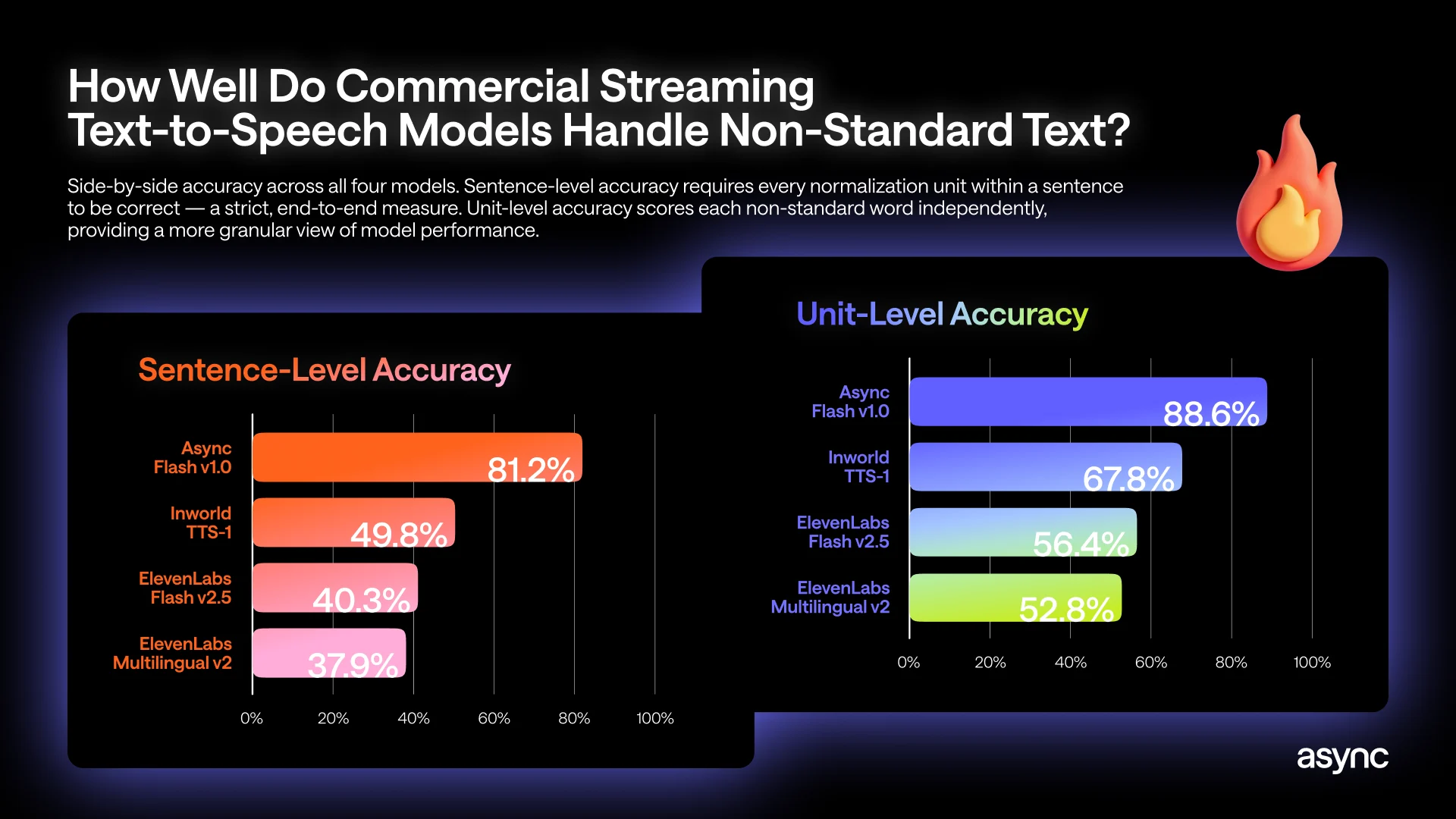
A new open AI voice benchmark from Async reveals a critical weakness in production-grade streaming TTS models: they struggle badly with structured text like numbers, dates, and prices. The test simulates real call center and assistant scenarios, where a voice agent must instantly turn raw text such as “$149.99 due on 03/31, reference #AA-4872” into natural speech, without any preprocessing layer cleaning it up first. Using each provider’s real-time streaming API, Async evaluated more than a thousand sentences containing over 2,200 non-standard tokens across 31 categories, from currencies and dates to phone numbers and identifiers. The results show that even leading streaming TTS models fail the majority of such sentences when judged at sentence level, where every number-like element must be read correctly. ElevenLabs Multilingual v2, for example, reaches only 37.9% sentence-level accuracy, meaning it misreads over 62% of these numerically rich sentences.
Why Streaming TTS Models Misread Text to Speech Numbers
The benchmark isolates a specific production challenge: streaming TTS models must start speaking within milliseconds of receiving text, with no chance for heavy normalization. In batch pipelines, a preprocessor can safely rewrite “$149.99” to a fully spelled-out phrase before audio generation. In live streaming, by contrast, the model must infer on the fly how to vocalize currencies, dates, times, and IDs while constrained by latency and limited context. Prosody compounds the difficulty: choosing between “March thirty-first” and “zero three slash three one” or deciding how to vocalize a long reference number requires knowing the sentence’s full structure, which may not yet be available. This tight coupling of timing, context window limits, and prosodic choices makes text to speech numbers and other non-standard tokens uniquely error-prone, even when overall pronunciation of ordinary words sounds impressively human-like.
Real-World Risks: From Mispriced Orders to Accessibility Failures
These accuracy gaps matter far beyond lab benchmarks. In a shopping or banking scenario, a streaming voice agent that misreads an amount or due date can confuse customers or trigger disputes, especially when confirmation messages combine prices, dates, and reference numbers in a single sentence. In healthcare or scheduling workflows, a misread appointment time or test result date can cause missed visits and follow-up failures. Navigation and logistics agents, meanwhile, rely on precise reading of house numbers, floor levels, and unit identifiers. For visually impaired users who depend on spoken interfaces as a primary information channel, systematic errors in reading prices, dates, currencies, and identifiers become an accessibility issue, not just a minor annoyance. Despite this, standard monitoring stacks often miss these problems because latency and audio quality look normal, and metrics like word error rate rarely distinguish between correct and incorrect readings of structured tokens.
Marketing Claims vs. AI Voice Benchmark Reality
The Async AI voice benchmark underscores a growing gap between vendor marketing and operational reality. Many providers promote their streaming TTS models and AI call center voice solutions as near-human or studio-quality, pointing to natural timbre, low latency, and generic word error rate improvements. Yet the benchmark indicates that when sentences contain the structured content that dominates support, finance, and customer-service traffic, sentence-level accuracy can fall below 40%. This means most multi-number utterances are wrong in practice, even if they sound fluent and expressive. Because current quality gates prioritize smoothness and response time over semantic correctness, such failures often remain invisible to teams deploying voice agents. The findings suggest that evaluating voice agent accuracy now requires public, task-specific benchmarks that stress-test dates, currencies, and identifiers, rather than relying solely on broad speech metrics or polished demo clips.
Mitigating the Number Problem in Voice Agents
To make streaming TTS fit for high-stakes use cases, teams will need targeted mitigations rather than just larger models. One path is hybrid architectures: a lightweight normalization layer that operates under tight latency budgets, pre-tagging or rewriting only high-risk elements such as amounts, dates, and reference numbers before the text reaches the speech model. Another approach is to embed specialized number-reading modules that treat currencies, timestamps, and identifiers as structured data rather than plain text, ensuring consistent pronunciations across channels. Crucially, organizations deploying AI call center voice systems should adopt rigorous public benchmarks for voice agent accuracy that reflect their real traffic mix, including dense clusters of non-standard tokens. By holding streaming TTS models accountable against open, domain-specific tests, the industry can move beyond surface-level fluency and toward reliable handling of the numbers that drive transactions, schedules, and accessibility.
