What Gemini 3.5 Live Translate Is and Why It Matters
Gemini 3.5 Live Translate is Google’s new real-time voice translation system that continuously processes speech and produces near-instant multilingual speech-to-speech output in over 70 languages, aiming to remove the long pauses and turn-taking delays that have defined earlier translation tools and make cross-language conversations feel closer to natural, human dialogue. Instead of waiting for a speaker to finish a sentence, the model listens and responds on the fly, staying just a few seconds behind. This timing shift is the core innovation: it changes multilingual speech translation from a stop‑start experience into a flowing exchange. With 70 languages support and automatic language detection, the tool reframes translation as a shared, live conversation rather than a series of sequential monologues, setting the stage for more spontaneous meetings, calls, and casual chats across language barriers.

Continuous Processing and the ‘Speed Over Certainty’ Trade-Off
Most real-time voice translation has worked like a walkie-talkie: you speak, stop, then wait for the system to respond. Gemini 3.5 Live Translate changes that by processing audio continuously and outputting translated speech while the speaker is still talking. Google describes the model as staying “just a few seconds behind the speaker” throughout a session, a small but persistent delay the company treats as a design constraint rather than a solved problem. The system favors speed, then corrects as more context arrives, instead of aiming for perfect certainty before speaking. That approach mirrors human simultaneous interpreters, who often commit early and adjust mid-sentence. It does not eliminate latency, but it compresses it enough to reduce awkward pauses and overlapping speech. The result is multilingual communication that feels more like natural dialogue and less like taking turns with a machine in the middle.
From Google Translate Upgrade to a Platform for Multilingual Speech
Gemini 3.5 Live Translate is framed not as a single Google Translate upgrade but as a platform for multilingual speech translation across products. It powers speech-to-speech translation in the Google Translate app on Android and iOS, integrates through the Gemini Live API and Google AI Studio for developers, and is entering preview in Google Meet for enterprise video calls. According to Google, the same model now supports more than 2,000 language combinations in a single Meet session, removing the older limitation where translations had to route through English and were restricted to five languages. That architectural shift lets participants speak and hear translations in their own languages without relying on a shared lingua franca. For developers, this opens the door to in-app real-time voice translation in customer support, marketplaces, or social audio products, all built on one underlying system.
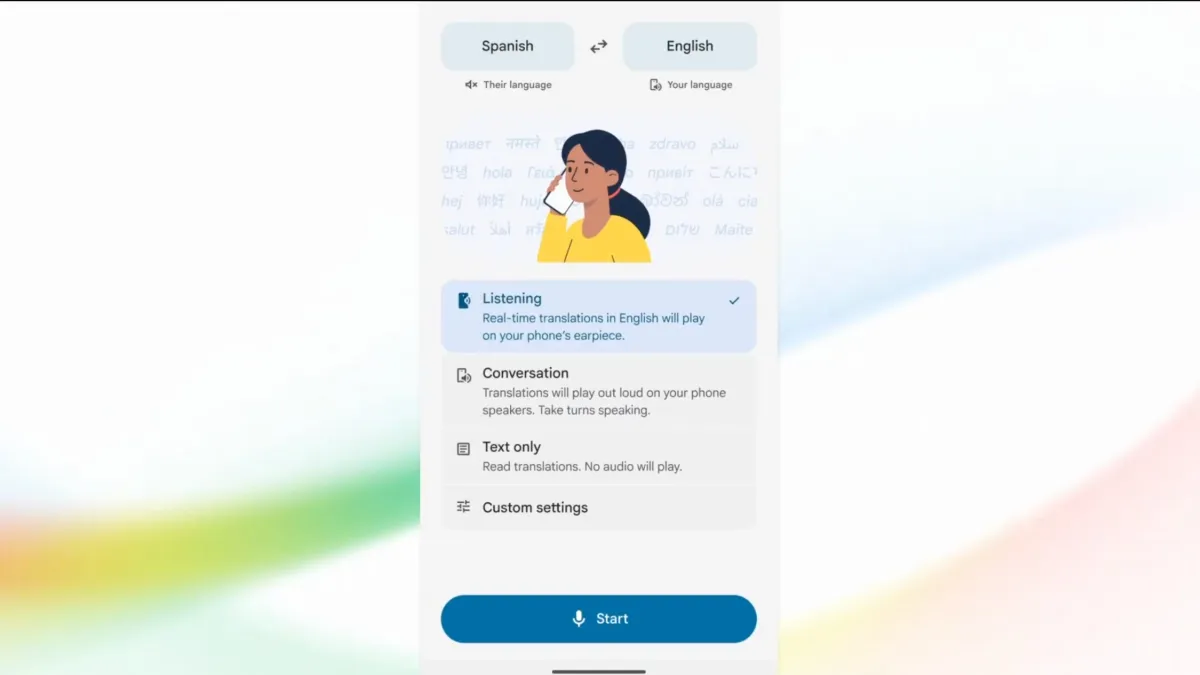
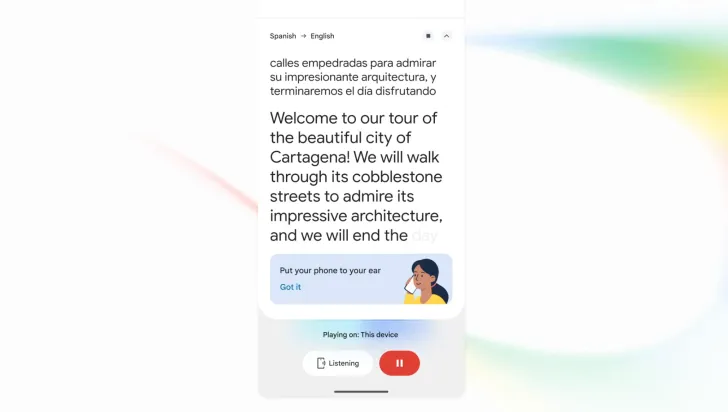
Listening Mode and Audio Watermarking: New Ways to Use and Trust AI Speech
Beyond the core model, Google is adding features that change how people use and verify AI-generated audio. On Android, a new listening mode sends translated speech through the phone’s earpiece so users can hold it to their ear like a call instead of broadcasting translations on speaker or relying on headphones. This makes real-time voice translation more discreet in public spaces and more practical for on-the-go use. The model also preserves the original speaker’s tone, pacing, and pitch, helping translations sound less robotic and closer to a human voice. At the same time, every AI-generated audio clip includes SynthID watermarking embedded into the sound. While inaudible to listeners, this watermark gives platforms and investigators a way to detect that speech was produced by an AI system, an important safeguard as synthetic audio becomes harder to distinguish from human voices.
What Near-Instant Multilingual Conversations Could Change Next
The impact of Gemini 3.5 Live Translate will depend on how well it works in messy, high-pressure situations. Google points to pilots with Grab, where drivers and riders make more than 10 million voice calls per month in noisy conditions and across complex languages such as Thai, Vietnamese, Bahasa Indonesia, and Tagalog. If continuous real-time voice translation proves reliable there, it strengthens the case that the system is ready for large-scale deployments in transport, education, healthcare, and cross-border collaboration. Google already processes over a trillion words per month across its translation products, so even modest improvements in latency and naturalness can reshape millions of daily interactions. The model’s ability to auto-detect languages and handle speech-to-speech translation across 70-plus languages hints at a future where multilingual meetings, classes, and support calls no longer need a shared language at all.