Cursor Targets Cost-Per-Task Efficiency With Composer 2.5
Cursor’s new Composer 2.5 is designed to compete not by sheer size, but by dramatically better AI coding cost efficiency. The company claims up to 10x improvement in cost-effectiveness versus earlier Composer versions, positioning the model as an affordable coding AI for developers who run extended, agent-style workflows. Standard pricing for Composer 2.5 starts at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster default variant priced at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. Cursor is explicitly aiming at buyers who evaluate tools on total cost per long-running task, not just headline benchmark scores. After losing momentum to premium assistants like Claude, the company is betting that predictable, low per-token pricing combined with agent-style reliability can bring developers back into its ecosystem.
Built on Kimi K2.5, Upgraded With Heavy Post-Training
Composer 2.5 keeps Moonshot’s Kimi K2.5 as its base, signaling a strategic bet on tuning and reinforcement learning instead of chasing new foundation models. Cursor reports a 25x increase in synthetic task training, alongside tougher reinforcement-learning environments and new learning methods that better stress-test long chains of instructions before they reach real repositories. A key innovation is targeted reinforcement learning with localized textual feedback: short hints are injected exactly where the model’s trajectory goes off course, helping solve the credit-assignment problem in long agent runs. This is paired with improved behavioral calibration, so the model’s communication style and effort level are better aligned with developer expectations. In practical terms, Cursor is trying to make Composer 2.5 not just smarter, but more consistent at multi-step refactors, tool calls, and cross-file edits—areas where earlier Composer releases and rival agents often falter during long sessions.

Benchmark Gains Narrow the Gap With Claude and GPT Rivals
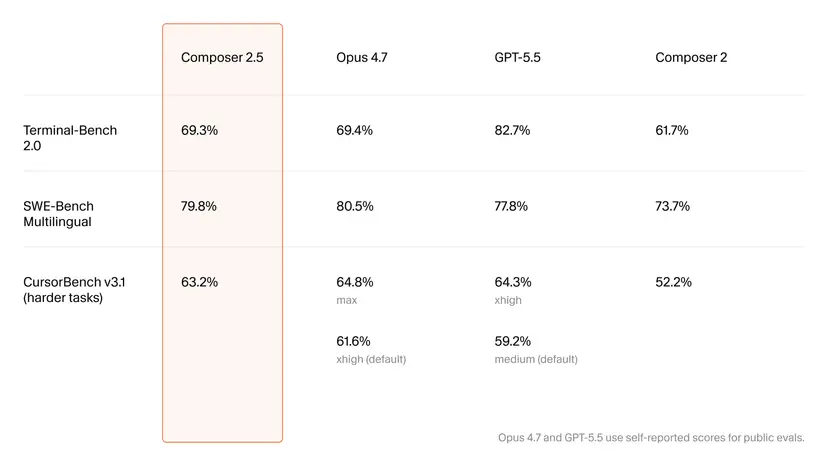
On paper, Composer 2.5 delivers tangible improvements over Composer 2 and closes in on premium models like Claude Opus and GPT-5.5. Cursor reports that Terminal-Bench 2.0 scores climbed from 61.7% to 69.3%, while its internal CursorBench v3.1 jumped from 52.2% to 63.2%. The model also posted 79.8% on SWE-Bench Multilingual, edging past GPT-5.5 by a small margin according to one analysis. While Composer 2.5 still trails Opus 4.7 and GPT-5.5 on several benchmarks overall, the gap is narrowing at a fraction of their cost, strengthening its position as a Claude Opus alternative for code generation and agent tasks. Cursor emphasizes that these benchmarks target code correctness and end-to-end agent completion, offering a more task-oriented comparison than generic “IQ” scores—even as the company acknowledges that real-world repository work remains the ultimate test.
Aggressive Pricing Strategy Challenges Premium Coding Assistants
Composer 2.5’s most disruptive lever is pricing. Cursor has held its standard rate at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, while the faster default tier costs USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. By contrast, high-end models like Opus 4.7 and GPT-5.5 typically command significantly higher per-token fees, especially in enterprise workflows. Cursor’s aim is to undercut these rivals on cost-per-task for extended coding sessions, particularly multi-file refactors, long debugging cycles, and continuous agent runs. For teams that keep assistants active for hours inside large repositories, small per-token differences compound quickly. Cursor is betting that developers will accept slightly lower headline scores if Composer 2.5 delivers comparable practical output at a fraction of the spend.
From Benchmarks to Real Repos: Can Composer 2.5 Win Back Share?
Despite strong numbers, Cursor acknowledges that benchmarks alone will not reverse its recent market share loss to Claude and other premium tools. Developers care most about how reliably a model modifies real repositories, maintains style consistency, and avoids context drift during multi-hour sessions. Early community feedback is mixed: some users praise Composer 2.5’s stronger long-running performance and more accurate tool calls, while others note occasional mode confusion, where the agent abruptly stops or treats ongoing work as a simple Q&A. This underscores the tension between lab gains and production reality. Still, Cursor’s rapid release cadence, collaboration with SpaceXAI on a larger model, and clear focus on AI coding cost efficiency suggest a coherent strategy. If Composer 2.5 can translate its reinforcement learning upgrades into smoother, end-to-end coding workflows, it could become the default affordable coding AI for teams wary of premium price tags.