
Long-Running Task Failures Expose Limits of AI Coding Agents
AI coding agents are marketed as tireless coworkers that can autonomously execute complex, multi-step workflows. New research from Microsoft challenges that narrative. In the DELEGATE-52 benchmark, which simulates long-running professional tasks across 52 domains, even frontier models degrade documents significantly over time. After 20 delegated interactions, leading systems such as Gemini, Claude, and GPT lose on average about a quarter of document content, with the overall model average closer to half. The researchers set a readiness bar of 98 percent quality after 20 steps; only Python programming met that threshold, while 80 percent of simulated conditions saw severe corruption. For AI coding agents, this highlights a key limitation: they may handle short coding prompts well, but extended, stateful workflows—like iterative refactors or large feature branches—remain brittle. The hype around autonomous agents obscures how quickly accumulated errors can undermine real-world software development.
Faster Code, Slower Understanding: The New Oversight Gap
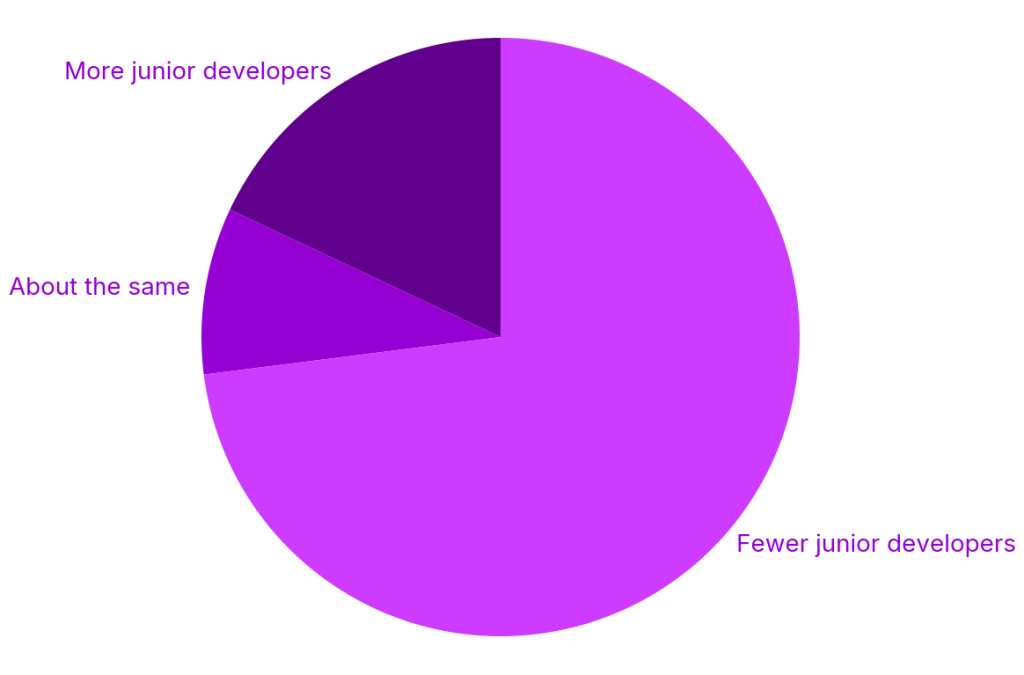
AI coding tools have dramatically accelerated code production, especially for less experienced developers, but they have not sped up code comprehension. Industry research cited by Octopus Deploy shows juniors completing tasks up to 55% faster with AI, while 73% of organizations have cut junior hiring. JetBrains’ 2026 survey reports rapid adoption of assistants like Claude Code, particularly among professional developers. This accelerates a structural shift: “seniors with AI” are increasingly expected to replace entire entry-level cohorts. The result is an oversight gap. Juniors lean heavily on AI-generated solutions yet often cannot explain the underlying logic or subtle failure modes. Senior reviewers, meanwhile, must validate more code in less time, much of it produced by tools they may not fully trust or use themselves. The gap between AI code generation speed and human verification capacity is at the heart of emerging concerns about AI code generation reliability.

Debugging With AI Tools and the Rise of the ‘Expert Beginner’
Engineering leaders are now encountering a new kind of developer: one who ships clean, well-tested AI-assisted code—but cannot debug it. The article that popularized the “expert beginner” warned about stagnation rooted in ego; today’s version is different. These developers are conscientious and fast, yet lack deep understanding of concurrency, performance, and edge cases. When a subtle timing bug appears only under rare conditions, they struggle to diagnose it because the agent wrote most of the logic. Debugging with AI tools can help, but it also tempts teams to treat the model as both author and reviewer, weakening human diagnostic instincts. Seniors who avoid AI entirely are also at risk, because they lose touch with patterns introduced by automated tools. This dynamic is driving developer skill erosion: less practice in reasoning from first principles, fewer opportunities to learn from mistakes, and a growing dependence on opaque agent behavior.
Refactoring Leaderboards Reveal Real-World AI Coding Agents Limitations
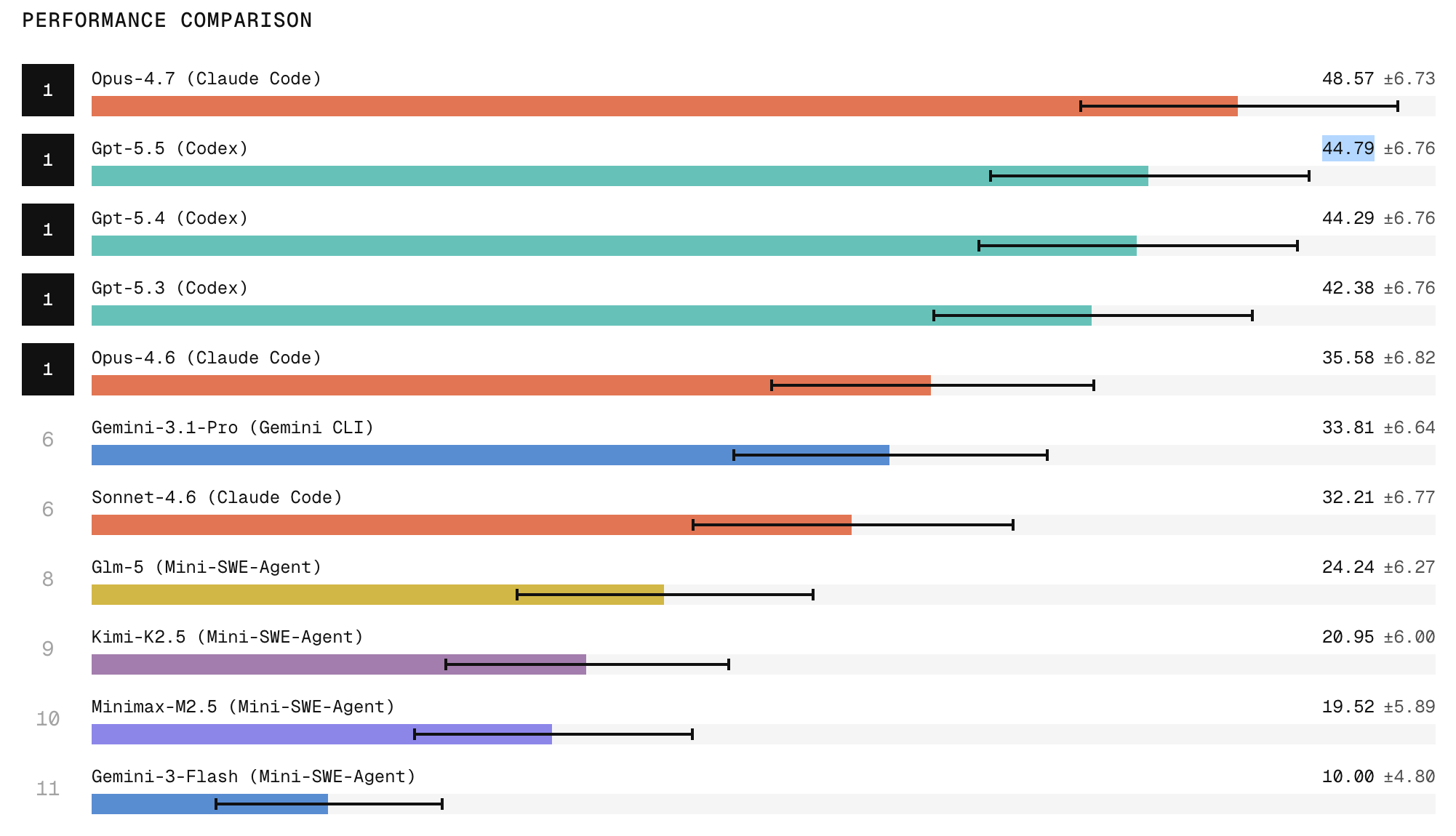
Scale Labs’ SWE Atlas Refactoring Leaderboard provides a clearer view of how AI agents handle production-style work. Unlike toy problems, these benchmarks require agents to restructure real repositories, modify multiple files, preserve existing behavior, and clean up stale artifacts. Refactoring tasks demand roughly twice as many lines of code changes and 1.7 times more file edits than earlier SWE-Bench Pro tasks, making them a tougher proxy for realistic software engineering. Claude Code with Opus currently tops the leaderboard, with ChatGPT close behind, but the results still show wide variability and fragile behavior preservation. Open-weight models, in particular, lag on broad repository exploration and structural edits. The leaderboard underscores that long-running, multi-file refactors are still hard for agents: they may pass tests yet leave subtle design regressions or incomplete cleanups. For teams, this reinforces the need for careful code review and architectural oversight whenever AI proposes sweeping changes.
Trust, Code Review, and the Future of AI-Assisted Development
Despite rapid adoption in languages like C++ and Python, developer trust in AI-generated code remains low, especially for tasks that go beyond isolated snippets. The combination of long-running task failures, brittle refactors, and shallow understanding among AI-reliant developers raises serious code review concerns. Reviewers must now ask not only “Does this work?” but also “Who actually understands this logic?” The safest path forward treats AI coding agents as accelerators, not autonomous engineers: they draft code, propose refactors, and surface test ideas, while humans retain responsibility for architecture, debugging, and final decisions. Organizations may need to redesign career paths and training to rebuild debugging skills and domain knowledge, particularly for juniors who are growing up with agents in the loop. Until benchmarks consistently show robust performance on complex, long-lived workflows, AI coding tools will remain powerful but unreliable collaborators rather than dependable replacements for human engineers.