What the Claude Opus 4.8 Benchmark Win Really Means
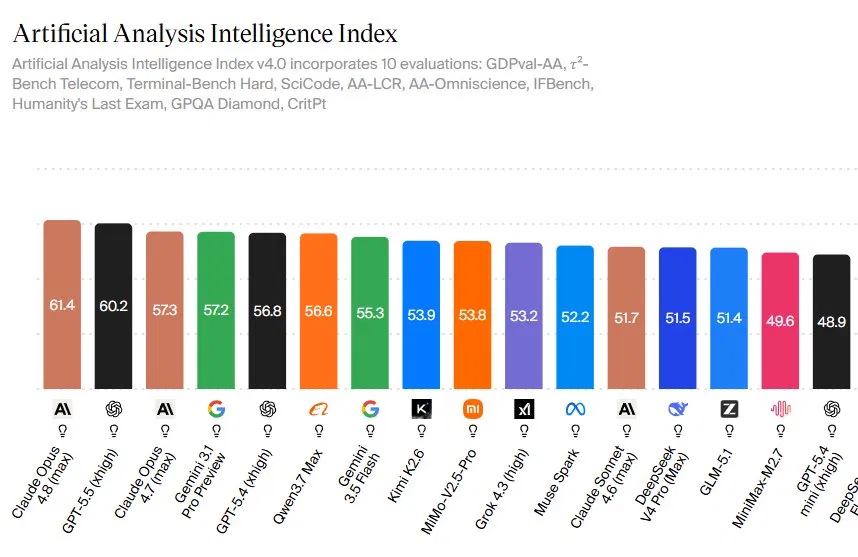
Claude Opus 4.8 benchmark results describe Anthropic’s newest flagship AI model, which tops independent capability indices and real‑world task evaluations through higher scores in reasoning, coding, and agentic work compared with both its predecessor and rival systems such as GPT‑5.5. Artificial Analysis reports that Opus 4.8 now leads the Artificial Analysis Intelligence Index v4.0 with a score of 61.4, ahead of GPT‑5.5’s 60.2 and Claude Opus 4.7’s 57.3. The index blends ten evaluations, from τ²‑Bench Telecom and Terminal‑Bench Hard to SciCode and GPQA Diamond, to give a broad AI model performance comparison. The 1.2‑point lead over GPT‑5.5 looks small, but it is built from consistent advantages across the basket rather than a single outlier test, suggesting the model’s gains generalize across coding, scientific reasoning, and complex multi‑step workflows.

Inside the Artificial Analysis Intelligence Index
The Artificial Analysis Intelligence Index aggregates ten challenging benchmarks into a single score, giving buyers and builders a quick read on general capability. For Opus 4.8, its 61.4 composite reflects strong showings across GDPval‑AA, τ²‑Bench Telecom, Terminal‑Bench Hard, SciCode, AA‑LCR, AA‑Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond, and CritPt. According to Artificial Analysis, “Claude Opus 4.8 leads the Artificial Analysis Intelligence Index v4.0 with a score of 61.4 — a clear margin above GPT‑5.5’s 60.2 and Claude Opus 4.7’s 57.3.” That lead is mirrored in Anthropic’s own data: Opus 4.8 scores 69.2% on SWE‑Bench Pro, well above GPT‑5.5’s 58.6%, and reaches 57.9% with tools on Humanity’s Last Exam, again ahead of rivals. These gains point to real progress in reasoning depth, long‑horizon planning, and tool‑using behavior.
GDPval-AA: From Benchmarks to Real-World Work
GDPval‑AA is the clearest link between benchmark charts and day‑to‑day enterprise use. Built by Artificial Analysis using its open‑source Stirrup harness, it measures how well agentic models complete economically valuable tasks using web and shell access across 44 occupations and 9 industries. On this test, Claude Opus 4.8 takes a commanding lead with an Elo score of 1890, 121 points ahead of GPT‑5.5 and 137 points above Opus 4.7. That translates to an implied win rate of about 67% in head‑to‑head matches against GPT‑5.5 at its strongest setting. At the same time, efficiency results are mixed: Opus 4.8 finishes tasks with 15% fewer turns and 35% fewer output tokens than Opus 4.7, but still uses around 30% more turns than GPT‑5.5, which may matter where interaction cost and latency are tightly managed.
Reasoning, Coding, and Autonomy: Where Opus 4.8 Pulls Ahead
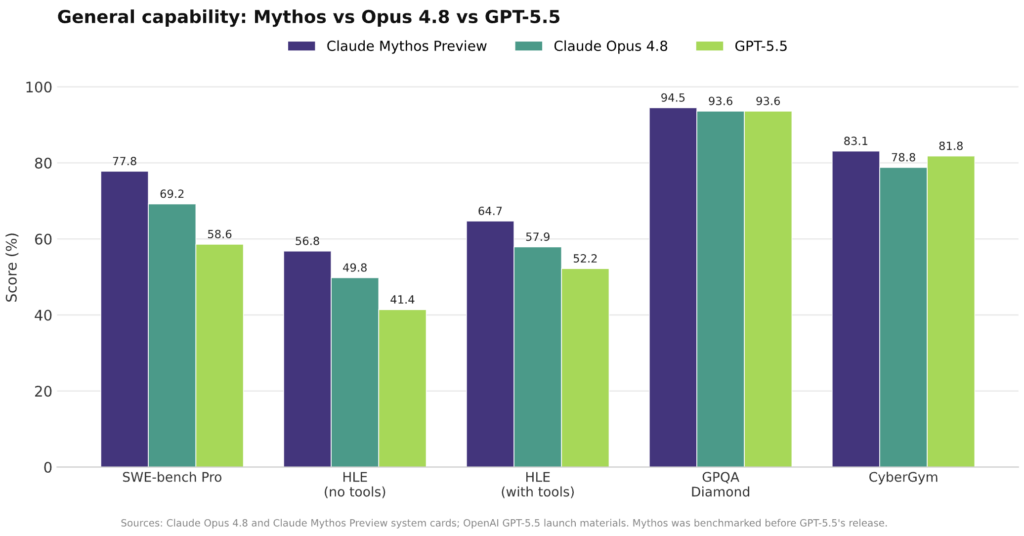
Beyond a single headline score, the Claude Opus 4.8 benchmark picture suggests a model tuned for autonomous, long‑running work. Anthropic’s evaluations show Opus 4.8 at 69.2% on SWE‑Bench Pro for agentic coding, up from 64.3% on Opus 4.7 and far ahead of GPT‑5.5’s 58.6 and Gemini 3.1 Pro’s 54.2. On Humanity’s Last Exam it reaches 49.8% without tools and 57.9% with tools, leading all three rivals on multidisciplinary reasoning. For agentic computer use, Opus 4.8 hits 83.4% on OSWorld‑Verified, a small gain on Opus 4.7 and a clear edge over GPT‑5.5 and Gemini 3.1 Pro. The main caveat is terminal‑heavy work: GPT‑5.5 still tops Terminal‑Bench 2.1 at 78.2%, while Opus 4.8 scores 74.6. Overall, the results indicate a model built to plan, call tools, and work across complex software and knowledge tasks with minimal supervision.
Market Impact and the Road Ahead for Frontier Models
For buyers comparing GPT‑5.5 vs Claude Opus, the new data shifts the conversation. Opus 4.8 not only edges ahead on the Artificial Analysis Intelligence Index but also ships at the same price as Opus 4.7: USD 5 input and USD 25 output per million tokens (approx. RM23 and RM115). Anthropic is also adding a Fast Mode for Opus 4.8, running the same model at about 2.5x speed at one‑third of the previous cost tier, with access via Claude Code’s /fast command and an API waitlist. At the top end, Anthropic’s Mythos Preview still appears stronger on the hardest software and cyber tasks, but the general‑intelligence gap over Opus 4.8 looks modest and uneven. In practice, Opus 4.8’s benchmark leadership, paired with safety‑oriented positioning, signals that capability and alignment work can progress together instead of pulling in opposite directions.





