AI co-scientists meet the wet lab trust gap
AI co-scientists in the lab are software systems that combine language models, experimental data, and automation tools to help scientists design, run, and interpret wet‑lab experiments while keeping humans in charge of decisions and validation. For all the hype, these tools are barely touching real lab work. According to the Pistoia Alliance, 54% of life science leaders see AI helping with regulatory submissions and reporting, but only 1% report value in the wet lab. That gap is as much about trust as capability. Bench scientists want life science AI tools that understand their data, instruments, and constraints, not only their documents. Vendors such as Sapio, Google, and Benchling are now making different architectural bets to rebuild confidence: some focus on large language model power, others on grounding every AI suggestion in lab data, automation, and human review.

Data-first versus model-first: diverging co-scientist designs
Behind the “AI co-scientists lab” marketing label sit very different systems. Google DeepMind’s Co-Scientist, for example, is a set of specialized agents that debate and rank hypotheses, emphasizing reasoning performance. OpenAI’s GPT-Rosalind slots into computational pipelines as a reasoning engine. In contrast, electronic lab notebook vendors such as Sapio Sciences start from lab data integration, then add language models on top. A Sapio survey of 150 bench scientists found 45% were already using public generative AI tools through personal accounts, frustrated by rigid ELNs and limited interpretation features. These users want conversational access to structured experiment data as much as fluent text. The core architectural split is clear: model‑first designs prioritize what the LLM can infer, while data‑first designs prioritize how tightly the AI is wired into samples, workflows, and results. That choice shapes how much scientists will trust recommendations at the bench.

Sapio and Potato: from interfaces to agents and connective tissue
Sapio’s approach shows how lab software is moving from passive records to active agents. Its Elain agent started as a natural language chat inside the ELN; with Anthropic’s Model Context Protocol, it became an agent that can pull files, query the ELN, and generate reports from a single instruction. Rob Brown, Sapio’s global VP and head of the scientific office, now uses voice and text instead of building complex queries by hand. At the infrastructure layer, companies such as Perceptic (profiled alongside Palantir veterans building “lights‑out” labs) aim to become the “connective tissue” that ties scattered AI tools to proprietary data. Parallel Bio and Ginkgo Bioworks push lab automation AI further, pairing agents with robotic workcells and autonomous fleets. In all these cases, the architecture aims to constrain hallucinations by binding language models to real systems, audit trails, and human checkpoints.

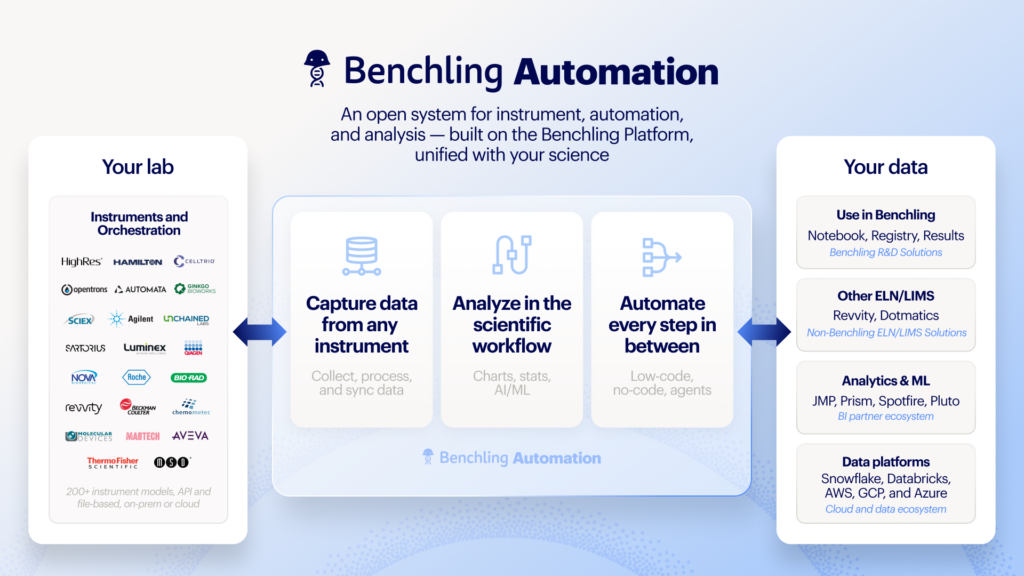
Benchling’s lab automation bet: ground AI in the physical world
Benchling is betting that AI trust architecture has to start where experiments happen: in the wet lab. Co‑founder Ashu Singhal argues that hypothesis generation is not the hard part; the difficult work is ordering reagents, creating notebook entries, running assays, and feeding results back into design. Benchling’s AI co‑scientist vision ties models directly to these steps through one‑click ordering with CRO partners and Benchling Automation for workcells. Singhal divides experiments into three buckets: repetitive assays to automate in‑house, work to send to external CROs, and one‑off experiments that will remain human‑run. The company is not trying to empty the lab; it is trying to ensure that when its AI proposes an experiment, it can also run it or trigger the right lab automation AI workflows. Grounding predictions in physical execution is Benchling’s answer to scientists who see AI as theoretical rather than practical.

Architecting trust: the boundary between models and lab reality
Across vendors, the most important design decision is where to draw the line between language models and real laboratory systems. Christian Baber of the Pistoia Alliance notes that pharma teams are converging on a rule: “Nothing goes directly from a transformer model to an agency. It has to be looked at first.” That human‑in‑the‑loop boundary is becoming part of AI trust architecture. Agents like Sapio’s Elain and Ginkgo’s EstiMate may orchestrate complex workflows, but a person still approves protocol changes, orders, or reports before they affect the lab. Benchling pushes that boundary close to instruments while keeping biologists responsible for experiment intent. Google’s and OpenAI’s model‑centric tools keep it further away, focused on analysis and design. How vendors architect this interface—what the AI can trigger, what data it can see, and where humans must intervene—will determine whether co‑scientists stay in slide decks or move onto the bench.






