From Model-Centric to Infrastructure-First Agentic AI
Enterprise AI teams are discovering that model upgrades alone cannot fix agentic AI performance bottlenecks. As autonomous agents move from experiments to production, three issues dominate: securing machine-speed automation, managing token cost reduction, and improving GPU utilization optimization. New open-source projects—OpenShell, OpenSquilla, and MemKV—are redefining AI agent infrastructure by attacking these problems at the stack level instead of the prompt level. Together they target enterprise AI security, context reuse, and recompute overhead, allowing organizations to run long-horizon, multi-step agents without runaway spend or unacceptable risk. Their approaches converge on a shared idea: agent-native infrastructure must be rebuilt around isolation, memory architecture, and context sharing, not retrofitted onto human-centric systems. For enterprises wary of vendor lock-in, these Apache-style, self-hostable components offer a way to keep control of the runtime while squeezing more value out of existing models and GPUs.
OpenShell: Sandboxed Runtime for Secure Enterprise AI Agents
OpenShell positions itself as a secure runtime foundation for autonomous agents in production environments, targeting enterprise AI security at the operating-system level. Built as part of Nvidia’s Agent Toolkit, it assumes that agents should never directly touch the host OS, network, or credentials. Instead, every agent—its harness and underlying model—runs in its own sandbox, while an external gateway manages credentials and session state for integrations like ServiceNow, Salesforce, or Workday. This design means the agent never holds keys, and any prompt injection or malicious behavior is contained within a tightly scoped blast radius. OpenShell enforces policy below the application layer using Linux kernel primitives such as seccomp, eBPF, and Landlock, creating a single horizontal enforcement plane rather than a patchwork of product-level controls. By offering this as Apache 2.0 open source, enterprises can adopt agent-native isolation without a proprietary lock-in to secure their AI agent infrastructure.
OpenSquilla: Intelligent Routing and Memory for Token Cost Reduction
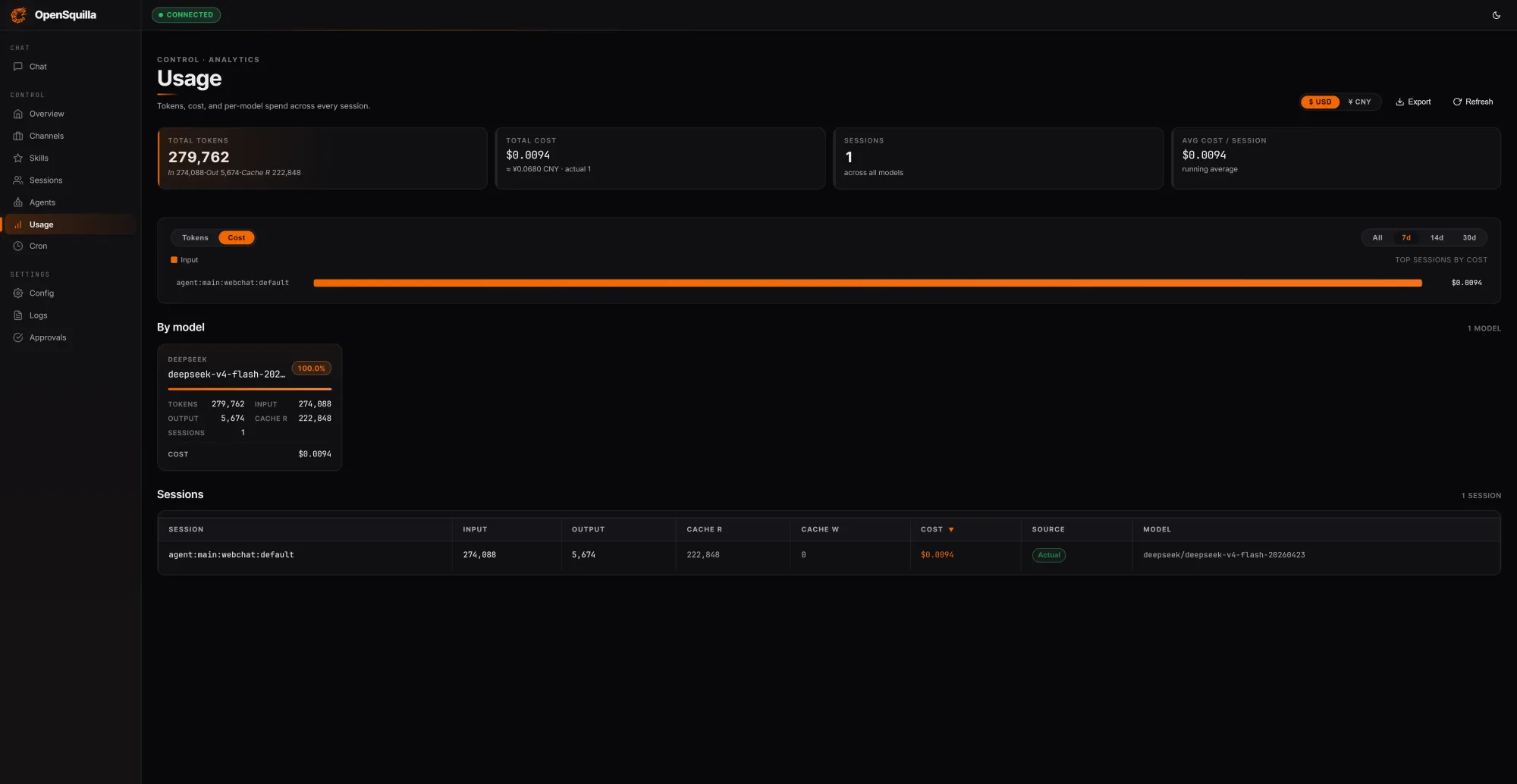
OpenSquilla focuses on token cost reduction for long-running, agentic AI performance workloads by rethinking how context and models are used over time. Its open-source, self-hostable runtime wraps an ML-based routing classifier around each request, scoring complexity using signals like message length, code presence, and semantic embeddings. Simple queries are automatically routed to cheaper models, and deep reasoning is disabled for trivial prompts so teams do not pay for extended chain-of-thought when it is unnecessary. Skills are loaded on demand instead of being stuffed into every context window. In a local test session, OpenSquilla processed 279,762 tokens for USD 0.0094 (approx. RM0.04), reusing 222,848 tokens—roughly 80% of input—from cache by sharing context across turns. Its coordinated routing and caching strategies reportedly cut token spend by 60–80% compared with single-model setups, with built-in quota hooks and per-call cost tracking to help prevent budget overruns in AI agent infrastructure.
MemKV: Ending the Recompute Tax with Shared Context Memory
MemKV, from MinIO, attacks a different bottleneck: wasted GPU cycles from repeated computation, or “recompute tax.” In modern agentic AI performance scenarios, multi-step reasoning often loses context because memory tiers close to the GPU cannot retain enough state. When that context disappears, GPUs must rerun prior work, dragging down throughput and inflating inference costs. MemKV acts as a context memory store—a native flash-based layer delivering persistent, shared context across GPU clusters over 800 GbE RDMA. MinIO reports that this architecture improves Time to First Token and Time Per Output Token, delivering over 95% better GPU utilization and roughly 50% lower cost per token on representative benchmarks. By enabling microsecond-level retrieval at petascale, MemKV keeps prior computations available instead of recomputing them, effectively turning context into a first-class infrastructure concern. For enterprises, this represents GPU utilization optimization without swapping out models or rewriting applications.

An Open-Source Blueprint for High-Performance Enterprise Agents
Viewed together, OpenShell, OpenSquilla, and MemKV sketch an emerging blueprint for AI agent infrastructure. OpenShell secures the runtime with sandboxed isolation and kernel-level policy, OpenSquilla governs how agents consume tokens through routing and multi-tier memory, and MemKV maximizes GPU utilization optimization by eliminating recompute tax. All three are open-source, giving enterprises flexibility to integrate them into existing stacks, avoid vendor lock-in, and mix providers at the model and hardware layers. Their collective impact signals a shift away from chasing marginal model gains toward infrastructure-level optimization of security, cost, and throughput. As analysts highlight the importance of token economics and context sharing, these projects demonstrate that the path to scalable agentic AI performance runs through redesigned runtimes, smarter memory hierarchies, and shared context stores—foundational components that let enterprises safely grant agents more autonomy while controlling spend and improving infrastructure efficiency.