The Shift from Bigger Models to Smarter Architectures
Enterprise AI strategy is quietly pivoting from chasing the largest possible models to deploying smaller, specialized ones that can run where work actually happens. Instead of relying on massive cloud-only systems, organizations are turning to small language models that can power AI agents directly in browsers and on local machines. This shift unlocks AI agent deployment without waiting for the next generation of frontier models or investing in heavyweight infrastructure. The emerging consensus: for many operational workflows, the bottleneck is not raw model size but orchestration, tool use, and integration with business systems. Lightweight AI systems that combine focused models with well-designed agent harnesses are proving sufficient for tasks like browser automation, document handling, and file management. As a result, enterprises are gaining faster implementation cycles, tighter data control, and more predictable costs while still achieving meaningful enterprise efficiency gains.
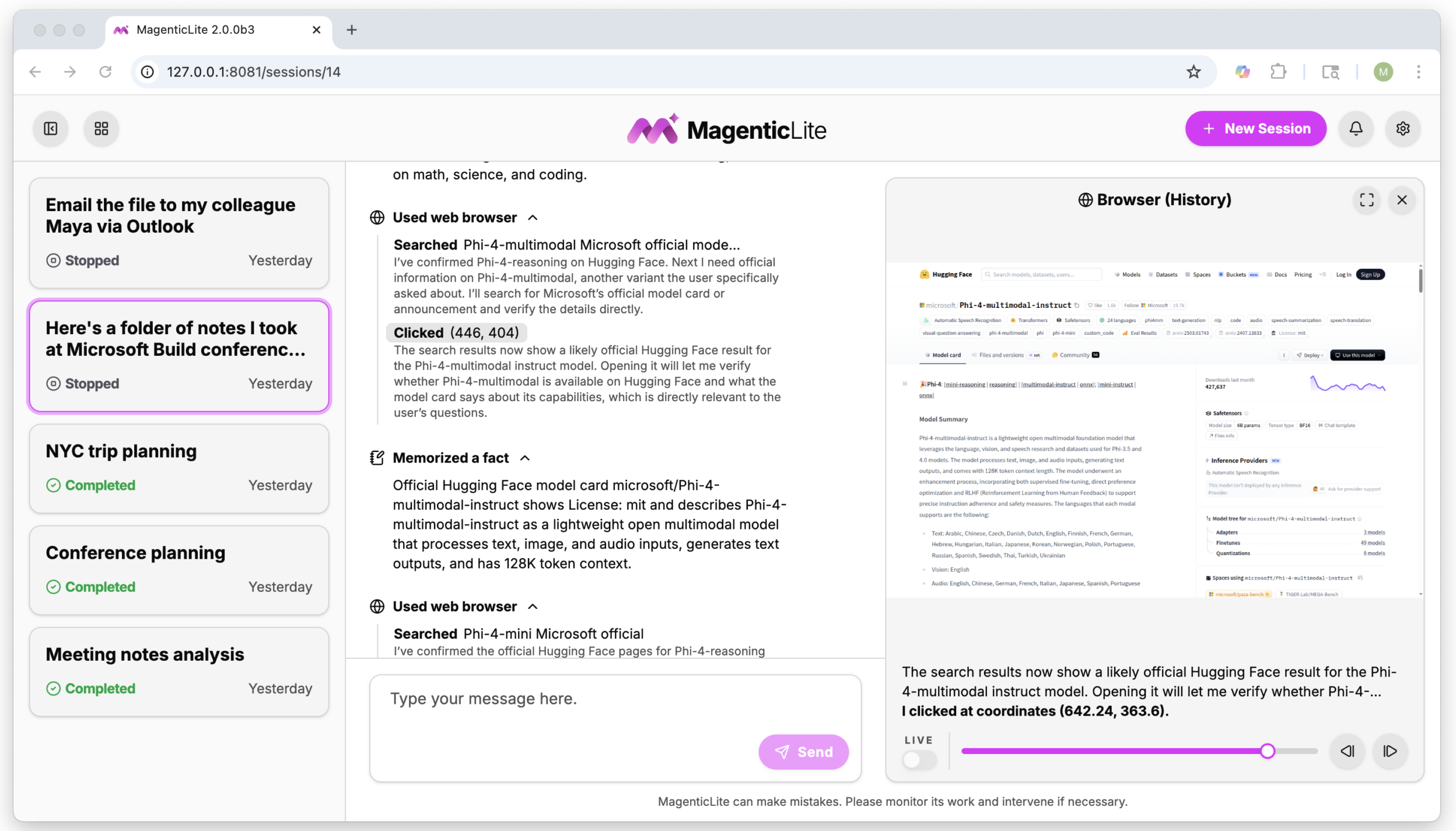
MagenticLite: A Case Study in Lightweight Agent Design
Microsoft Research’s MagenticLite is an illustrative example of how far smaller models can be pushed when the entire stack is codesigned for agents. Built as the successor to Magentic-UI, it runs a single workflow that spans the user’s browser and local file system while keeping data on the user’s machine. The system combines an optimized agent harness with two purpose-built models: MagenticBrain, which plans, delegates, writes code, and recovers from failures, and Fara1.5, a computer-use model family tuned for browser tasks. Rather than relying on a giant general-purpose model, MagenticLite treats agentic capability as a function of tool orchestration and action sequencing. This architecture lets enterprises experiment with powerful automation while using models small enough to be run efficiently on user hardware or modest servers, significantly lowering the infrastructure barrier to deploying production-grade AI agents.
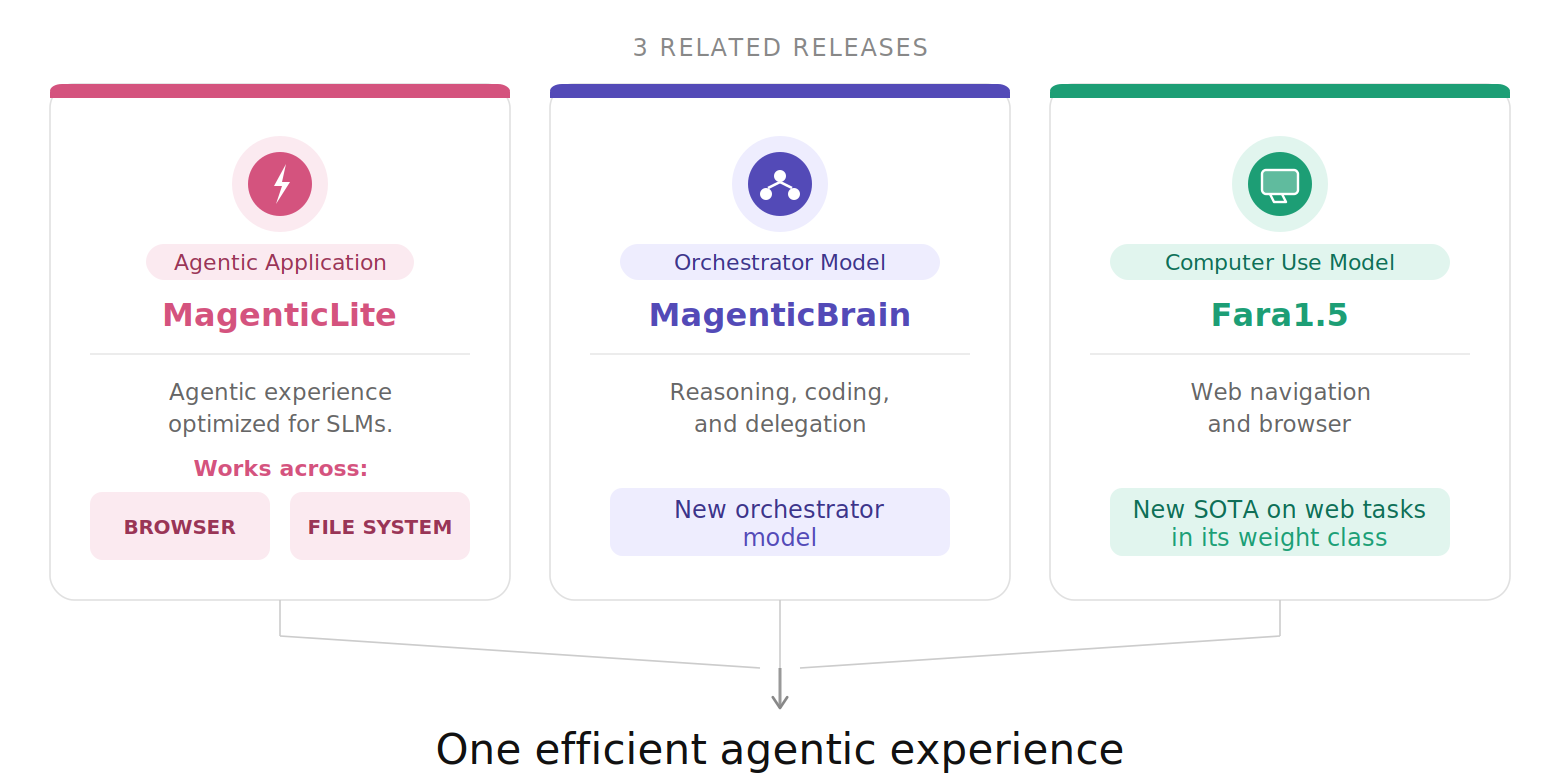
Fara1.5 and MagenticBrain: Specialized Models for Real Workflows
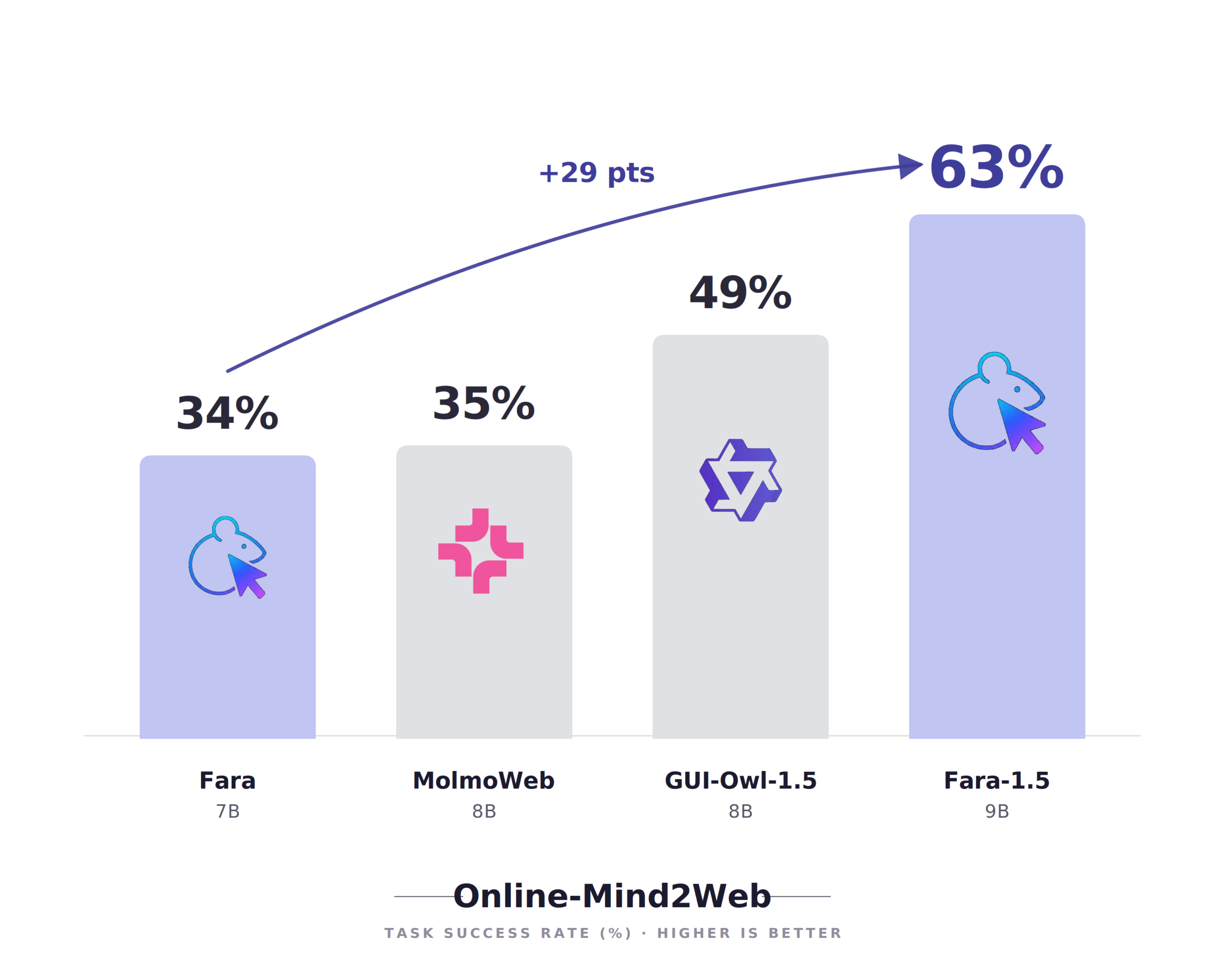
Fara1.5 and MagenticBrain show how specialization beats sheer parameter count for many enterprise use cases. Fara1.5 is a computer-use model family, with a flagship 9-billion-parameter variant optimized for web navigation, forms, credentialed sites, and long-running browser tasks. It delivers state-of-the-art performance among similarly sized models on the Online-Mind2Web benchmark and nearly doubles the performance of its predecessor on web tasks, reflecting gains from a refined synthetic data pipeline and realistic training environments. MagenticBrain, a 14-billion-parameter orchestration model, acts as planner, coder, and delegator, selecting tools and subagents and handling terminal interactions within the MagenticLite harness. Together, they turn vague user goals into concrete, multi-step workflows that span hundreds of actions, pause appropriately at critical points, and maintain context over time. This division of labor illustrates how small language models, when tightly integrated with tools, can match or exceed larger models for targeted agentic workloads.
Why Enterprises Aren’t Waiting for the Next Giant Model
Enterprises face a clear trade-off: wait for future frontier models that may deliver stronger raw reasoning, or deploy capable agents today using small language models, optimized harnesses, and carefully designed tools. Many are choosing the latter. Smaller models make AI agent deployment more practical: they are cheaper to run, easier to host on-premises or at the edge, and better aligned with data residency and privacy requirements because they can keep sensitive information local. Systems like MagenticLite highlight that real-world usefulness depends on the full lifecycle—data, model design, orchestration, interaction patterns, and human oversight—not just model size. By adopting lightweight AI systems, organizations can iterate quickly, align agents with existing processes, and capture incremental value now, while preserving the option to swap in more powerful backends later. In this emerging architecture, efficient agent design—not ever-larger models—becomes the primary driver of enterprise efficiency.
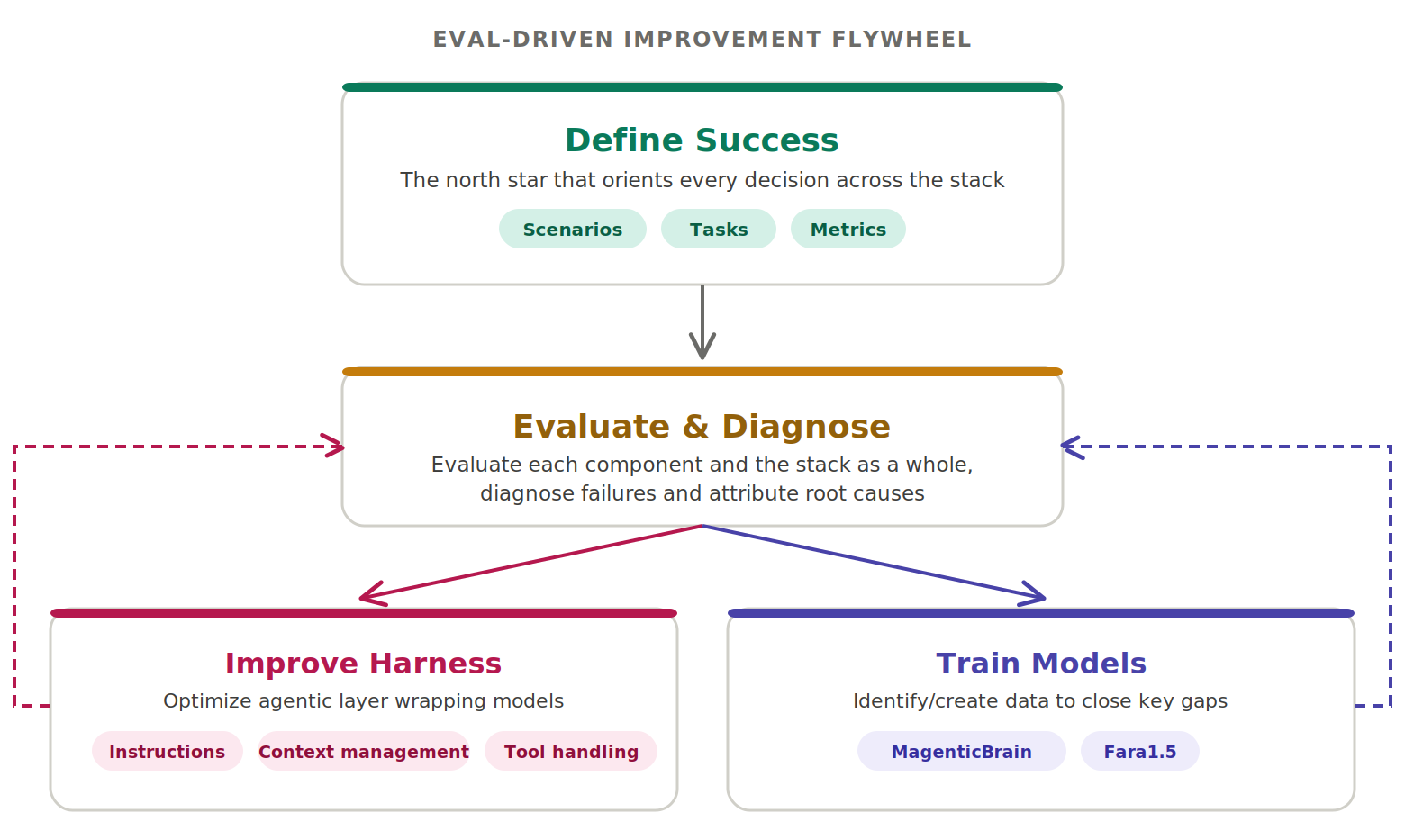
Designing for Speed, Safety and Cost in Agentic Architectures
Efficient agent architectures prioritize deployment speed and operational control alongside accuracy. In MagenticLite’s design, that balance is visible in the user interface and safety mechanisms as much as in the models. Users can see the agent’s reasoning and actions, intervene at any time, and must explicitly approve sensitive steps. Fara1.5 is trained to detect critical points like transactions or login flows, pausing to request user input instead of blindly proceeding, with its latest iteration recalibrated to reduce unnecessary interruptions while still protecting users. The overall system is developed through an iterative evaluation loop that focuses on scenario-based, real-world tasks—such as booking appointments or managing local files—rather than benchmarks alone. For enterprises, this approach offers a blueprint: start with small, specialized models, surround them with robust tooling, observability, and guardrails, and refine performance over time to steadily compound enterprise efficiency without overcommitting to costly, monolithic AI stacks.