What Hardware-Aware LLM Inference Optimization Means
Hardware-aware LLM inference optimization is the practice of arranging model inputs and memory flows so accelerators perform almost no redundant computation, dramatically improving GPU memory efficiency and throughput without changing model weights. Instead of treating GPUs as abstract math engines, these techniques respect their tile sizes, VRAM limits, and transfer bottlenecks to eliminate padding overhead and repeated work on previously processed context. The goal is simple: keep every tensor core busy with useful operations, not multiplying zeros or rereading the same 100-page document ten times. This is becoming central to LLM inference optimization because enterprise workloads are dominated by long, uneven sequences and repeated queries over the same data. By combining smarter sequence packing, pinned-memory transfers, and context caching, production systems are reporting 2–3x gains in throughput and latency, while preserving output quality and keeping infrastructure changes minimal.
Padding Overhead: When GPUs “Cook an Empty Plate”
Most LLM serving stacks still batch variable-length prompts by padding every sequence in a batch to the length of the longest one. That keeps tensors rectangular, but it means the GPU spends much of its time multiplying zeros by zeros and shuttling padded tokens through memory. One developer calls this “the computational equivalent of paying a chef to cook an empty plate,” because a single long document in the batch can force hundreds or thousands of useless token positions for shorter inputs. The problem grows with enterprise traffic, where some prompts are short chat queries and others are long legal contracts or reports. As padding dominates, AI inference costs and latency climb even though user-facing work has not increased. Eliminating this waste is now one of the fastest ways to improve GPU memory efficiency and reclaim throughput without modifying the underlying model architecture.
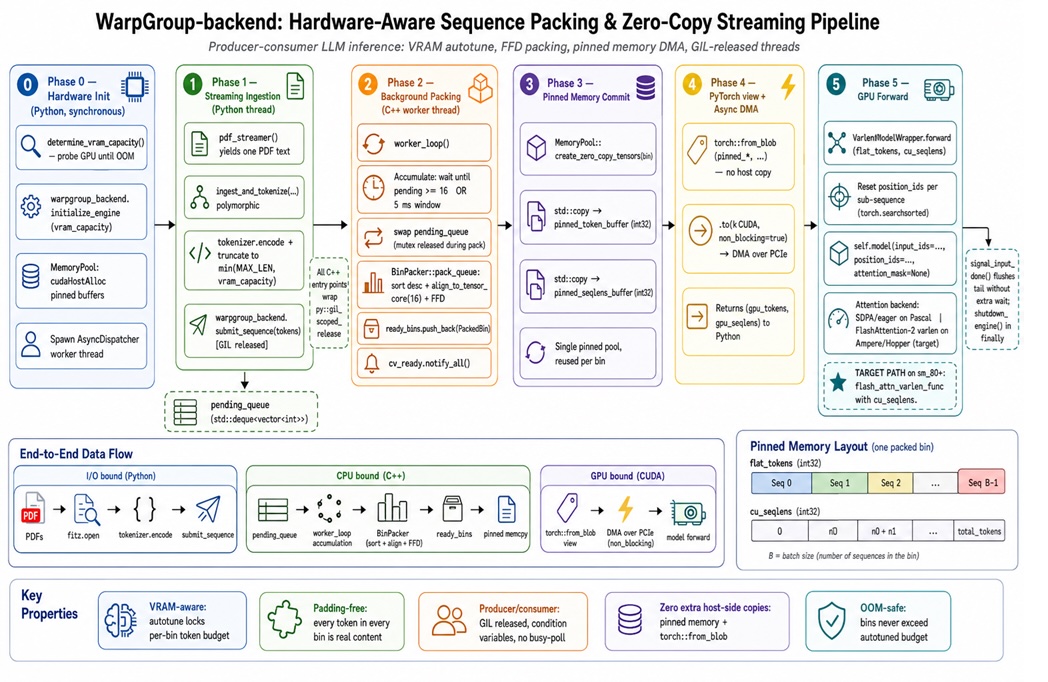
Sequence Packing: Turning Ragged Text Into Efficient Ribbons
Sequence packing tackles padding waste by concatenating variable-length prompts into one long “ribbon” and using attention masks so tokens from different documents cannot interact. Systems like WarpGroup-Backend implement this with VRAM-aware bin packing: incoming sequences are sorted by length and packed into bins whose total tokens stay within empirically measured memory limits. The engine even rounds sequence dimensions to multiples of 16 to match tensor-core tiles, improving kernel efficiency. In tests described by its creator, this hardware-aware sequence packing and scheduling delivered 2.08× throughput on an H100 and up to 5.89× on a GTX 1080, while avoiding out-of-memory crashes. Crucially, this form of LLM inference optimization runs in a C++ backend that bypasses Python’s global interpreter lock, so packing occurs in parallel with tokenization. The result is a busier GPU, fewer idle cycles, and far less waste on padded tokens.
Memory Engines and Context Caching: Eliminating Redundant Work
Padding is not the only source of waste. Enterprise assistants repeatedly answer questions over the same documents, forcing models to reread long contexts from scratch. Corbenic AI’s Taliesin memory engine attacks this by caching processed context—such as KV caches—and restoring it later, bit-identical to a fresh run. According to Corbenic AI, “the longest test contexts took a model more than two minutes to process from scratch” on a USD 0.69 (approx. RM3.20) per hour graphics card, while Taliesin restored them “in under seven seconds: a 21-times speedup, with no loss of accuracy.” The engine moves AI memory across GPUs and even generations, with trials showing 64 of 64 identical output tokens between an Ampere A6000 and an Ada Lovelace RTX 4090. Cryptographic SHA-256 hashes back these claims, giving teams confidence that context caching does not compromise correctness.

Stacking Optimizations to Halve AI Inference Costs
What makes these techniques attractive for enterprises is that they sit below the model: no retraining, no architectural surgery, and no prompt changes are required. Hardware-aware sequence packing trims padding overhead and improves GPU memory efficiency, while memory engines such as Taliesin remove the need to recompute long contexts that have already been read. Together they target the two biggest recurring drains in AI inference costs: fake work on padded tokens and redundant recomputation of context. Production reports from sequence packers show 2–5× throughput gains, and context caching has demonstrated up to 21× faster long-context reuse; in practice, combining them can cut end-to-end latency and operational costs by 2–3× for many workloads. As LLM deployments scale, these backend optimizations are becoming as important as model quality itself, redefining how enterprises think about performance, cost, and infrastructure planning.






