What the New AI Pricing War Means for Developers
The AI pricing war is the rapid collapse of cost per token across leading models, driven by aggressive competition between open-weight providers and budget tiers from major labs, which is reshaping how developers and businesses choose AI infrastructure for everyday workloads. Pricing data from Artificial Analysis shows that token costs have fallen by an order of magnitude in under two years, putting serious pressure on frontier-priced APIs. This matters because cost per token is no longer a background metric; it is a primary design constraint for both indie and enterprise teams. When a model like DeepSeek V4 Flash offers 1 million token context windows at budget rates, developers can rethink how much context they stream and how often they call the API. The result is a market where cheaper models are also sufficiently capable for many production tasks.
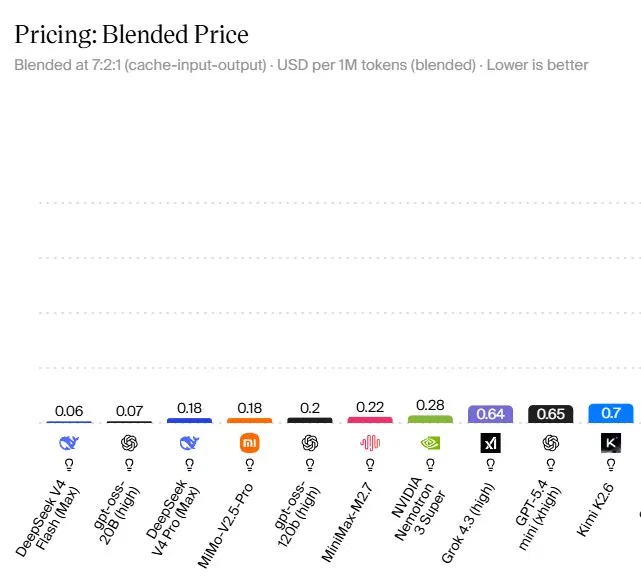
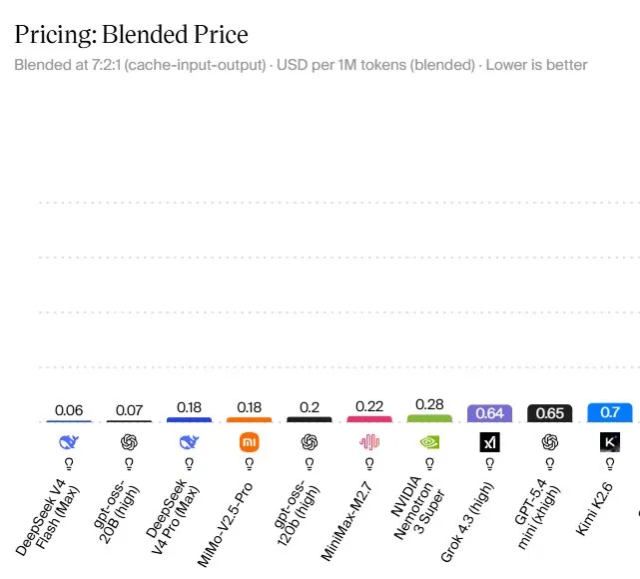
The 10 Cheapest AI Models and Why They Matter
Artificial Analysis’ ranking of the 10 cheapest AI models focuses on blended cost, not headline list prices. At the top is DeepSeek V4 Flash (Max) with a blended price of USD 0.06 (approx. RM0.28) per million tokens, built as a Mixture-of-Experts model that activates only 13B parameters per token to keep inference costs down. Next is OpenAI’s GPT-OSS-20B (High) at USD 0.07 (approx. RM0.32) per million tokens, a small but fast open-weight model suited to high-volume, low-complexity workloads. DeepSeek V4 Pro (Max) and MiMo-V2.5-Pro sit at USD 0.18 (approx. RM0.83) per million tokens, pushing into near-frontier reasoning quality while staying budget friendly. GPT-OSS-120B follows at USD 0.20 (approx. RM0.92) per million tokens, offering a practical step up in depth for complex agents. These prices show that capable models no longer need frontier-level budgets.
Blended Pricing and Real-World Token Use
Headline input and output prices tell only part of the story; real-world AI pricing comparison needs a blended view. Artificial Analysis uses a 7:2:1 cache-hit to input to output token ratio to estimate practical cost per token, which better reflects how production systems cache prompts and reuse context. According to Artificial Analysis, a blended rate of USD 0.06 (approx. RM0.28) per million tokens for DeepSeek V4 Flash makes it cheaper than almost anything else on the market for output-heavy workloads. This matters for teams that stream large documents, run long-agent traces, or keep shared context windows warm. With cache hits dominating usage, marginal output costs become the key lever. Blended pricing also makes comparisons between affordable AI APIs fairer: a model with slightly higher list prices can win on cost per useful token if it encourages more cache reuse or shorter outputs.
Price-to-Performance Trade-offs Across Model Families
Choosing between the cheapest AI models is not only about absolute cost; it is about price-to-performance for your workload. DeepSeek V4 Flash is tuned for speed and volume and even supports a 1 million token context window, but it has a higher hallucination risk when it does not know an answer, which may rule it out for accuracy-critical systems. DeepSeek V4 Pro, by contrast, activates more parameters per inference and scores 52 on the Artificial Analysis Intelligence Index, placing it near the top of open-weight reasoning models while staying at USD 0.18 (approx. RM0.83) per million tokens. On the OpenAI side, GPT-OSS-20B favors throughput and economy, while GPT-OSS-120B offers deeper reasoning at a still modest USD 0.20 (approx. RM0.92) per million tokens. Teams can mix these tiers, routing simpler tasks to cheaper models and reserving higher-cost options for complex reasoning.
How Budget Models Change Strategy for Businesses
As affordable AI APIs spread, cost per token has become a central architectural decision rather than a late budgeting detail. Budget-conscious teams can now run capable AI workloads at significantly lower cost than traditional frontier models, which changes what is economically feasible. For example, OpenRouter’s usage data shows DeepSeek V4 Flash leading token consumption with 10.9 trillion tokens and growth of 995 percent, while Tencent’s Hy3 Preview reached near parity with 10.7 trillion tokens and a price of USD 0.063 (approx. RM0.29) per million input tokens. Such numbers indicate that developers are voting with their wallets and their traffic. Enterprise teams can experiment with broader rollouts, more agent steps, and longer contexts, while indie developers can launch products on lean budgets. The AI pricing war is no longer theory; it is a live constraint that rewards careful AI pricing comparison and blended-cost planning.





