
What the MiniMax M3 Model Is Trying to Solve
MiniMax M3 is a long context AI model for developers that combines a one-million-token context window, frontier coding performance, and native multimodal input so coding AI agents can work across entire codebases, documents, and visual assets within a single system. M3 is designed for teams that want coding AI agents which stay inside large repositories, coordinate tools, and keep track of lengthy tasks instead of resetting every few prompts. MiniMax positions the M3 model as a frontier coding system: it targets software engineering workflows, long-running automation, and multimodal AI development where code, screenshots, diagrams, and even video all feed into one workspace. Rather than focusing on chatbot conversation quality, the release frames M3 as a model meant to sit inside the daily developer stack, from IDE agents to backend automation services.
A Million Tokens of Context for Code and Long Tasks
The headline feature of M3 is its one-million-token context window, paired with a reported 512,000-token guaranteed minimum. That scale matters for long context AI models aimed at engineering work, where a single project can span thousands of files, tickets, and design notes. Instead of chunking repositories into small slices, a coding AI agent using M3 can keep much larger spans of code and documentation in active view. According to MiniMax, this capacity is backed by its MiniMax Sparse Attention design, which cuts per-token compute at the million-token scale and delivers more than nine times faster prefilling and over fifteen times faster decoding compared with its prior generation. If these efficiency claims hold up in outside testing, M3 could make long-context coding workflows more practical by reducing the latency and compute burden that usually come with very large prompts.
Native Multimodal AI Development for Developer Workflows
M3 is built as a multimodal model from the start, supporting text, image, and video as input with text output. For developer tooling, that means a single coding AI agent can read source files, parse architecture diagrams, inspect UI screenshots, or review screen recordings of failing test cases without switching between separate systems. MiniMax is also tying the model to MiniMax Code, an agent interface that breaks work into multistage workflows and uses producer–verifier loops while taking advantage of the model’s multimodal capabilities to drive computer use. In practice, that could enable richer automated debugging, documentation generation from diagrams, or visual regression checks. Because M3 is available through OpenAI-compatible endpoints, existing tools built around that API pattern may integrate the MiniMax M3 model with relatively modest engineering changes.
Positioning Against Other Frontier Long-Context Models
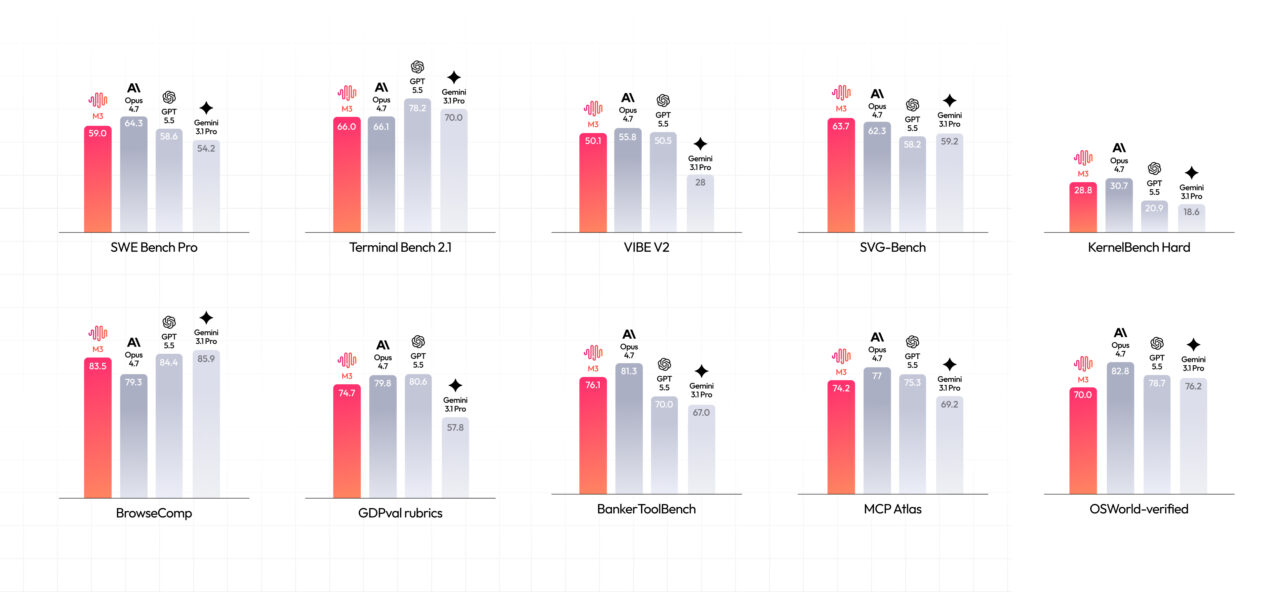
MiniMax is framing M3 as a direct contender in the frontier coding model space, where long context and agent behavior now matter more than leaderboard chat scores. The lab reports that M3 reaches 59.0% on SWE-Bench Pro and 66.0% on Terminal-Bench 2.1, while also scoring 34.8% on SWE-fficiency, 28.8% on KernelBench Hard, and 74.2% on MCP Atlas. It also claims M3 beats GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro and approaches Claude Opus 4.7, with a top score on the Claw-Eval autonomous agent benchmark. These figures, however, come largely from runs on MiniMax infrastructure using agent scaffolding such as Claude Code, Mini-SWE-Agent, or Terminus. Until independent benchmarks arrive, buyers will have to treat the scores as early signals rather than definitive proof of M3’s standing among long context AI models.
Open-Weight Promise and the Road to Real-World Adoption
MiniMax is releasing M3 as both a hosted service and a model it plans to open, promising to publish a technical report and model weights within around ten days of launch. A coding interface at code.minimax.io and live API access give teams a way to probe long context behavior, latency, and multimodal handling before any download appears. From an adoption standpoint, the open-weight promise is key: direct access would let organizations run coding AI agents on their own infrastructure, verify benchmark claims, and adapt M3 to niche workflows. At the same time, new long-horizon benchmarks such as DeepSWE are shifting attention toward end-to-end software engineering tasks, and M3 has not yet appeared on those public boards. Whether the MiniMax M3 model becomes a staple of multimodal AI development will depend on how it performs in these more demanding, real-world style tests.





