
From Cloud-Centric AI to Local GPU Processing
Local GPU processing is the practice of running AI inference and automation directly on nearby graphics processors—inside laptops, desktops, or edge infrastructure—rather than sending data to distant cloud servers, so organisations and individuals can reduce latency, control costs, and keep sensitive information on local hardware. This shift is being driven by the cost of cloud APIs, privacy concerns, and underused GPUs already sitting in devices and data centres. Instead of treating the cloud as the default execution environment, AI workloads are increasingly split: heavy real-time perception and on-device AI inference happens locally, while occasional reasoning or coordination traffic goes to the cloud. At the same time, enterprise data fabric platforms and new GPU memory expansion tools are working to remove the two biggest constraints on local AI acceleration: getting data to the right GPU in time and giving that GPU enough effective memory to hold modern models.
MSI, BlueStacks and the Gaming Laptop as an AI Edge Node
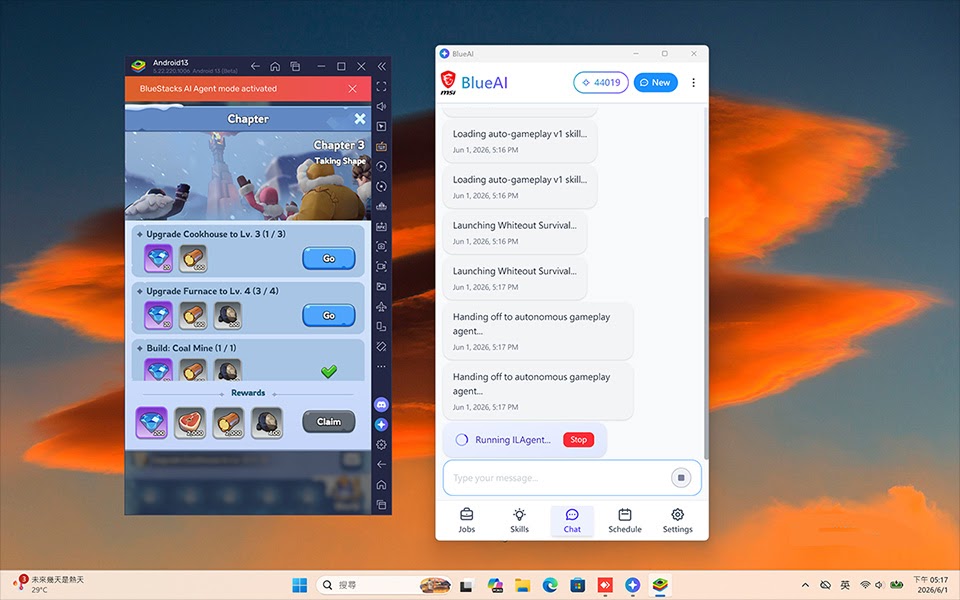
MSI and BlueStacks are turning gaming laptops into edge AI acceleration platforms with Blue AI Worker, a local-first AI agent that runs on the onboard GPU. Instead of sending high-resolution gameplay streams to cloud services, a locally tuned vision-language model interprets the laptop display and automates tasks such as highlight capture or inventory sorting. Only symbolic reasoning calls are sent to a remote service, cutting bandwidth and cloud token use. Rosen Sharma of now.gg notes that existing graphics cards offer “unmatched computational power which is largely idle when gamers leave games to switch windows,” and Blue AI Worker aims to put that dormant capacity to work in the background. MSI even plans a Token Mileage metric that estimates how much processing has been handled locally versus paid API calls, underlining the economic pressure pushing on-device AI inference into consumer hardware.
GPU Memory Expansion and Local LLMs on Consumer Devices
Local large language models are constrained as much by memory as by compute, especially on consumer systems. The OWC Stack AI targets this bottleneck by presenting itself as a Thunderbolt 5 AI accelerator and storage hub that extends working GPU memory using onboard high-speed flash. Rather than being an external GPU, it appears to act as a GPU memory expansion layer, allowing the host system’s graphics hardware to handle larger LLMs than its native VRAM would permit. This design aligns closely with the move toward on-device AI inference: users can run bigger models locally without shifting workloads to costly cloud services and without exposing private data to remote providers. OWC says the Stack AI will support Windows and Linux first, with Mac support expected later, positioning the device as a shared, portable resource for teams that need flexible local AI capacity on standard computers.
Qumulo’s Enterprise Data Fabric and the Problem of Idle GPUs
In the enterprise, the limiting factor for AI is often data movement, not GPU count. Qumulo’s Cloud AI Accelerator tackles this by creating an enterprise data fabric that presents distributed datasets in real time to GPUs across on-premises, edge, and multi-cloud environments. According to an analysis cited by Qumulo, average enterprise GPU utilisation hovers around 5%, leaving expensive accelerated infrastructure idle while teams replicate and stage data. Qumulo’s platform links Cloud Native Qumulo, its Cloud Data Fabric, and NeuralCache so that workloads can run wherever GPU capacity exists, instead of where data is stuck. The company frames this as achieving “GPU liquidity”: connecting without copying, eliminating weeks-long staging delays, and turning GPU hunting into a scheduling problem rather than a logistics challenge. For enterprises, this is a parallel to consumer on-device AI inference—bring the data fabric to the GPU, not the other way around.
Privacy, Latency and the Race to the Local AI Edge
Taken together, these developments point to a broad shift: AI workloads are moving as close as possible to where data is created and used. Local GPU processing trims network hops, cuts response times, and keeps raw content—be it gameplay, enterprise files, or personal documents—on local systems. Edge AI acceleration on gaming laptops shows consumers that their GPUs can automate daily tasks, while GPU memory expansion options such as OWC Stack AI make larger local models viable. In the data centre, enterprise data fabric products like Qumulo’s Cloud AI Accelerator aim to keep GPU fleets busy instead of waiting for data replication to finish. Hardware and software vendors are racing to make on-device AI inference practical at every scale, suggesting that the long-term balance of AI will be hybrid: clouds for training and coordination, local GPUs for fast, private, and cost-aware inference.





