
What Claude Mythos 5 and Claude Fable 5 Are
Claude Mythos 5 and Claude Fable 5 are Anthropic’s latest frontier AI coding models, built on the same Mythos-class architecture to deliver advanced software engineering, reasoning, and vision capabilities while offering different access tiers and safety safeguards for public and enterprise users. Anthropic positions Claude Fable 5 as the general-access, Mythos-level model with strict safety controls, while Claude Mythos 5 is a less restricted variant available only through controlled programs such as Project Glasswing. Both share the same Oceanus-based foundation and identical pricing at USD 10 (approx. RM47) per million input tokens and USD 50 (approx. RM236) per million output tokens, but they differ in how fully they expose frontier capabilities in cybersecurity, biology, and autonomous agents. For developers and enterprises, the launch marks a shift toward pairing top-tier performance with more explicit governance choices.
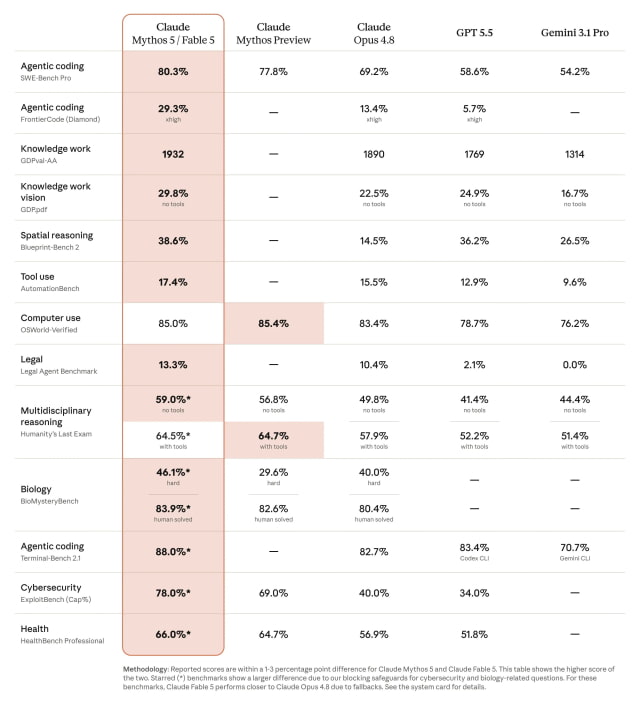
Benchmark Performance: Coding, Agents, and Professional Tasks
Anthropic’s own tests show Claude Mythos 5 and Claude Fable 5 as clear leaders among current AI coding models. On SWE-Bench Pro, they score 80.3%, ahead of Claude Mythos Preview at 77.8%, Opus 4.8 at 69.2%, GPT-5.5 at 58.6%, and Gemini 3.1 Pro at 54.2%. The gap widens on the FrontierCode Diamond benchmark, where Mythos 5 and Fable 5 reach 29.3% compared to Opus 4.8’s 13.4% and GPT-5.5’s 5.7%. In agent-style workflows, the models post 17.4% on AutomationBench and 85.0% on OSWorld-Verified, placing them at or near the top of Anthropic’s comparison. Anthropic notes that on Humanity’s Last Exam, they achieve 59.0% without tools and 64.5% with tools, reflecting gains in complex reasoning, specialized legal and health tasks, and long-running multi-step projects.
Vision Capabilities and Real-World Developer Workflows
Claude Fable 5 is Anthropic’s public face for Mythos-class vision capabilities, aimed squarely at developers and knowledge workers. The model can interpret detailed scientific figures and extract precise numerical values, and Anthropic says it can reconstruct a complete web application codebase using only interface screenshots. In one test, Fable 5 completed a software migration project that a team expected would take over two months, finishing it within a single day. It also handled complex game environments: the model completed Pokémon FireRed from raw screenshots and performed strongly in Slay the Spire, reaching the final act three times more often than Claude Opus 4.8. These vision and reasoning skills are already being embedded into tools like Xcode 26.3, where Anthropic’s models power autonomous coding agents that can refactor, debug, and extend large codebases with minimal human intervention.
Security, Safeguards, and the Mythos–Fable Split
The main difference between Claude Mythos 5 and Claude Fable 5 lies in how Anthropic manages cybersecurity and dual-use risks. Mythos 5 builds on Mythos Preview, which during internal tests identified thousands of software vulnerabilities and showed autonomous vulnerability discovery that prompted Anthropic to keep access limited to around 200 organizations through Project Glasswing. Mythos 5 further advances research uses in areas like drug design, molecular biology, and genomics. Fable 5, by contrast, is tuned to be “safe for general use.” It includes aggressive classifiers that route queries about cybersecurity, biology and chemistry, or model distillation to Claude Opus 4.8 instead, with Anthropic saying these triggers occur in under five percent of sessions. This design keeps most coding and vision capabilities accessible while walling off the riskiest exploit-focused behaviors.
Strategic Implications for Developers and Enterprises
Anthropic’s dual-model strategy signals how frontier AI performance and AI safety safeguards will likely co-exist for developers and enterprises. Claude Fable 5 offers Mythos-level power for everyday coding, data analysis, and vision-heavy workflows, but its guardrails mean some advanced cybersecurity and bioscience capabilities are intentionally throttled. Claude Mythos 5, in contrast, is aimed at vetted cyber defenders, governments, and critical infrastructure operators that need full-strength vulnerability discovery and advanced scientific reasoning under strict governance. For most teams, Fable 5 will be the default option, with its conservative classifiers limiting exposure to high-risk outputs while keeping benchmark-leading performance on mainstream tasks. Organizations with heightened security or regulatory duties can pursue Mythos 5 access, but Anthropic’s approach makes clear that the most capable models will live behind layered controls rather than open public endpoints.





