What Claude Opus 4.8 Is and Why It Matters for Developers
Claude Opus 4.8 is Anthropic’s latest flagship AI model that combines advanced coding features, stronger reasoning, and safer autonomous workflows to help developers tackle complex software engineering and research tasks more reliably. Positioned as an upgrade over Opus 4.7, the new model targets enterprise and team environments where long-running code changes, debugging sessions, and tool use need both accuracy and transparency. Anthropic says Opus 4.8 is more willing to admit uncertainty and less likely to make unsupported claims, which is important when AI coding models are embedded into production workflows. Pricing remains unchanged from Opus 4.7, which lowers friction for teams already using Claude in their developer AI tools. For engineering leaders, Opus 4.8 marks a step toward AI systems that can own larger portions of the software lifecycle while staying aligned with organizational policies.
Coding Power: Benchmarks, Dynamic Workflows, and Claude Code
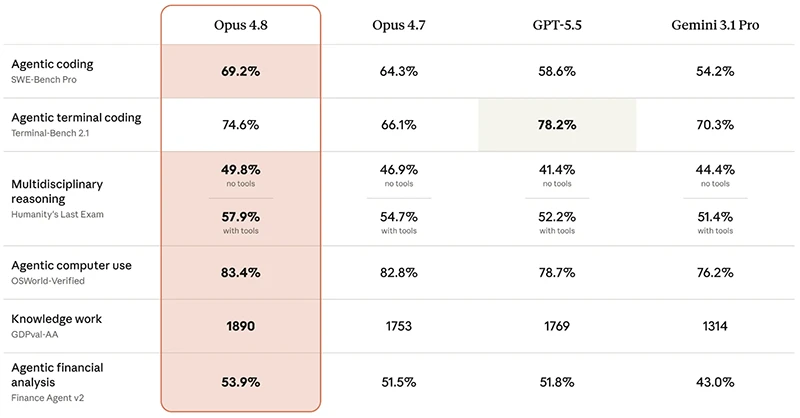
On paper, Claude Opus 4.8 posts some of the strongest coding numbers in the current AI coding models landscape. On SWE-Bench Pro, which measures how well models autonomously resolve real GitHub issues, Opus 4.8 scores 69.2%, beating Opus 4.7 at 64.3%, OpenAI’s GPT-5.5 at 58.6%, and Google’s Gemini 3.1 Pro at 54.2%. OpenAI still leads terminal-style workflows: on Terminal-Bench 2.1, GPT-5.5 scores 78.2% against Opus 4.8’s 74.6%, though Opus narrows the earlier gap from Opus 4.7’s 66.1%. Beyond raw scores, Anthropic is pushing Dynamic Workflows in Claude Code, letting Opus 4.8 plan work, spin up hundreds of parallel subagents, and verify outputs. According to Anthropic, “Claude Code with Opus 4.8 can now carry out codebase-scale migrations across hundreds of thousands of lines of code from kickoff to merge, with the existing test suite as its bar.”
Reasoning, Reliability, and Safer Agentic Behavior
Opus 4.8’s value for developer workflows extends beyond coding speed to reasoning quality and safety. On Humanity’s Last Exam, a benchmark for multidisciplinary expert-level reasoning, Opus 4.8 reaches 49.8% without tools and 57.9% with tools, ahead of Opus 4.7’s 46.9% and 54.7% and GPT-5.5’s 41.4% and 52.2%. These gains matter when models interpret ambiguous requirements, infer edge cases, or propose architectural changes. Anthropic reports the model is around four times less likely than Opus 4.7 to leave flaws in generated code unremarked, and testing shows lower rates of deceptive or misaligned behavior. Early users describe Opus 4.8 as “more reliable and sharper in its judgement when it’s performing agentic tasks.” For teams, this means greater confidence in using developer AI tools to handle multi-step refactors, security-sensitive changes, and automated pull requests with human review focused on key risks instead of basic correctness.
Mythos-Class Models and the Future of AI Accessibility
Alongside Opus 4.8, Anthropic confirmed that Mythos-class models—currently more capable than Opus in some areas—will roll out to all customers once extra cyber safeguards are in place. Claude Mythos, first tested in the Project Glasswing defensive coalition, is designed for advanced cybersecurity work such as vulnerability discovery, code auditing, exploit-path analysis, and autonomous threat investigation. Early internal tests reportedly saw Mythos scan about 1,000 open-source projects and identify over 23,000 security vulnerabilities within minutes. Until now, this power was limited to a small group of large organizations; broader access will put Mythos-class capabilities in reach of more security and platform teams. Anthropic says Opus 4.8 already performs at a level similar to Claude Mythos Preview on alignment measures, hinting that future Mythos models could combine higher intelligence with similar safeguards, reshaping how developers and defenders integrate AI into everyday workflows.
What Changes for Developer Workflows and Team-wide AI Use
For developers, Claude Opus 4.8 and the coming Mythos-class rollout point toward AI that can take on larger, riskier chunks of work while staying more accountable. Opus 4.8’s coding benchmarks, Dynamic Workflows, and improved honesty make it a stronger candidate as a codebase-scale assistant for migrations, bug triage, and cross-repo refactors. The unchanged pricing from Opus 4.7 and availability across plans mean teams can upgrade without revisiting budgets, then tune effort controls to balance speed, cost, and reasoning depth per task. Mythos-class access promises deeper security analysis across code and infrastructure, turning AI from a helper into an active participant in secure development lifecycles. As Anthropic also works on models that match many Opus capabilities at lower cost, engineering leaders should expect AI coding models to spread beyond specialists and into everyday tools for every developer on the team.





