Token Optimization Becomes a First-Class Design Constraint
AI coding tools efficiency is no longer just about smarter suggestions; it is about how many tokens they burn to get there. Token consumption governs both latency and the bill developers ultimately pay for AI assistant cost reduction. With large language models powering coding agents, every prompt, context window, and tool invocation translates into tokens, and therefore into real-time performance and operating cost. As organizations scale AI-assisted workflows across teams and repositories, token optimization development becomes a core engineering objective rather than an afterthought. Vendors now tune prompts, break workflows into modular skills, and aggressively cache context to minimize round trips to the model. This emerging focus is shaping product decisions, from how agents structure conversations to how they call external tools, and is driving a competitive race where GitHub Copilot performance, Claude Code alternatives, and other platforms are judged on resource efficiency as much as raw capability.
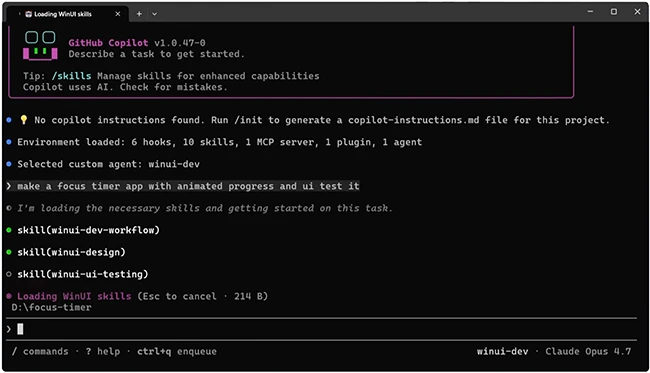
WinUI Agent Plugin: A 70% Cut in Tokens for Windows App Cycles
Microsoft’s new WinUI agent plugin showcases how deep workflow tailoring can yield dramatic token savings. Designed to drive the full WinUI 3 lifecycle—scaffolding, building, running, testing, and packaging into signed MSIX—it combines one central agent with eight composable skills and three supporting tools. The winui-dev workflow and design skills orchestrate project creation, diagnostics, and XAML layout, while additional skills cover code review, UI testing, WPF-to-WinUI migration, packaging, and environment setup. Crucially, each skill loads only the minimal context it needs and offloads specialized analysis to tools like the winui3-analyzer Roslyn DLL and a native-AOT search index of sample projects. According to Microsoft engineer Nikola Metulev, this architecture now delivers the same functionality using more than 70% fewer tokens than earlier iterations on the same model. For developers, that reduction translates into faster responses, lower backend costs, and more predictable AI coding tools efficiency throughout the Windows app development loop.
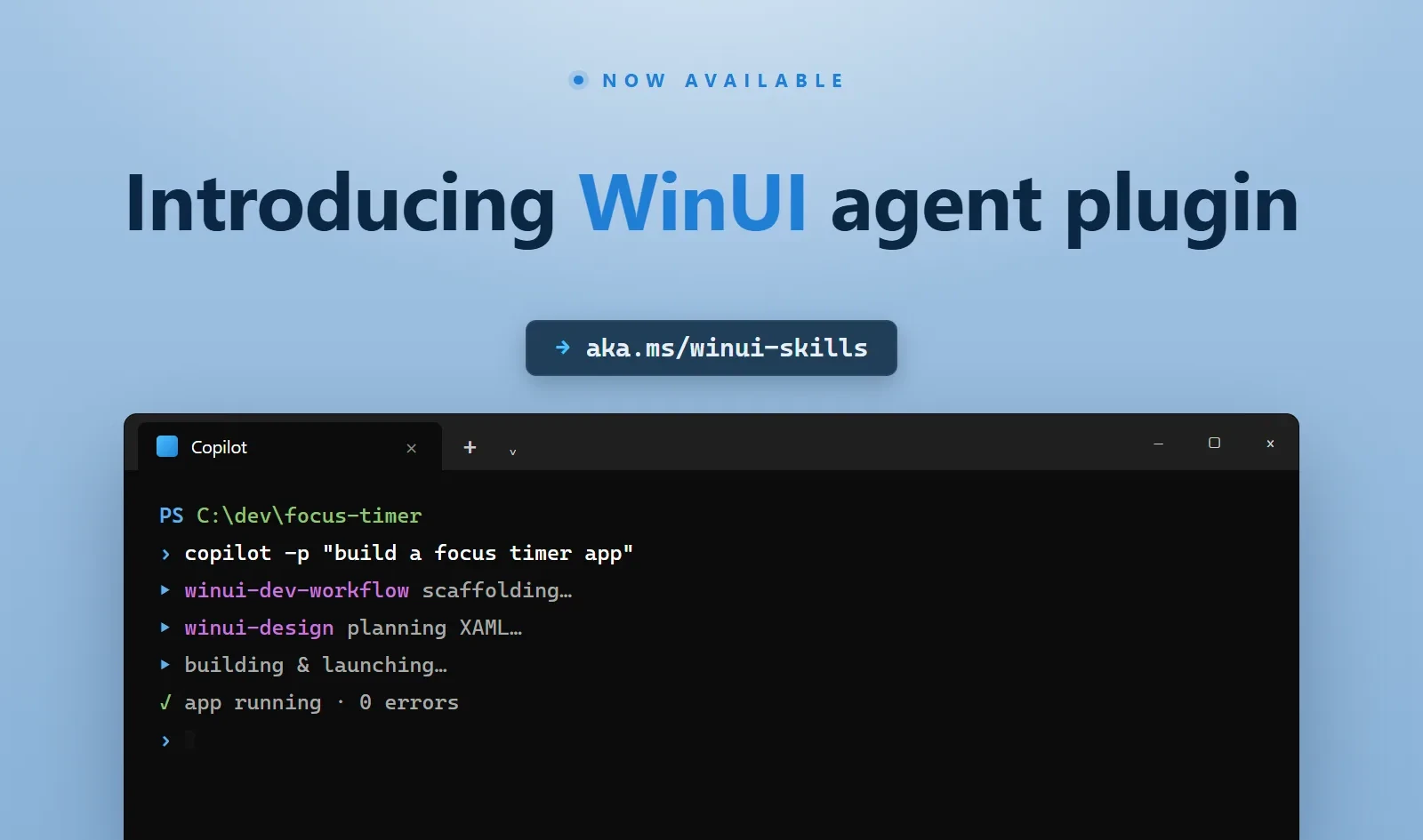
GitHub Copilot’s Desktop Push and the Efficiency Race
GitHub is pushing Copilot beyond the editor with a dedicated desktop app built on Copilot CLI, positioning it as a central hub for coding agents, issues, pull requests, and development sessions. The app adds a unified inbox, session history, repository context, and the ability to run multiple agents simultaneously, while keeping developers inside a single interface. Under the surface, consolidating workflows into one client can improve token optimization development by reusing context across tasks instead of rehydrating it in separate terminals, browsers, or IDE tabs. By anchoring the experience on Copilot CLI, GitHub can tune how prompts are constructed and how agents share state, which directly affects GitHub Copilot performance and perceived responsiveness. This platform approach also sets the stage for more advanced resource-aware behaviors—such as throttling redundant calls or prioritizing high-impact tasks—further tightening the feedback loop between capability, efficiency, and user experience.
Microsoft’s Strategic Shift from Claude Code to Copilot CLI
Behind the scenes, major tech companies are rebalancing engineering resources across AI coding platforms based on efficiency and controllability. Microsoft is winding down internal Claude Code usage within its Experiences + Devices division, moving engineers on products like Windows and Microsoft 365 onto GitHub Copilot CLI by a June 30 cutoff. Leadership frames this as a benchmark-then-converge strategy: run both tools in real-world workflows, then standardize where Microsoft can directly shape security, repository integration, and tooling. Consolidating on Copilot CLI helps reduce overlapping software spend and narrows the agentic stack to one where Microsoft can deeply optimize token paths, prompt design, and integration points. For teams, this means migrating scripts, review pipelines, and daily repository interactions to a single AI assistant. For the broader ecosystem, it signals how strongly token-aware performance and tight platform alignment now influence decisions between Claude Code alternatives and in-house solutions.
Workflow-Level Optimization: Scaffolding, Testing, and Packaging
The most significant token and time savings are emerging from end-to-end workflow optimization rather than isolated prompt tweaks. In the WinUI plugin, discrete skills manage scaffolding, build orchestration, error diagnosis, UI layout, and MSIX packaging, each delegating specialized checks to compiled tools instead of re-deriving context in the model. Automated analyzers catch common pitfalls during builds, reducing back-and-forth clarification tokens. Search tools index curated samples, letting the agent fetch targeted snippets instead of pulling broad, token-heavy documentation into every conversation. Similar patterns are likely to appear across other AI coding tools: decomposing complex tasks into efficient, reusable steps; reusing context between build, test, and packaging phases; and leaning on static tools where possible. As these practices spread, developers can expect AI assistant cost reduction alongside faster iteration cycles, with workflows tuned to minimize redundant calls while still improving code quality and reliability.
