A High-Stakes Comeback Bid in AI Coding Tools
Cursor is trying to reclaim its place in AI-assisted development with Composer 2.5, an upgraded in-house model aimed squarely at professional coding workflows. Once seen as a default choice for AI coding, Cursor has recently been overshadowed by Claude Code, which has surged in adoption among business customers. That shift has put Cursor in a strategic bind: it both competes with Anthropic and pays Anthropic for inference when users choose Claude inside its IDE. Composer 2.5 is Cursor’s attempt to break out of that dependency and reset the AI coding tools comparison narrative in its favor. The model targets long-running tasks, autonomy, and reliability—precisely the areas that matter for multi-file refactors and complex feature work. With the market’s attention shifting from “AI in the IDE” toward autonomous coding agents, Composer 2.5 is positioned as Cursor’s answer to that next wave.

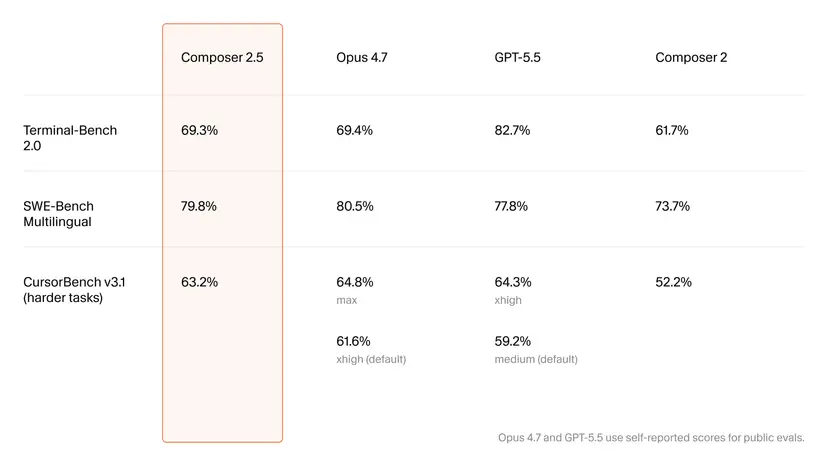
Benchmarks: Near-Opus Performance at a Fraction of the Cost
On paper, Composer 2.5 looks like a serious contender. It posts 79.8% on SWE-Bench Multilingual, just behind Opus 4.7’s 80.5% and ahead of GPT-5.5’s 77.8%. On Terminal-Bench 2.0, it reaches 69.3%, almost matching Opus 4.7’s 69.4%, while GPT-5.5 still leads at 82.7%. Cursor’s own harder-task benchmark, CursorBench v3.1, paints a similar picture: Composer 2.5 scores 63.2%, between Opus 4.7’s higher max configuration and its lower default setting, and above GPT-5.5’s default. The bigger story, though, is cost efficient coding AI. Composer 2.5 is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster variant at USD 3.00 (approx. RM13.80) and USD 15.00 (approx. RM69.00) respectively. Cursor claims this yields up to 10x cost efficiency versus rivals at similar benchmark performance levels.

Targeted RL and Synthetic Data: How Composer 2.5 Was Trained
Under the hood, Composer 2.5 builds on Moonshot’s Kimi K2.5 checkpoint, but Cursor says roughly 85% of total compute went into its own training and reinforcement learning. The core innovation is targeted RL with localized textual feedback: instead of relying on a single reward signal at the end of a long rollout, the system injects short hints exactly where the model misbehaves—such as an incorrect tool call—and uses the corrected behavior as a teacher signal. This is meant to solve credit assignment across trajectories spanning hundreds of thousands of tokens, a critical requirement for robust coding agents. The team also scaled synthetic data dramatically, training on roughly 25 times as many synthetic tasks as Composer 2, and tuned “communication style and effort calibration” so the model better follows nuanced instructions. These changes are specifically aimed at improving long-running agentic work, multi-step reasoning, and consistent code generation.
Claude vs Cursor Pricing: A Calculated Undercut of Frontier Models
Composer 2.5 is as much a pricing maneuver as it is a technical release. Claude vs Cursor pricing has become a central competitive storyline: Anthropic can offer Claude Code inside Cursor at aggressive rates, while Cursor pays Anthropic for those calls, squeezing Cursor’s margins. By fielding its own model with significantly lower per-token pricing, Cursor is trying to flip that dynamic. Internal charts shared at launch show Composer 2.5 hitting about 63% on CursorBench at under USD 1 (approx. RM4.60) average cost per task, while competing models cost several dollars more for similar or weaker scores. For enterprises running large volumes of automated refactors, tests, and agentic workflows, this kind of cost profile could be decisive. The bet is clear: if Composer 2.5 can deliver “good enough” or better quality, its cost efficiency may force organizations to reconsider defaulting to Claude or GPT for coding agents.
Benchmarks vs Reality: Will Composer 2.5 Actually Ship Better Code?
Despite the impressive numbers, there is healthy skepticism about how well Composer 2.5 will perform in real projects. Observers note that raw benchmark wins often fail to translate into improved developer productivity, especially when models struggle with project context, multi-file changes, or consistent adherence to coding style. Early community feedback echoes this concern: some users report promising gains in sustained coding tasks and tool handling, while others describe agent sessions that lose track of task state or abruptly switch behavior mid-run. That tension underscores the gap between leaderboard results and the messy reality of large codebases. Cursor’s heavy investment in targeted feedback, synthetic tasks, and behavior calibration is clearly aimed at closing that gap—but robust third-party evaluations of real-world coding reliability are still missing. Until teams test Composer 2.5 across their own repositories, its true standing in the AI coding tools comparison remains an open question.