What Padding Overhead Is And Why It Quietly Kills Throughput
Hardware-aware sequence packing for LLM inference is the practice of rearranging variable-length token sequences so they align with GPU-friendly shapes and memory limits, minimizing padding tokens and wasted computation while sustaining high throughput on standard GPUs during both prefill and decode. In most stacks, LLM inference optimization starts with batching, but standard batching hides a problem: padding overhead. Frameworks turn ragged text into neat rectangles by padding every sequence in a batch to the maximum length, then run attention and matrix multiplies over those zeros. As one C++ backend author puts it, this means your GPU is “getting paid by the hour to do pretend work” on padded tokens, inflating latency and memory use without improving model quality. When one request is 2,000 tokens and the rest are under 200, the majority of FLOPs and memory bandwidth feed padding, not useful tokens.
From Rectangles To Ribbons: Sequence Packing On The GPU
To cut padding overhead reduction to near zero, you stop treating each prompt as a separate row and turn many sequences into a single long ribbon. Variable-length attention kernels, such as FlashAttention-2’s varlen functions, operate on this ribbon while respecting per-sequence boundaries. The hard part is sequence packing GPU logic: deciding which sequences share a ribbon, in what order, and up to what total token budget, so the GPU stays busy without out-of-memory errors. A practical strategy is bin packing, where each “bin” is a maximum ribbon length measured in tokens. You sort sequences by length, drop long ones into bins first, and fill gaps with shorter ones. This replaces huge padded rectangles with tightly packed ribbons, so nearly every multiply-accumulate touches real tokens instead of padding.
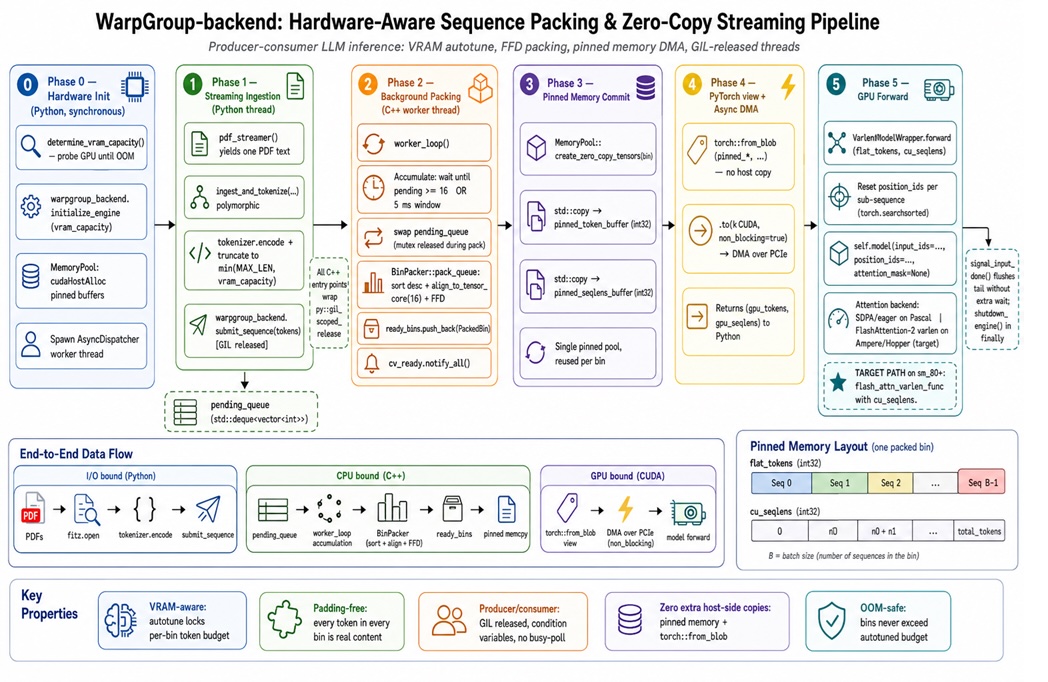
Making Packing Hardware-Aware: Tiles, VRAM And C++ Pipelines
Hardware-aware inference means aligning packing decisions with the GPU’s true capabilities instead of abstract tensor shapes. Modern NVIDIA Tensor Cores favor sequence dimensions that are multiples of 16 for many dtypes and architectures. A hardware-aware packer rounds sequence lengths up to these tile-friendly sizes, for example mapping 137 tokens to 144, so downstream GEMMs and attention kernels achieve better occupancy and memory coalescing. VRAM-aware bin sizing is equally important: usable capacity depends on model parameters, KV cache growth, allocator fragmentation, and runtime quirks, so backends empirically probe sequence limits and back off by a safety margin. To keep this logic from slowing the hot path, the most effective designs move packing into a C++ backend, using background threads, thread-safe queues, and pinned-memory transfers, while Python focuses on tokenization and high-level orchestration.
Why This Matters Most On Standard GPUs Under Throughput Pressure
When GPUs are scarce or modest, hardware-aware sequence packing can be the difference between a sluggish demo and a production-ready service. One C++ WarpGroup backend reported up to 2.08× throughput on an H100 and as much as 5.89× on a GTX 1080 by tightening packing and cutting padding work. These gains mirror broader system-wide efforts: Xiaomi’s MiMo-V2.5-Pro UltraSpeed mode, co-designed with TileRT, breaks 1,000 tokens per second on general-purpose GPUs, compared with earlier MiMo models around 150 tokens per second. According to Xiaomi, UltraSpeed offers a “10x output experience” while running on non-specialized hardware. The common lesson is clear for LLM inference optimization: when you stop burning compute on padding and align sequences to what the GPU hardware likes, you free enough capacity to serve more users, reduce queueing, and hit higher token-per-second targets without upgrading every card.






