Composer 2.5: An Aggressive Play on AI Developer Pricing
Cursor’s new Composer 2.5 model is positioned as a cost‑efficient challenger to premium AI coding tools like Claude Opus and GPT. The company claims up to 10x better AI coding tools cost efficiency compared with rival agents at similar capability levels, leaning on aggressive token pricing and a focus on long-running development work. The standard tier is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, while a faster default variant is listed at USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.00) per million output tokens. Another source notes this faster tier at USD 3.00 (approx. RM13.80) and USD 15.00 (approx. RM69.00) with temporary launch usage boosts rather than permanent discounts. In practical terms, Cursor is trying to make extended coding sessions and multi-file refactors cheaper without conceding too much on capability or responsiveness.
Kimi K2.5 Base Model with Heavy Post‑Training
Rather than swapping to a new foundation, Cursor keeps Moonshot’s Kimi K2.5 as the base model and bets on post‑training to unlock better code generation efficiency. Composer 2.5 builds on the same open‑source checkpoint as Composer 2 but reportedly trains on 25 times more synthetic tasks. Cursor has also increased the complexity of its reinforcement learning environments and added new learning methods, effectively feeding the model a large set of generated practice workloads before developers entrust it with real repositories. This scaled training is paired with what Cursor calls improved behavioral calibration, targeting communication style, effort calibration, and adherence to nuanced instructions. For developers, the promise is a familiar underlying model that now plans better, uses tools more reliably, and handles longer coding jobs with fewer stalls or off‑track detours—all without paying Claude‑ or GPT‑style premiums for every extended coding session.

Targeted Reinforcement Learning Aims to Tame Long‑Running Tasks
The core technical bet in Composer 2.5 is that smarter reinforcement learning can guide long‑running tasks more cheaply than brute‑force scaling. Cursor describes a system of localized textual feedback: during training, the agent receives short, targeted hints exactly at trajectory points where it could have behaved better. This approach aims to solve the classic credit‑assignment problem in RL—figuring out which decisions in a long sequence deserve praise or correction—without losing the overall objective. By tightening this feedback loop and combining it with behavioral calibration, Composer 2.5 is designed to keep multi‑step coding agents on track, reduce wasted tokens from meandering reasoning, and therefore cut API costs for extended refactors and debugging sessions. Early anecdotal feedback, however, suggests remaining rough edges: some users report the agent occasionally slipping out of “agent mode” mid‑task and needing manual prodding to resume work.
Benchmark Scores: Close to Opus and GPT, but Not a Clear Win
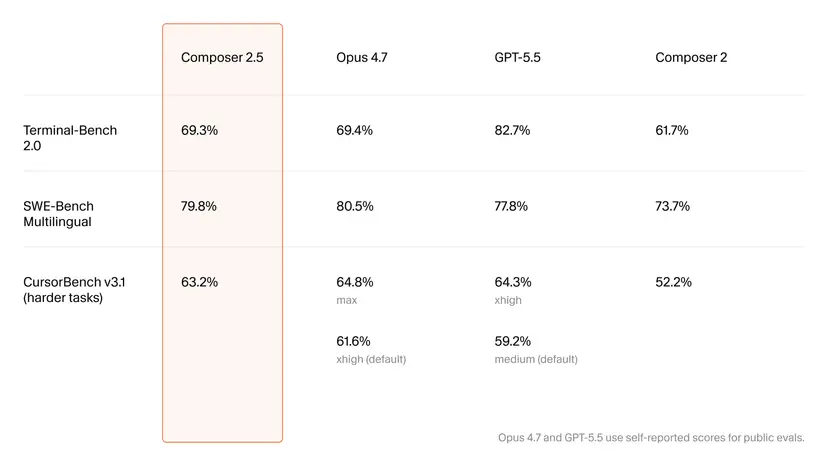
On paper, Composer 2.5 delivers notable benchmark gains over Composer 2 and pressures higher‑priced competitors. Cursor reports a jump on Terminal‑Bench 2.0 from 61.7% to 69.3%, and from 52.2% to 63.2% on its internal CursorBench v3.1. Another report cites 79.8% on SWE‑Bench Multilingual and 63.2% again on CursorBench v3.1, targeted at code generation accuracy and agent‑style task completion. While Composer 2.5 still trails Claude Opus 4.7 and GPT‑5.5 on most headline metrics, it reportedly edges GPT‑5.5 by about two percentage points on SWE‑Bench Multilingual—an encouraging sign for a cheaper model. For buyers comparing AI developer pricing, this positions Composer 2.5 as a value play: close enough on raw scores that the lower token rates may offset small capability gaps, especially for large, continuous coding sessions.
From Benchmarks to Real Repositories: What Developers Should Watch
Despite strong numbers, even Cursor and its users acknowledge that benchmarks are only a proxy for real‑world coding effectiveness. Reddit discussions around Composer 2.5 highlight a common concern: models that excel on SWE‑Bench or Terminal‑Bench do not always translate into higher practical productivity. Developers frequently see “better” models produce code requiring heavy cleanup or misaligned with project conventions. The real test for Composer 2.5 will be its behavior on live multi‑file refactors, its consistency across a codebase, and how predictably it uses tokens across long sessions. Cursor’s agent is already integrated into existing projects, so teams can begin side‑by‑side trials against Claude or GPT: for example, running identical refactors and comparing time, token spend, and post‑edit fixes. If Composer 2.5’s cost savings hold up without sacrificing quality, it could reset expectations for what AI coding tools cost at the high end.