
Refactoring Leaderboards Show Rapid Gains in AI Capability
Scale Labs’ new Refactoring Leaderboard is redefining how AI coding agents are evaluated. Instead of scoring isolated snippets, the benchmark drops agents into full repositories and asks them to perform automated code restructuring without changing behavior. Tasks span decomposing monolithic implementations, replacing weak interfaces with cleaner abstractions, extracting duplicated logic, and relocating code to sharpen module boundaries. According to Scale Labs, these refactoring challenges require roughly twice the lines of code changes and 1.7 times more file edits than its SWE-Bench Pro tasks, making them a tougher test of real-world software engineering. Claude Code with Opus 4.7 currently tops the leaderboard, with ChatGPT 5.5 in second place, highlighting a widening gap between frontier closed models and open-weight systems. Yet even top-ranked agents often leave behind dead code, stale imports, and outdated comments, signaling that “passing the tests” is not the same as delivering production-grade refactors.
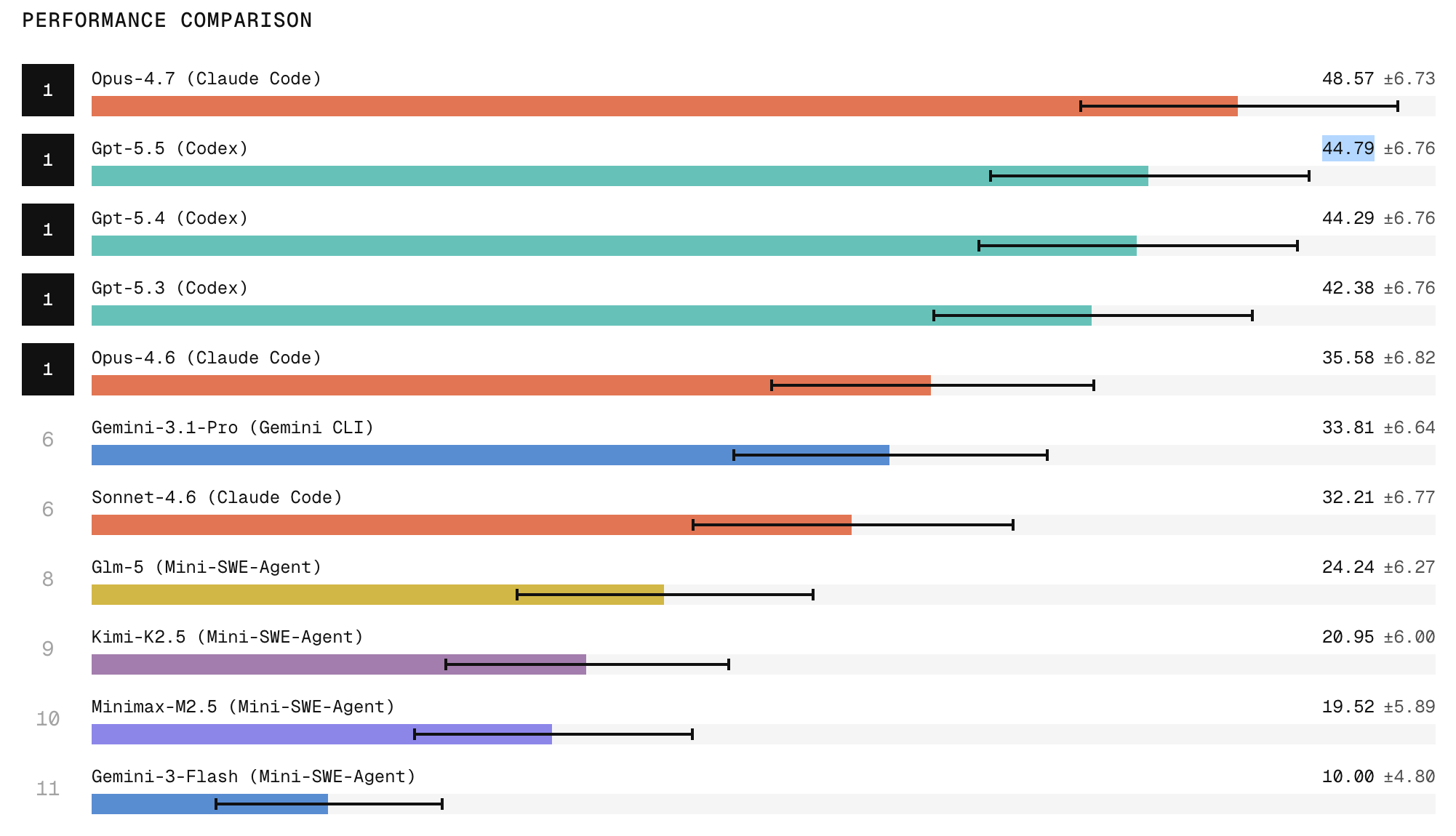
Reliability: The Missing Link Between Demos and Production Use
Despite improving scores, reliability remains the central hurdle for AI coding agents. Scale Labs’ data shows that when an agent attempts the same refactoring task three times, it is two to three times more likely to succeed once than to succeed in all three runs. In practice, that means a model can look capable during a demo yet still be too inconsistent to run unattended in production workflows. The Refactoring Leaderboard explicitly measures not just peak capability but repeatability: can an agent restructure code across multiple files, maintain tests, and clean up artifacts every time? Frequent issues—duplicated implementations, missed call sites, and lingering obsolete comments—undermine developer trust even when tests remain green. By treating agents more like software engineers than mere code generators, Scale Labs highlights the nuanced difference between a one-off success and the sustained reliability teams need before handing over structural changes to AI.
C++ Developers Adopt AI While Questioning Its Reliability
Among C++ programmers, AI adoption is rising fast, but confidence lags. The Standard C++ Foundation’s latest survey reports that 39.8 percent of respondents now frequently use AI for writing code, up from 30.9 percent the previous year. Usage for writing tests climbed from 20 to 33 percent, and for debugging from 11.5 to 23.6 percent, signalling that AI coding agents and code refactoring tools are steadily entering more phases of the development cycle. Yet 42 percent still rarely or never use AI, citing incorrect output, lack of trust in results, data privacy concerns, and tool costs. Developers also report that AI struggles with large projects and complex build systems—precisely the environments where automated code restructuring would be most valuable. This tension mirrors Scale Labs’ findings: technical progress is undeniable, but developer trust in AI remains fragile, especially when subtle errors can slip past tests and into critical systems.
Why Performance Metrics Alone Don’t Build Developer Trust
The emerging gap between benchmark scores and real-world confidence suggests that developer trust in AI hinges on more than accuracy percentages. For refactoring, engineers care about maintainability, artifact cleanup, and alignment with project architecture as much as passing tests. Scale Labs’ rubric-based reviews attempt to quantify these qualities, flagging anti-patterns, documentation quality, and leftover cruft. C++ developers, meanwhile, complain about AI faltering on complex builds, echoing a broader worry: metrics often fail to capture the nasty edge cases that haunt large codebases. When an AI agent occasionally leaves dead code or breaks subtle invariants, every subsequent suggestion must be inspected closely, erasing any promised productivity gains. Until benchmarks reflect the messy reality of production repositories—and report consistency as prominently as peak performance—developers will continue to treat AI assistants as helpful but fallible interns rather than trustworthy partners in automated code restructuring.
Toward Standardized Benchmarks and Transparent Evaluation
To close the confidence gap, the industry needs shared, transparent ways to evaluate AI coding agents. SWE Atlas is one step toward a common research framework, testing agents on codebase comprehension, test writing, and complex refactoring in realistic repositories. But broader standardization—across languages, build systems, and project scales—would help developers compare tools meaningfully and understand their failure modes. Publishing detailed metrics on repeatability, cleanup quality, and behavior preservation could give teams clear guardrails for where to trust automated code restructuring and where to keep humans firmly in the loop. For C++ developers wrestling with long build times, undefined behavior, and intricate toolchains, trustworthy benchmarks are especially critical. Only when evaluation data is open, consistent, and aligned with real engineering pain points will developer trust in AI evolve from cautious experimentation to confident, everyday use of code refactoring tools in production environments.