
Why ML Infrastructure Scaling Demands New Architectures
As machine learning moves from isolated experiments to business‑critical systems, infrastructure is straining under new forms of complexity. Enterprises now run hundreds of datasets, feature pipelines, and models that interact across teams and products. Traditional tooling, built around linear pipelines and siloed projects, makes it hard to answer basic questions: where a model came from, which upstream data it depends on, and what breaks when something changes. At the same time, user‑facing AI features demand high‑volume, low‑latency inference and workflows that never lose state, even when services crash. This combination of scale, interconnectedness, and reliability requirements is driving a wave of ML infrastructure scaling efforts. Organisations such as Netflix, Superhuman, and Temporal’s customers are converging on three pillars: graph‑based model lifecycle management, industrial‑grade machine learning inference platforms, and enterprise workflow reliability through durable execution frameworks.
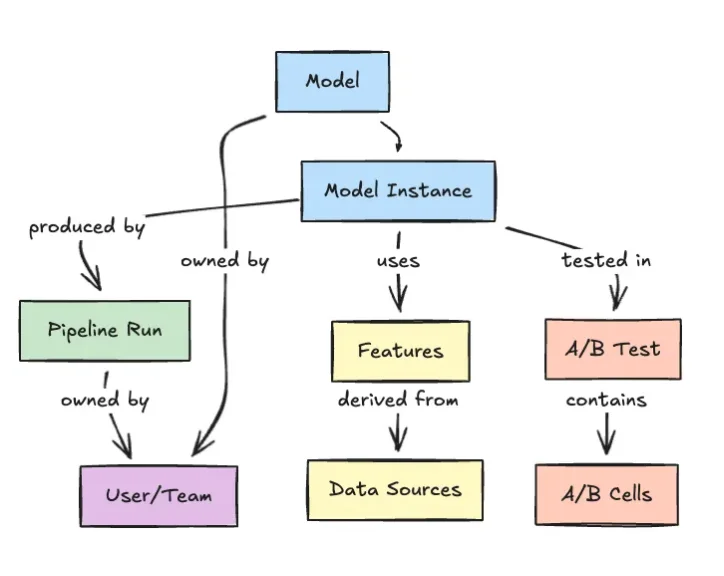
Netflix’s Model Lifecycle Graph: Tackling Dependency Chaos
Netflix is attacking model lifecycle management by treating ML assets and their relationships as a graph instead of a chain of disconnected pipelines. Its internal Model Lifecycle Graph represents datasets, features, models, evaluations, workflows, and production services as interconnected nodes. Engineers can traverse this web to understand lineage, see which upstream data feeds a model, and trace how changes propagate into downstream systems. This graph‑oriented approach directly addresses the sprawl that arises when many teams ship models over time without a shared view of dependencies. By elevating metadata and relationships to first‑class infrastructure concerns, Netflix improves discoverability and governance: teams can locate reusable features or models, inspect how they are assembled, and reason about operational impact before deploying changes. The result is an ML infrastructure scaling pattern where the graph itself becomes the backbone for coordination across the entire machine learning lifecycle.
Superhuman and Databricks: A 200K QPS Machine Learning Inference Platform
Superhuman’s AI‑powered writing assistance must respond in real time as users type across email, documents, and other surfaces. Behind the scenes, a custom large language model provides grammatical correction and stylistic guidance at over 200,000 queries per second, with end‑to‑end p99 latency under one second and strict four‑nines reliability targets. To meet these demands, Superhuman replaced its DIY vLLM‑based stack with Databricks’ model serving, forming a tight engineering partnership rather than a simple vendor relationship. The joint team tackled high‑throughput challenges such as load balancing and autoscaling, adopting an Endpoint Discovery Service and a “power of two choices” routing strategy to avoid hotspots that spike tail latency. This collaboration shows how a modern machine learning inference platform can shoulder capacity planning and performance tuning, freeing lean ML teams to focus on model quality while still hitting aggressive production SLAs at massive scale.
Temporal’s Durable Execution: Making Enterprise Workflows Crash‑Proof
Even with robust graphs and inference platforms, AI systems fail if workflows cannot survive crashes, timeouts, or flaky networks. Temporal addresses this by providing a Durable Execution framework that automatically persists workflow state and replays it after failures, turning ordinary code into crash‑proof workflows. Originating as a fork of Uber’s Cadence engine, Temporal has evolved into a platform used by more than 3,000 paying customers, including Nvidia, Netflix, Snap, and Stripe. Developers define workflows in regular programming languages rather than DSLs, while Temporal transparently manages retries, timeouts, and state transitions. This approach strengthens enterprise workflow reliability for long‑running and distributed AI processes, from data preparation to model orchestration and agent‑like behaviours. By guaranteeing that business processes run to completion without manual intervention, Temporal underpins production‑ready AI systems that can tolerate the messy realities of real‑world infrastructure.

The Emerging Blueprint for Scalable, Reliable ML Systems
Together, Netflix, Superhuman, and Temporal illustrate an emerging blueprint for ML infrastructure scaling. First, represent the entire machine learning lifecycle as a navigable graph so teams can manage dependencies, reuse assets, and understand change impact. Second, invest in a high‑throughput machine learning inference platform that treats latency, load balancing, and autoscaling as shared responsibilities between product teams and platform providers. Third, embed enterprise workflow reliability with durable execution, ensuring that every long‑running AI process can resume after failures without complex manual recovery logic. As organisations adopt these patterns, ML platforms shift from brittle collections of scripts and services to coherent, metadata‑driven systems. The payoff is not just higher throughput or lower latency, but the confidence to ship more ambitious AI features, knowing that models, data, and workflows are all anchored by infrastructure designed explicitly for scale and resilience.