From Coding Assistant to Primary Author
Claude code generation is the practice of using Anthropic’s Claude models as the main author of software, where humans guide requirements, review outputs, and approve merges instead of manually writing most of the code themselves. Anthropic now says Claude writes more than 80% of the code merged into its production systems, turning its own stack into a large, live experiment in AI-built software. According to Anthropic, “Claude wrote more than 80% of the code it merged in May 2026,” and engineers remain responsible for selecting tasks and approving changes. Internally, this has pushed the question away from whether AI can write reliable code and toward how teams manage AI code review at scale. The center of gravity in engineering is moving from typing code to specifying behavior, interpreting diffs, and operating quality gates around AI self-improving systems.
Dynamic Workflows Agents and Parallel Engineering
Anthropic’s new Dynamic Workflows agents turn Claude from a single coding partner into a coordinator of many specialized agents working in parallel. When enabled directly or through the ultracode setting, Claude can plan a complex job, break it into subtasks, spawn multiple agents, and then merge and validate their outputs. This matters for large-scale work such as architecture analysis, security audits, performance reviews, and wide-ranging bug hunts that would overwhelm a single assistant. Progress is saved as the workflow runs, so long jobs can pause and resume without starting over. Developers had been wiring together similar multi-agent setups on their own; Dynamic Workflows formalize those patterns and make them easier to repeat. The result is not just faster code generation, but a form of distributed engineering where orchestration logic is also written by AI, tightening the loop toward self-improving AI systems.

Eightfold AI Productivity Gains—and a New Bottleneck
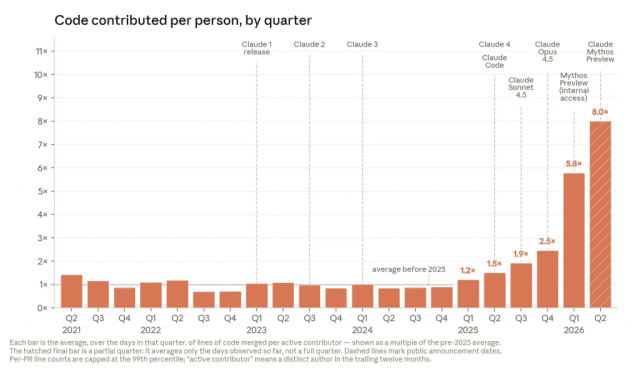
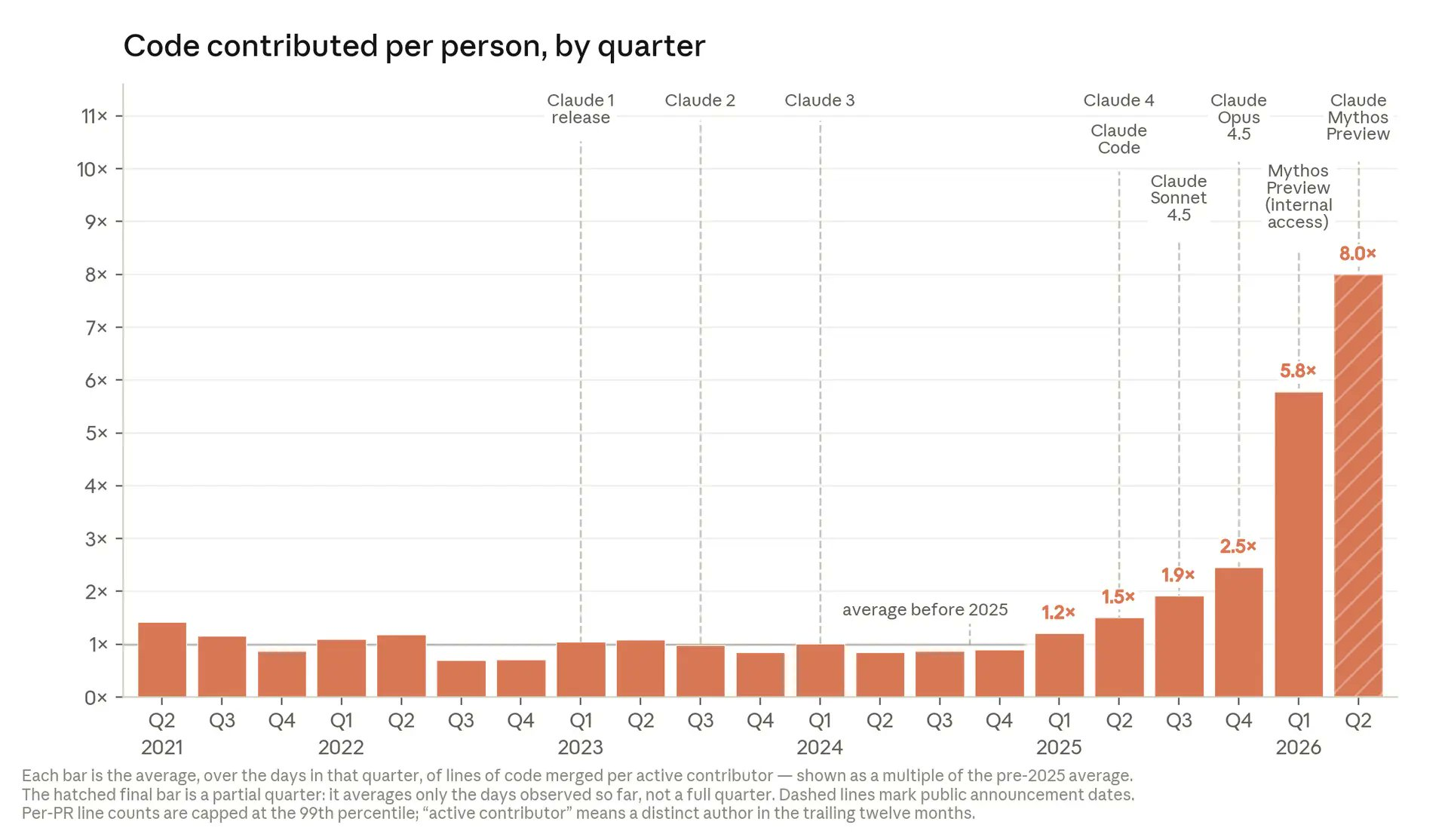
Anthropic’s internal metrics show sharp AI productivity gains rather than mild incremental improvements. The company reports that average lines of code merged per active contributor per day have reached 8x the pre-2025 baseline, with a clear step change aligning to new Claude releases. Earlier years hovered around 1x, then climbed with Claude 4 and Mythos, reaching 5.8x in Q1 2026 and a partial 8x in the most recent quarter. Inside the company, some engineers “stopped opening code editors entirely,” shifting to reviewing Claude’s first drafts instead of writing from scratch. This surge means the bottleneck is no longer how much code can be written but how quickly teams can perform AI code review, run tests, and reason about side effects. Scaling output without equally scaling validation increases the importance of better tools for diff analysis, automated test generation, security checks, and audit trails.
Self-Improving AI: Power and Risk in the Review Loop
As Claude handles more complex tasks and longer engineering cycles, attention is turning to AI self-improving systems and the risks they pose. Anthropic’s own analysis notes that models have progressed from handling four-minute software tasks to work spanning up to 12 hours, and internal charts show Claude-created code rising steeply with Mythos. Claude is already used to find bugs in old code, fix live incidents, and run iterative rewriting loops that can speed up software significantly. Yet Anthropic stresses that full recursive self-improvement—where an AI autonomously changes its own codebase without human approval—remains a future possibility, not today’s reality. Engineers still gate what reaches production. That makes control structures central: audit logs for every AI-authored change, reliable security and regression testing, clear rollback paths, and explicit human sign-off are now the main safety valves preventing a fast, capable system from changing itself in unseen ways.

Rethinking Software Risk in an AI-Dominated Stack
With Claude writing the majority of Anthropic’s production code, software risk management is being rewritten. The dominant failure mode is less about bugs from tired human programmers and more about subtle errors or interactions in large volumes of machine-generated changes. Traditional safeguards—peer review, unit tests, manual QA—do not vanish; they become pressure points that must scale to match AI output. Teams need AI-assisted reviewers, richer static analysis, and targeted tests driven by models that understand the code they helped produce. The enterprise question has moved from “Can we trust AI to generate code?” to “Can our review and quality assurance processes keep up with what the AI produces?” As Dynamic Workflows agents and Claude’s coding skills improve, the path toward self-improving AI will be defined less by raw capability and more by the discipline of the gates that stand between AI-written patches and production systems.





