What Claude Opus 4.8 Is—and How It Fits Anthropic’s Lineup
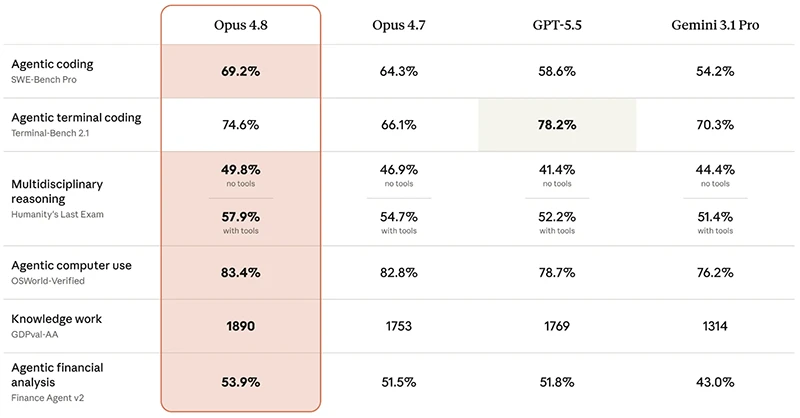
Claude Opus 4.8 is Anthropic’s new flagship Claude model for general availability, offering targeted gains in coding, reasoning, and reliability while staying deliberately below the Mythos-class capability frontier. Positioned as a direct, same-priced upgrade to Opus 4.7, it focuses on better agentic coding, stronger judgement in long and complex tasks, and improved honesty when information is missing or uncertain. Anthropic’s own evaluations show that Opus 4.8 performs better than its predecessor across internal benchmarks that span software engineering, multimodal understanding, and agentic workflows. Yet the company is explicit that Opus 4.8 does not surpass Claude Mythos Preview, the higher-capacity model currently limited to select organizations. That framing makes Opus 4.8 a bridge release: accessible to all customers today, but clearly presented as a step on the Anthropic model roadmap rather than the new long-term peak in capability.
Coding, Reasoning, and Alignment: Targeted Gains Over Opus 4.7
Anthropic frames Claude Opus 4.8 as a practical upgrade for teams that care about dependable code and transparent reasoning. Internal tests cited in multiple model cards indicate consistent improvements over Opus 4.7 in software engineering, reasoning, and agentic tasks. According to Anthropic, Opus 4.8 is “around four times less likely than its predecessor to leave coding issues unmentioned,” and testers found it “more reliable and sharper in its judgement when it’s performing agentic tasks.” This aligns with reported gains in model honesty: Opus 4.8 is more likely to admit when it lacks information and less likely to invent unsupported details. Alignment testing shows lower rates of deceptive behavior than Opus 4.7 and a profile close to Claude Mythos Preview on whether the system follows user interests and instructions, which directly matters for enterprises that need predictable, auditable AI behavior in production workflows.
Dynamic Workflows and Claude Coding Improvements for Enterprise Use
Opus 4.8 also arrives alongside new tooling that highlights Anthropic’s focus on real-world coding and knowledge work. Dynamic Workflows for Claude Code, currently in research preview, let the model break down large software tasks, schedule hundreds of parallel subagents in a single session, and verify outputs before responding. Anthropic says that with Opus 4.8, these subagents can run for longer and handle codebase-scale changes, including migrations across hundreds of thousands of lines of code guided by existing test suites. In parallel, Claude coding improvements emphasize error detection: the model is better at spotting flaws in its own code and is less likely to let subtle problems go unremarked. Enterprises using Claude for refactoring, large-scale maintenance, or multi-agent workflows gain both higher throughput and more reliable guardrails, backed by controls that tune how much effort the model spends balancing speed, depth, and cost per task.
Safety Ceiling: Opus 4.8 Below Mythos on Biological and Cyber Risk
Anthropic’s system card for Claude Opus 4.8 stresses that while capability rises, the safety ceiling stays set by Claude Mythos Preview. On biological-risk tests—including long-form virology tasks, a Virology Capabilities Test, and DNA Synthesis Screening Evasion—Opus 4.8 often scores lower than Mythos Preview where lower numbers indicate safer behavior. For instance, Opus 4.8 scores 0.30 on one DNA Synthesis Screening Evasion criterion compared with 0.842 for Mythos Preview, showing less ability to bypass screening. On virology capabilities it scores 0.470 versus 0.574. Anthropic concludes that Opus 4.8 “does not advance the capability frontier beyond our most capable model,” so it does not trigger a new tier under its Responsible Scaling Policy. On cyber tasks, Opus 4.8 is somewhat more capable than Opus 4.7 when unsafeguarded but similar once guardrails are applied, and still weaker than Mythos Preview, which remains the higher-risk, higher-capacity system.
Mythos-Class Rollout and the Dual-Tier Anthropic Model Roadmap
Beyond the immediate upgrade, Anthropic is signaling how Claude Opus 4.8 and Mythos-class models will coexist for enterprises. Mythos AI models, currently tested with a limited set of organizations under Project Glasswing, are described as a new class that will surpass Opus in intelligence. Anthropic plans to make Mythos-class models available to all customers in the coming weeks, contingent on additional cyber safeguards. This creates a dual-tier release strategy: Opus 4.8 as the widely accessible, safety-bounded workhorse, and Mythos as a higher ceiling reserved for customers prepared for greater power and risk controls. For enterprise adoption, that split manages expectations: teams can standardize on Opus 4.8 today, knowing it improves coding and reasoning without raising the catastrophic risk ceiling, while planning pilots or specialized workloads on Mythos once Anthropic’s broader safeguards and policies are in place.





