AI Co-Scientists Promise Help at the Bench, But Trust Lags
AI co-scientists are software systems that combine large language models with scientific data and lab automation tools to propose experiments, coordinate workflows, and interpret results alongside human researchers in wet lab environments. Today, that promise is still more marketing than reality inside most labs. The Pistoia Alliance’s survey of life science leaders found that while 54% see AI delivering value in regulatory submissions and reporting, only 1% report value in the wet lab. Scientists trust life science AI when it helps with documents, but they hesitate when models start to influence pipettes, assays, and purchasing decisions. The gap reflects a core design problem for wet lab AI integration: how to tie generative models, which excel at text and code, to the highly constrained, measurable world of physical experiments without introducing unacceptable risk.

Two Stack Philosophies: LLM-First vs Lab-Data-First
Vendors are splitting into two main architectural camps as they try to build trustworthy AI co-scientists. One side, including efforts like Google DeepMind’s Co-Scientist and OpenAI’s GPT-Rosalind, starts from powerful, general-purpose reasoning engines that plug into existing computational pipelines. Their bet is that stronger models, arranged as debating agents or domain-tuned reasoning systems, will earn trust by giving better hypotheses and analyses. The other camp begins with lab data systems and electronic lab notebooks, then threads AI into those environments. Traditional ELN providers and newer platforms in life science AI treat the LLM as a service within a controlled data backbone, not the center of the stack. This approach prioritizes data grounding, audit trails, and alignment with how scientists already log experiments, hoping to make wet lab AI integration feel like an extension of existing workflows rather than a foreign brain.

Sapio and Potato: Agents Wrapped Around Lab Systems
Sapio Sciences offers a clear example of an ELN-anchored approach. Its Elain agent plugs Anthropic’s Claude into Sapio’s electronic lab notebook through the Model Context Protocol, turning what began as a chat box into a cross-system AI co-scientist. Rob Brown from Sapio notes he no longer clicks through complex query builders because natural language and voice are faster, yet his work remains grounded in the ELN’s schemas and permissions. Similar startups, including those building “connective tissue” across fragmented pharma tools, focus on agents that orchestrate emails, protocols, and lab databases rather than control hardware outright. A strict human-in-the-loop rule still applies: according to the Pistoia Alliance’s Christian Baber, transformer outputs are drafts that require review before they touch any external system that matters. Here, trust comes from containment and traceability more than from the model’s raw intelligence.

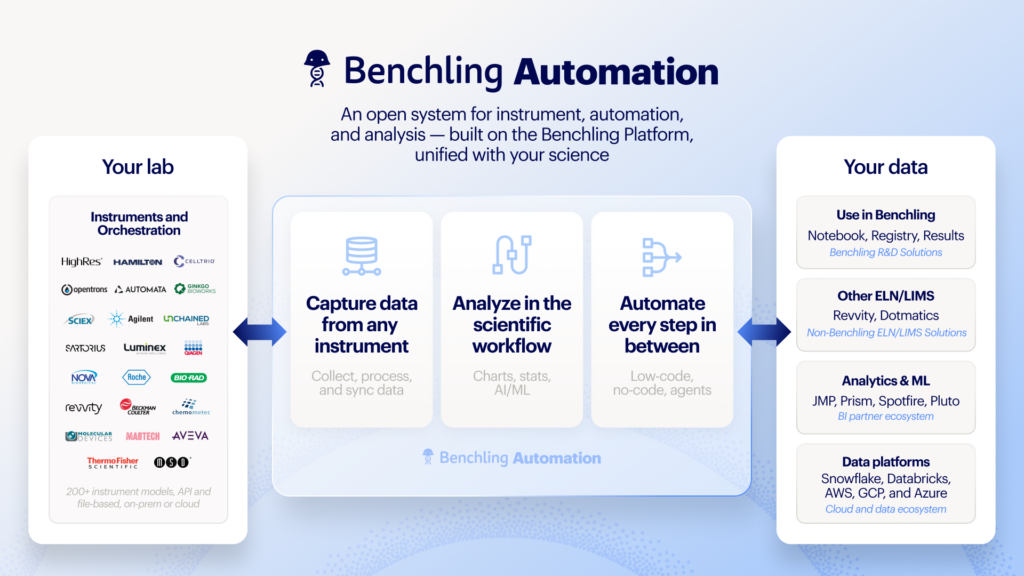
Benchling’s Lab Automation Bet: Make AI Touch the Wet Lab
Benchling is pushing in a different direction: tying AI co-scientists to lab automation so they can influence real experiments while remaining accountable to physical results. Co-founder Ashu Singhal argues that science “has to happen in the physical world,” and Benchling’s architecture connects model outputs to ordering APIs, workcells, and contract research organizations. The platform’s one-click ordering with partners such as Twist Bioscience, Adaptyv, and Ginkgo Bioworks, plus its Model Hub and automation tools, aim to shrink the distance between design and execution. By routing AI-generated protocols into systems that place reagent orders, schedule runs, and collect data back into Benchling, the company wants every AI suggestion to be testable against measured outcomes. If the experiment fails, the AI co-scientist is wrong in a concrete way, which over time could deepen trust more than abstract reasoning benchmarks.

Closing the Trust Gap: Grounding, Guardrails, and Measurable Wins
Despite a surge of products branded as AI co-scientists, most life science teams still see more risk than reward at the bench. The path to trust appears to run through three design principles. First, data grounding: vendors that anchor models in structured ELNs, lab automation logs, and assay results give scientists a way to inspect and reproduce AI-driven decisions. Second, guardrails: from Baber’s “no direct model-to-agency” rule to Benchling’s controlled pipelines, human review remains a non-negotiable stage. Third, measurable wet lab outcomes: platforms that tie suggestions to real experiments, costs, and timelines can prove value rather than promise it. As vendors refine these architectural trade-offs—LLM capability versus tight lab integration—the winning AI co-scientists will likely be those that feel less like black boxes and more like accountable, testable members of the research team.





