
What MiniMax M3 Is and Why Its Long Context Matters
MiniMax M3 is a long-context, multimodal language model built to power coding AI agents that can work across large codebases, documents, and visual inputs over extended sessions. Instead of targeting casual chat, M3 focuses on supporting developers who need a model to read, modify, and verify code while keeping long-running context in memory. The headline MiniMax M3 features include a one-million-token context window with a guaranteed minimum of 512,000 tokens, far beyond typical chatbot sessions, and native support for text, image, and video input with text output. By pairing this scale of working memory with coding-oriented behavior, M3 aims to sit inside real developer workflows, such as repository-wide refactors or multi-step automation tasks, without constantly losing track of earlier steps or forcing teams to slice work into tiny prompts.
MiniMax Sparse Attention and the Cost of Long-Context AI Models
Long-context AI models often run into a simple problem: the larger the prompt, the more time and compute each token costs. MiniMax frames M3 as an answer to that bottleneck. The model uses a Grouped-Query Attention backbone with MiniMax Sparse Attention, which it says cuts per-token compute at the one-million-token level to one-twentieth of the prior generation and brings more than 9 times faster prefilling and over 15 times faster decoding compared with M2. These design choices matter for coding AI agents that may need to scan hundreds of thousands of tokens of source code or logs before acting. If those latency and efficiency gains hold up in independent tests, they could make long-context coding sessions practical instead of prohibitively slow or expensive, closing the gap between marketing claims and everyday developer use.
Multimodal Language Models and Richer Coding Contexts
M3 is a multimodal language model that supports text, images, and video as input with text output, and this native multimodal support is tightly connected to its coding focus. Teams routinely juggle source files, architecture diagrams, UI screenshots, and even demo videos when they debug or design features. With M3, much of that material can flow through one model instead of separate tools. According to MiniMax’s launch materials, developers can reach the model via OpenAI-compatible endpoints, making it easier to slot into existing agent frameworks. The company also links M3 to MiniMax Code, a coding agent interface that can break work into multi-stage workflows, use producer–verifier loops, and drive computer use through M3’s multimodal capabilities. That combination moves M3 beyond static code completion into the realm of agents that interpret visual context and act across applications.
Benchmark Claims and the Emerging Agent Benchmark Landscape
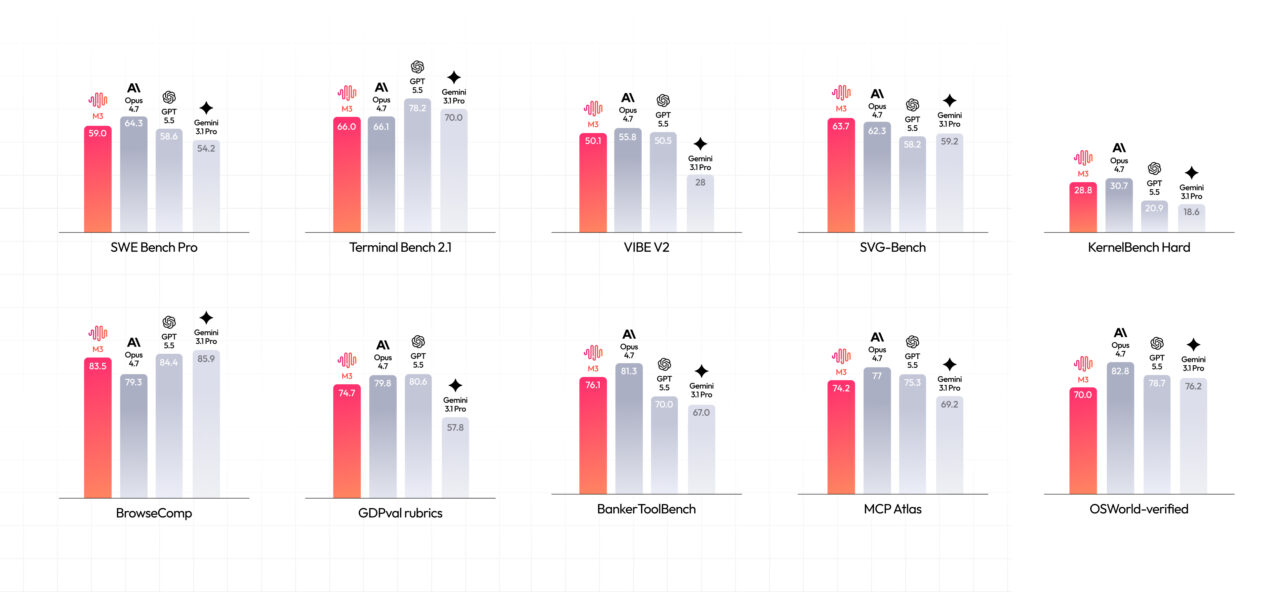
MiniMax M3 enters a competitive field where long-context AI models are judged less by generic fluency and more by how well they behave as coding AI agents. MiniMax reports that M3 scores 59.0% on SWE-Bench Pro, 66.0% on Terminal-Bench 2.1, 34.8% on SWE-fficiency, 28.8% on KernelBench Hard, and 74.2% on MCP Atlas, and says it beats GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro while approaching Claude Opus 4.7. The lab also claims a top score on Claw-Eval, an end-to-end autonomous agent benchmark. These results were often run on MiniMax infrastructure with agent scaffolding such as Claude Code, Mini-SWE-Agent, or Terminus, so buyers should wait for independent runs and the promised open-weight release. Meanwhile, newer benchmarks like DeepSWE are shifting attention toward long-horizon, multi-file software engineering tasks that better match M3’s design goals.
Positioning Against Frontier Models for Coding and Agent Development
Strategically, M3 is MiniMax’s bid to stand alongside leading long-context AI models from major labs and become part of the daily developer stack. It is released as a broader long-context AI package, not a standalone demo: hosted access through MiniMax Code, OpenAI-compatible API endpoints, and a promised open-weight model are all part of the offer. For engineering teams, the practical question is whether M3 can read the right files, make precise multi-file edits, verify its work, and stop without generating extra cleanup. Early access via code.minimax.io gives teams a way to probe latency, tool use, and agent behavior before they rely on it for production workflows. If outside evaluations validate MiniMax M3 features such as its one-million-token window, multimodal handling, and efficiency claims, M3 could become a serious option for building autonomous coding agents and long-running developer tools.





