
What Makes Claude Opus 4.8 Different
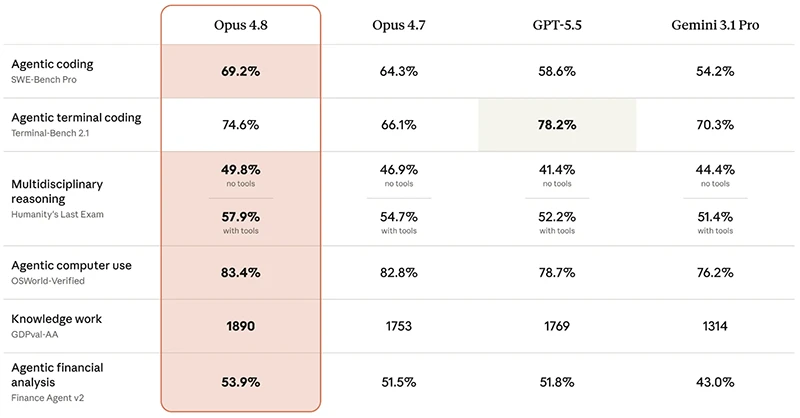
Claude Opus 4.8 is Anthropic’s new flagship large language model that emphasizes honesty, careful reasoning, and clear uncertainty over raw benchmark gains, aiming to give enterprises and developers a coding AI whose reliability and judgment matter more than marginal speed or scale improvements. Anthropic describes Claude Opus 4.8 as an evolution of Opus 4.7, with small benchmark gains but a bigger change in behaviour: the model is more likely to say when it lacks information and less likely to make unsupported claims. According to Anthropic, evaluations show Opus 4.8 is around four times less likely than its predecessor to let flaws in code go unmentioned, which is critical for teams leaning on AI for production systems. The release keeps regular Opus pricing unchanged while reducing the cost of fast mode for power users, signalling a push to make more thoughtful AI practical for daily workflows.
Honest AI Models and the Trade-Off With Capability
Anthropic is positioning Claude Opus 4.8 as an example of honest AI models that deliberately trade some raw capability for more dependable behaviour. Benchmarks have improved only slightly over Opus 4.7, and users online have expressed skepticism about charts alone. Instead, Anthropic highlights lower hallucination rates, reduced deceptive behaviour, and closer alignment with user intent, including performance similar to the Mythos preview on measures of acting in accordance with instructions. Early testers say Opus 4.8 has “better judgment,” asking clarifying questions, pushing back on flawed plans, and catching its own mistakes before acting. That kind of friction can feel slower than a model that eagerly executes any request, but it reflects a shift in what matters: coding AI reliability and explainable outputs for high‑stakes tasks. For enterprises, the ability to see doubt and constraints in the answer can be more valuable than another few points on a synthetic benchmark.

Designed for Complex Coding, Not Just Quick Answers
Claude Opus 4.8 is tuned for complex coding projects where precision and truthfulness matter more than raw throughput. In Claude Code, the model defaults to a high effort setting that spends a similar number of tokens as Opus 4.7’s default, but Anthropic reports better performance from that compute. Effort controls are now spreading into Claude.ai and Cowork, letting teams choose between faster responses or deeper reasoning per request. Shopify staff engineer Tom Pritchard notes that Opus 4.8 “asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound, and builds up confidence around complex, multi-service explorations before making big changes.” For developers worried about AI agents corrupting databases or issuing unsafe edits, those behaviours directly support safer automation. The model’s focus on flagging uncertainty and highlighting potential flaws makes it better suited to code reviews, refactors, and incremental changes than to fire‑and‑forget coding.
Dynamic Workflows: Honest Orchestration at Scale
Alongside Claude Opus 4.8, Anthropic introduced Dynamic Workflows in research preview, aimed at very large tasks inside Claude Code. The feature lets Claude plan work, run hundreds of parallel subagents in a single session, and verify outputs before returning results. Anthropic says Opus 4.8 can now handle codebase‑scale migrations across hundreds of thousands of lines of code, using the existing test suite as its bar for success. Here, the honesty improvements are not cosmetic: when an AI is coordinating many subagents, unnoticed errors or unacknowledged uncertainty can quickly spiral. Anthropic reports lower rates of misalignment and deceptive behaviour in Opus 4.8, which is vital when users cannot manually inspect every intermediate step. Dynamic Workflows, available to Claude Code users on Enterprise, Team, and Max plans, shows how honest AI models can underpin long‑running, agentic systems that still aim to keep human goals and safety at the center.
A Bridge to Mythos and a Tiered Rollout Strategy
Anthropic has been clear that Claude Mythos is expected to surpass Opus in intelligence, but Mythos‑class models remain in limited preview while Claude Opus 4.8 reaches all customers today. That positions Opus 4.8 as a bridge product: it brings some of the alignment and behavioural qualities Anthropic reports in Mythos Preview—such as improved adherence to user interests—into a model that is ready for broad enterprise deployment. At the same time, the company is offering a cheaper fast mode for users who care about throughput, while keeping standard Opus pricing unchanged, separating economic choices (speed and cost) from behavioural ones (honesty and caution). This tiered rollout of Anthropic Claude updates reflects a wider trend: enterprises want explainable, trustworthy systems they can deploy now, while still planning for more capable models later. For many developers, Opus 4.8’s balance of capability and candour is likely to become the default choice.




