What ‘Claude ADHD mode’ Is—and What It Claims to Do
Claude ADHD mode refers to a third-party reasoning layer for Claude-based coding agents that spawns many parallel thought paths, evaluates them, and continues only the strongest lines of reasoning, aiming to improve planning, trap detection, and architectural decisions before any code is written. Solo researcher Udit Akhouri introduced the ADHD skill for the Claude Agent SDK on Reddit with the claim that it makes Claude Code “think 2x better.” On GitHub and in his paper, he describes the method as “tree-of-thought with cognitive-frame branching, generator-critic separation, and pruning.” Instead of speeding up code writing, he positions it as a reasoning and planning layer that explores multiple cognitive frames, scores branches, prunes weak ideas, and deepens promising ones. Early interest is high—GitHub shows rising stars and forks—but the bold “2x” AI reasoning improvement headline has triggered fresh debate about how new AI agent behaviors should be validated.

How the ADHD-inspired Pattern Tries to Improve AI Reasoning
Under the hood, Claude ADHD mode resembles structured “tree-of-thought” prompting but adds explicit branching by cognitive frame and a clearer separation between idea generation and criticism. The system fans out several divergent reasoning traces in parallel and then uses a critic step to score each branch on dimensions like breadth, novelty, trap detection, and actionability. Only the top-scoring branches survive for deeper expansion. Akhouri says the inspiration came from ADHD-style thinking: highly divergent ideation with selective deep focus, used here as a metaphor rather than a neuroscience claim. Some experts say the mechanism is not brand-new but a familiar pattern. As Sean Robinson notes, it looks like parallel sampling and selection, similar to behaviors in GPT Pro or agent teams, but made more transparent and composable inside the Claude environment. That framing matters, because users can inspect and adapt the reasoning pattern instead of relying on a closed, opaque workflow.
Do the Benchmarks Prove a 2x AI Reasoning Improvement?
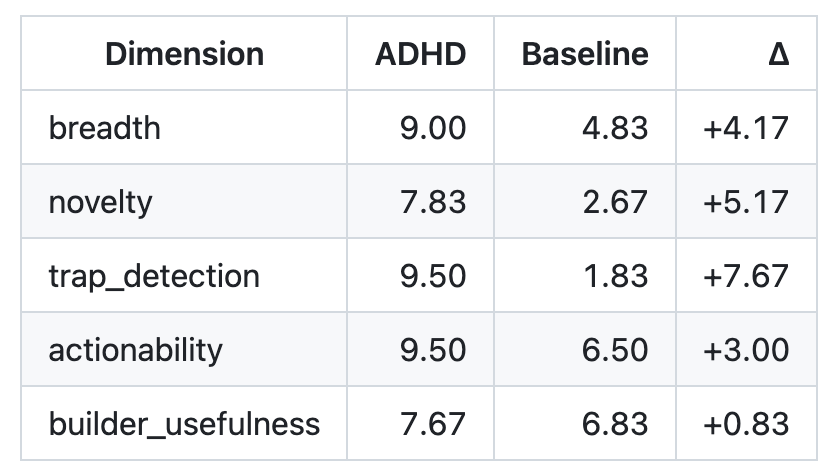
Akhouri bases the “2x better” claim on six engineering-style evaluation problems, where Claude with ADHD reportedly outscored the baseline on five tasks across several rubric dimensions. The GitHub rubric shows deltas of +4.17 for breadth, +5.17 for novelty, +7.67 for trap_detection, +3.00 for actionability, and +0.83 for builder_usefulness. These scores are averaged into the “2x” headline, but trap detection’s large gain heavily pulls the average; removing that metric drops the mean multiplier from 2.52x to 1.85x. Outside experts see the results as interesting but early. Robinson argues that “a ‘2x better’ claim needs more than a few open-ended wins. It needs a validated evaluation set, multiple judges, ablations, and evidence that the method improves without just rewarding verbosity, novelty, or branch diversity.” Questions also remain about possible same-stack bias, since a Claude-family model helped judge a Claude-based method.
Skepticism, Token Costs, and the Need for Independent Claude Benchmark Testing
Beyond the headline numbers, researchers are asking how sustainable and general the approach is. ADHD mode is another exploration layer on top of large language models, which already face token-consumption concerns. As Nikolaos Vasiloglou points out, organizations are suffering from excessive token spending, and more parallel branches mean more tokens. Others question the stability of the findings themselves. Noe Ramos notes that, without established inter-rater reliability, the reported gains in trap detection and novelty are “interesting but not yet stable findings.” Experts also emphasize that external judges and other model families should be used to check whether improvements generalize beyond Claude’s own stack. Until larger, more diverse Claude benchmark testing is done—with independent labs, standardized task suites, and clear ablation studies—ADHD mode should be treated as an experimental AI feature, not a proven upgrade to reasoning performance.
Why AI Feature Validation Matters Before Adoption
The fast uptake of Claude ADHD mode—GitHub stars, early integrations like Repowire, and lively Reddit discussion—highlights a broader tension in AI development: new agent patterns spread faster than they are validated. For builders, a method that seems to unlock better brainstorming, planning, or trap detection is tempting to adopt immediately, especially when framed as making Claude “think 2x better.” Yet experts stress that such claims demand rigorous AI feature validation: larger benchmark suites, multiple independent judges, cross-model comparisons, and careful control experiments to separate genuine reasoning gains from side effects like verbosity or branch diversity. There is also a cultural dimension to naming tools after clinical conditions, which Anthropic has not publicly addressed. For now, ADHD mode is an intriguing experiment in structured parallel reasoning—but responsible teams will test it thoroughly in their own workflows before treating it as a reliable upgrade.





