Why Padding Wastes So Much GPU Work in LLM Inference
Hardware-aware sequence packing is a set of LLM inference optimization techniques that rearrange variable-length token sequences to minimize padding, reduce wasted GPU compute and bandwidth, and keep matrix shapes aligned with the underlying hardware’s preferred tile sizes during production deployments. In typical transformer pipelines, variable-length prompts are padded up to the longest sequence in the batch so that tensors form neat rectangles. The GPU then performs attention and feed-forward operations on thousands of dummy padding tokens, burning compute and memory bandwidth on zeros while real tokens occupy only a fraction of the work. This hurts GPU memory efficiency and makes scaling harder, especially when a single long request forces every other request in the batch to match its length. Reducing that padding overhead is the fastest way to gain throughput without changing the model, and it lays the groundwork for more advanced sequence packing techniques and hardware-aware scheduling strategies.
From Rectangles to Ribbons: Sequence Packing Techniques
Instead of padding every sequence to the maximum length, sequence packing techniques concatenate many sequences into a single one-dimensional ribbon of tokens and rely on variable-length attention kernels to keep document boundaries separate. Modern kernels such as FlashAttention-2’s varlen functions compute attention only where real tokens exist, so padded zeros disappear from the hot path. The remaining challenge is organizational: deciding which sequences share a ribbon, how long each ribbon should be, and when to send it to the GPU. A common approach is first-fit decreasing bin packing, where sequences are sorted by length and placed into bins up to a token budget, much like filling a suitcase with large items first and smaller ones in the gaps. This transforms ragged traffic into dense workloads and sharply cuts padding, which directly improves LLM inference optimization outcomes and GPU memory efficiency under real latency constraints.
Making Sequence Packing Hardware-Aware Instead of Abstract
Hardware-aware scheduling means treating the GPU’s tensor cores and memory system as first-class constraints when designing your sequence packing logic. NVIDIA tensor cores operate on fixed matrix tile shapes, and many high-performance kernels reach peak efficiency when sequence dimensions are multiples of small factors such as 8 or 16. In practice, this means rounding sequence lengths up to the nearest alignment boundary before bin packing, so that attention and GEMM kernels see shapes that map cleanly to warp and tile layouts. This tiny amount of controlled internal padding trades a few tokens for better occupancy, memory coalescing, and reduced divergence. Another hardware-aware consideration is VRAM capacity: the real usable token budget depends on model size, activation and KV-cache footprint, allocator fragmentation, and transient buffers, so it has to be probed empirically. Together, these choices turn generic bin packing into a GPU-specific sequence packing strategy.
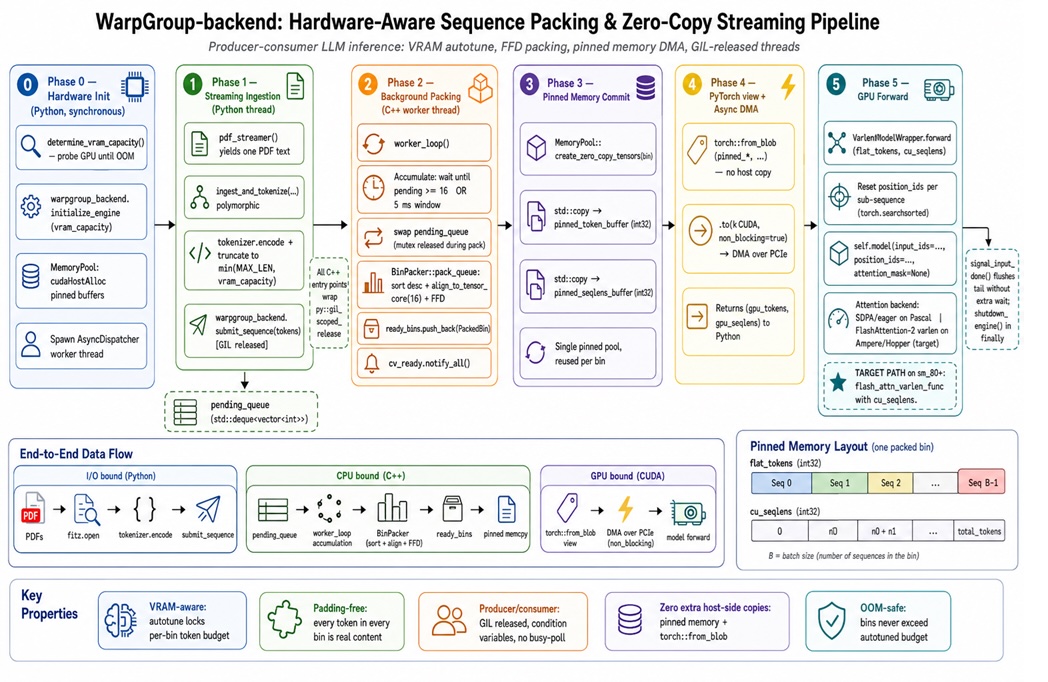
Why C++ Backends Beat High-Level Frameworks in the Hot Loop
Padding-aware batching logic often becomes a bottleneck when written in Python, because the interpreter and its global lock limit parallelism between tokenization, scheduling, and GPU feeding. By moving the sequence-packing core into a C++ backend, you can release the Python GIL, run packing in background threads, and keep the GPU fed without stalls. According to the WarpGroup-Backend report, replacing conventional padding-heavy batching with a C++ packing engine improved throughput up to 2.08× on an H100 and up to 5.89× on a GTX 1080 while avoiding out-of-memory crashes. A C++ backend also gives fine-grained control over pinned-memory DMA transfers, async queues, and VRAM-aware bin sizing, which high-level frameworks tend to abstract away. For production inference workloads that run around the clock, these low-level gains compound, and every percentage point of efficiency reclaimed from padding overhead directly reduces latency and GPU hours.
Designing a Production-Ready Hardware-Aware Packing Pipeline
A practical production pipeline for hardware-aware sequence packing starts by measuring the maximum token capacity the GPU can sustain without out-of-memory errors and then backing off for safety. Next, a Python layer focuses on tokenization and high-level orchestration, while C++ components manage thread-safe queues and perform length alignment, bin packing, and GPU scheduling. Each bin aggregates many variable-length sequences up to the measured token budget, aligned to hardware-friendly sizes, then streams them to the GPU via pinned-memory transfers that overlap I/O and compute. Variable-length attention kernels process these dense ribbons without inter-sequence interference, and the results are mapped back to original requests. The outcome is a repeatable pattern for LLM inference optimization that combines VRAM-aware bin packing, hardware-aware scheduling, and low-overhead data movement to maximize throughput and GPU memory efficiency in demanding, latency-sensitive deployments.





