What LLM Inference Optimization Means (And Why Padding Is Killing You)
LLM inference optimization is the process of reshaping how large language models run on GPUs so that nearly every floating-point operation advances real tokens instead of wasted padding, redundant prefills, or poorly scheduled batches, giving higher token generation speed and lower costs without retraining the model or rewriting your entire stack. In most standard backends, variable-length prompts are padded to match the longest sequence in a batch, turning ragged text into neat rectangles that GPUs like, but this comes at a high price: your GPU performs billions of multiplications on zeros that never affect the output. WarpGroup-style backends expose how much of your "work" is fake, and why VRAM-aware bin packing now matters as much as model choice. Once you see padding as an accounting bug, not a technical necessity, hardware-aware fixes become obvious and measurable.
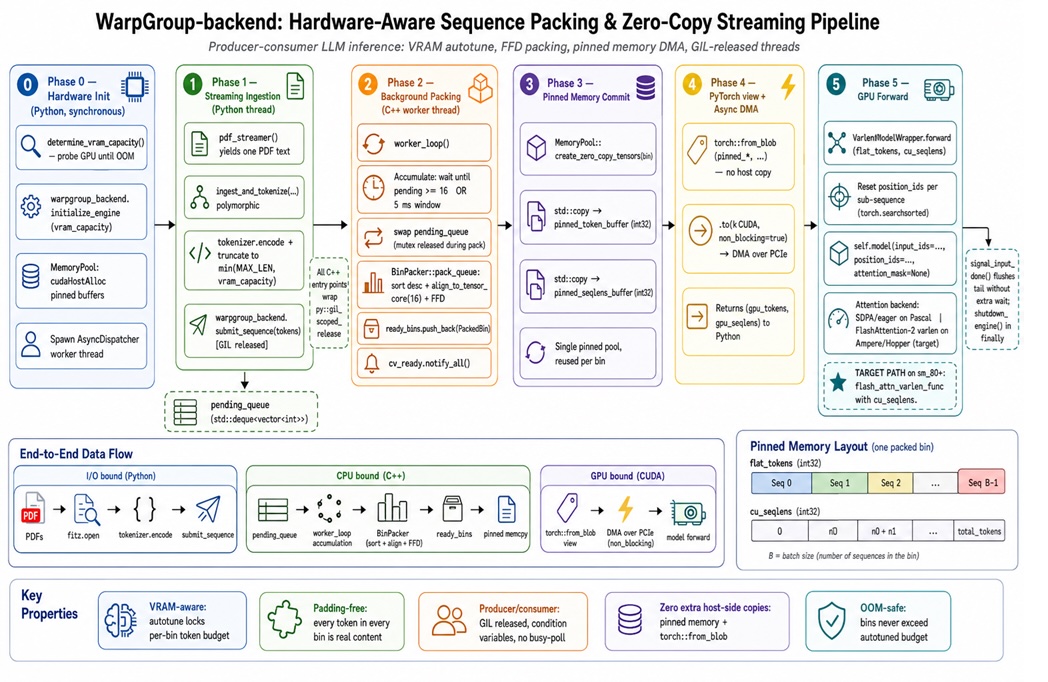
Sequence Packing: Stop Paying for Empty Tokens
The sequence packing technique replaces naive rectangular padding with a GPU-friendly "token ribbon". Instead of padding every prompt to the longest length, you concatenate variable-length sequences into one continuous buffer and track boundaries so attention never crosses between documents. This keeps GPU memory efficiency high while eliminating padding overhead. In effect, you replace an 8×2000 padded batch with a packed batch that might only hold, say, 5,000 real tokens instead of 16,000 padded ones. A C++ bin-packing engine can automate this by filling length-constrained "bins" up to a token budget, similar to First-Fit Decreasing scheduling. The result is fewer wasted compute cycles and higher LLM inference optimization gains: one WarpGroup-style backend reports up to 2.08× throughput on an H100 and 5.89× on a GTX 1080 by packing sequences instead of padding them.

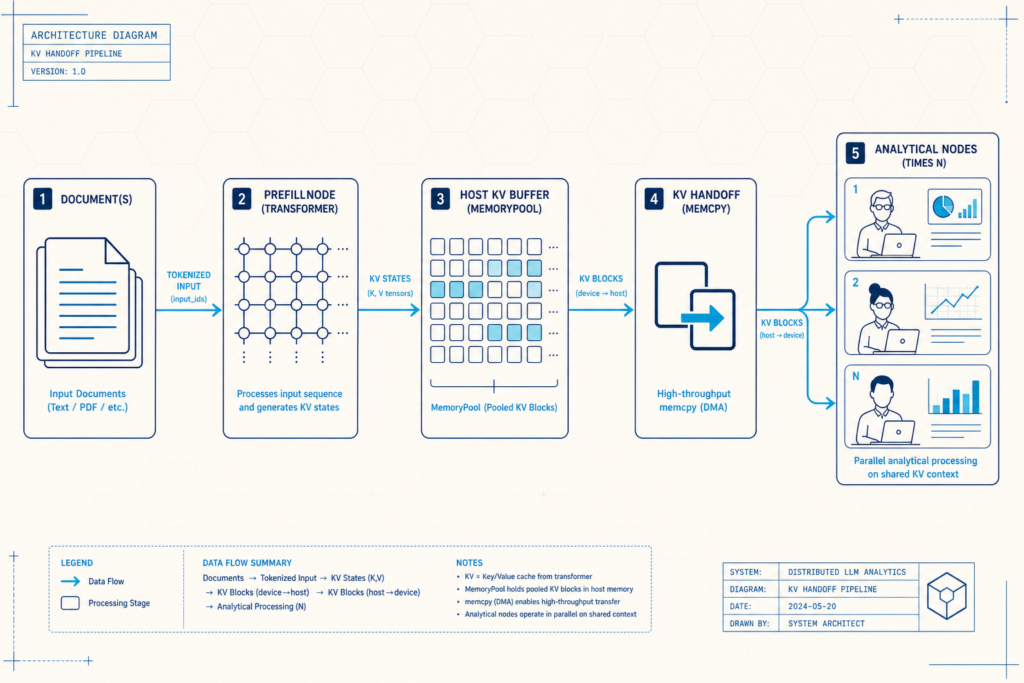
KV Cache Optimization: Prefill Once, Fan Out to Many Agents
Multi-agent and multi-branch pipelines often waste most of their budget on redundant prefill. Each agent reads the same long context, re-running the dense attention pass and rebuilding identical KV cache state. KV cache optimization fixes this with snapshot sharing: run prefill once, serialize the KV cache to a host buffer, copy it for each branch, then restore it before decoding. SwarmKV shows this "compute once, fan out" pattern in practice: on a seven-year-old GTX 1080, a two-agent pipeline became about 1.95× faster end to end, and the second branch’s activation latency dropped by roughly 52×. Because the prefix computation scales quadratically with sequence length but KV copies scale linearly, even a full serialize–memcpy–restore loop beats recomputing. This prevents GPUs from "reading the same document twice" and frees capacity for more useful tokens.
Hitting 1,000+ Tokens per Second on Everyday GPUs
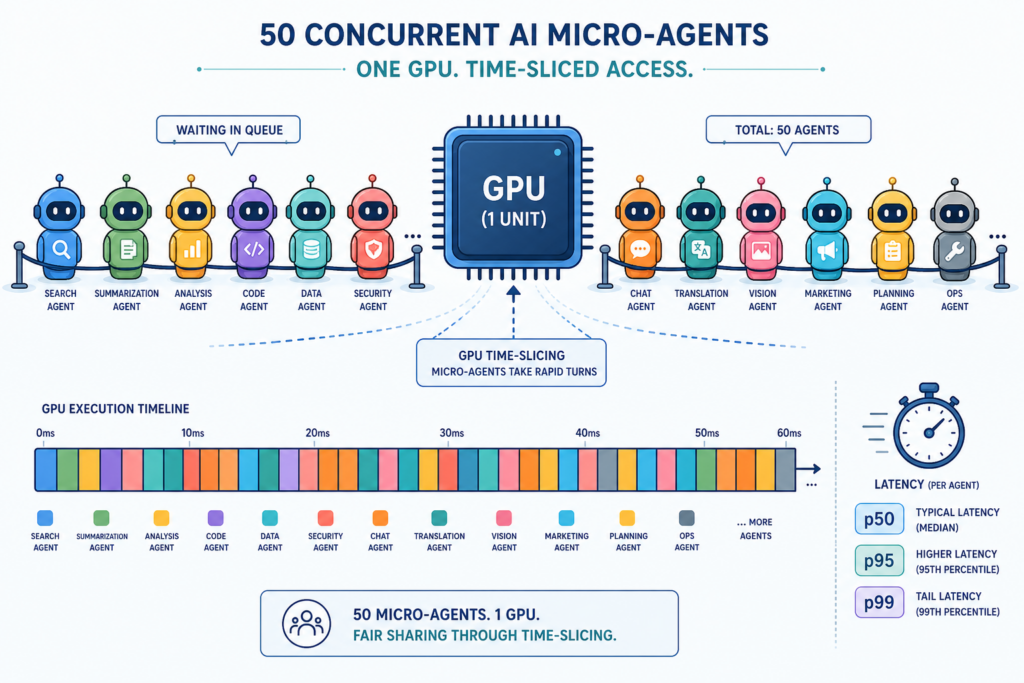
Hardware-aware optimization is not theory; production systems already show the ceiling. Xiaomi’s MiMo-V2.5-Pro UltraSpeed mode, co-designed with TileRT, breaks the 1,000 tokens-per-second barrier on general-purpose GPUs, around ten times faster than standard MiMo-V2.5-Pro API access and far above the earlier MiMo-V2-Flash model’s 150 tokens per second. These figures line up with what optimized open backends achieve when they combine sequence packing, KV cache optimization, pinned-memory transfers, and smart scheduling. The shared pattern is clear: avoid doing the same dense attention twice, avoid padding tokens you never read, and keep the GPU fed with tightly packed, VRAM-aware workloads. You do not need to redesign your infrastructure or change model architectures to benefit; most gains come from how you batch, pack, cache, and copy data around the GPU.
Putting It All Together Without Rebuilding Your Stack
You can fold these ideas into your existing stack in stages. Start with sequence packing to reclaim GPU memory efficiency: switch from rectangular padding to variable-length attention where your backend supports it, or add a bin-packing pre-processor that builds packed ribbons before calling your existing kernels. Next, introduce KV cache snapshot sharing in any place where multiple agents or branches read the same prefix; treat prefill as a shared asset instead of a per-agent cost. Finally, upgrade your orchestration: use pinned host buffers for faster transfers and group requests by similar lengths or cache hits so the GPU spends more time decoding and less time context switching. Together, these techniques often deliver 3× faster search-like workloads and about 2× faster answer generation, with no quality loss and no need for wholesale infrastructure reconfiguration.





