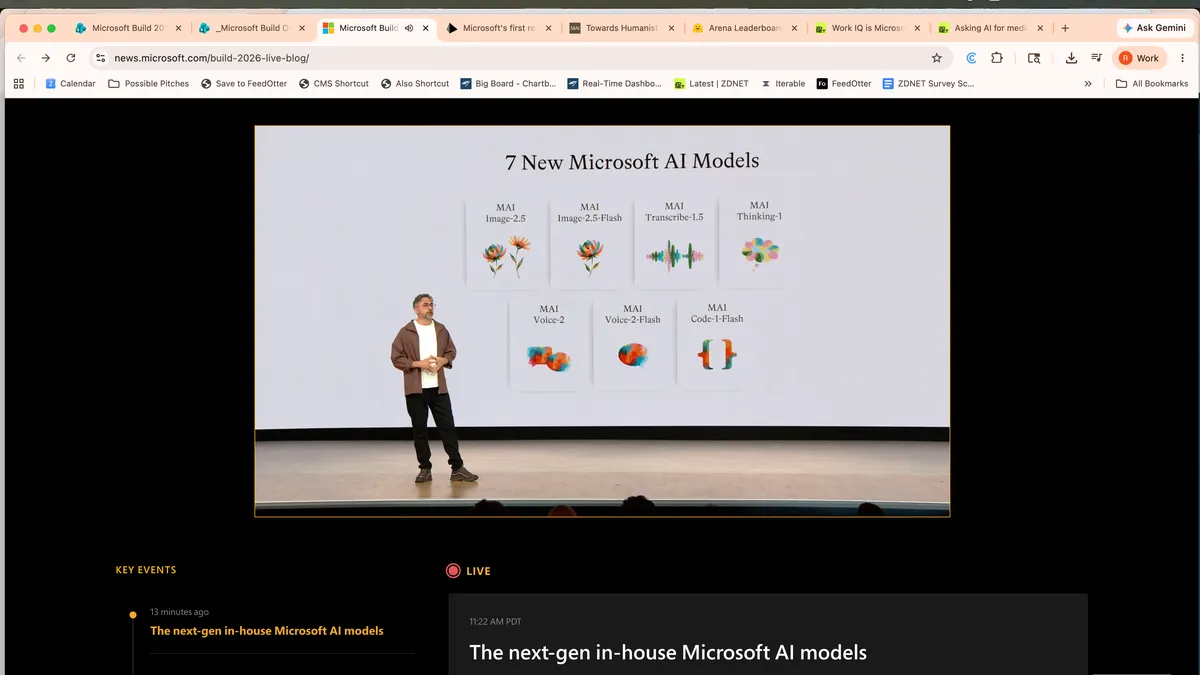
What the New MAI Models from Microsoft Aim to Do
Microsoft’s new MAI models are a family of in-house AI systems spanning reasoning, coding, image generation, transcription, and voice, designed to give enterprises alternatives to third‑party large language and media models while promising cleaner data lineage, better cost efficiency, and deeper integration with Microsoft’s existing developer and productivity tools. At Microsoft Build 2026 AI announcements, the company launched seven MAI models, including its first reasoning model MAI‑Thinking‑1, coding‑focused MAI‑Code‑1, image‑generation pair MAI‑Image‑2.5 and 2.5 Flash, plus updated voice and transcription lines. Microsoft positions these MAI models as “enterprise‑grade” and emphasizes agentic AI, multi‑step task handling, and GitHub and Copilot integration. My testing focused on whether those MAI models Microsoft released feel ready for production use in real developer workflows, and whether they deliver on the promises of enterprise AI reasoning, competitive AI image generation benchmark results, and efficient code assistance.

Reasoning and Coding: Enterprise AI That Still Feels Experimental
MAI‑Thinking‑1 is sold as Microsoft’s first enterprise AI reasoning model, tuned for multi‑step tasks and available in Foundry in private preview. Microsoft says independent reviewers preferred it over Anthropic Claude Sonnet 4.61 in a blind test, and that it matches Anthropic Opus 4.6 on SWE Bench Pro coding scores. In practice, early hands‑on tests suggest the gap between benchmarks and experience is wide. PCMag reports that Sonnet, even at medium intelligence, felt more useful than MAI‑Thinking‑1 for complex game questions and database design, with no clear gains in accuracy or speed and no internet access at all. MAI‑Code‑1 is described as “ultra‑efficient” and tuned for GitHub, with rollouts to Copilot and VS Code, but Microsoft has shared little about latency, context length, or debugging quality. For now, MAI reasoning and coding look promising on paper yet unfinished for demanding production environments.
MAI-Image-2.5: Benchmark Winner, Mixed Real-World Usability
AI image generation benchmark slides at Build put MAI‑Image‑2.5 in a strong position. Microsoft says it outperformed Google’s Nano Banana Pro in internal comparisons, and CNET notes that MAI‑Image‑2.5 and its Flash variant target “maximum fidelity and professional‑grade performance” versus ultra‑fast production use. In tools like PowerPoint and OneDrive, I found the model’s strengths aligned with this pitch: detail, consistency across variations, and precise object‑level edits were solid. However, the gap between curated demos and daily workflows is noticeable. Complex brand‑style prompts still required several retries, text rendering remained unreliable, and the Flash model sometimes traded accuracy for speed in subtle ways that matter in enterprise design pipelines. For many teams already using Nano Banana, the question is less image quality in isolation and more how reliably the model fits into approval flows, brand controls, and downstream editing tools.
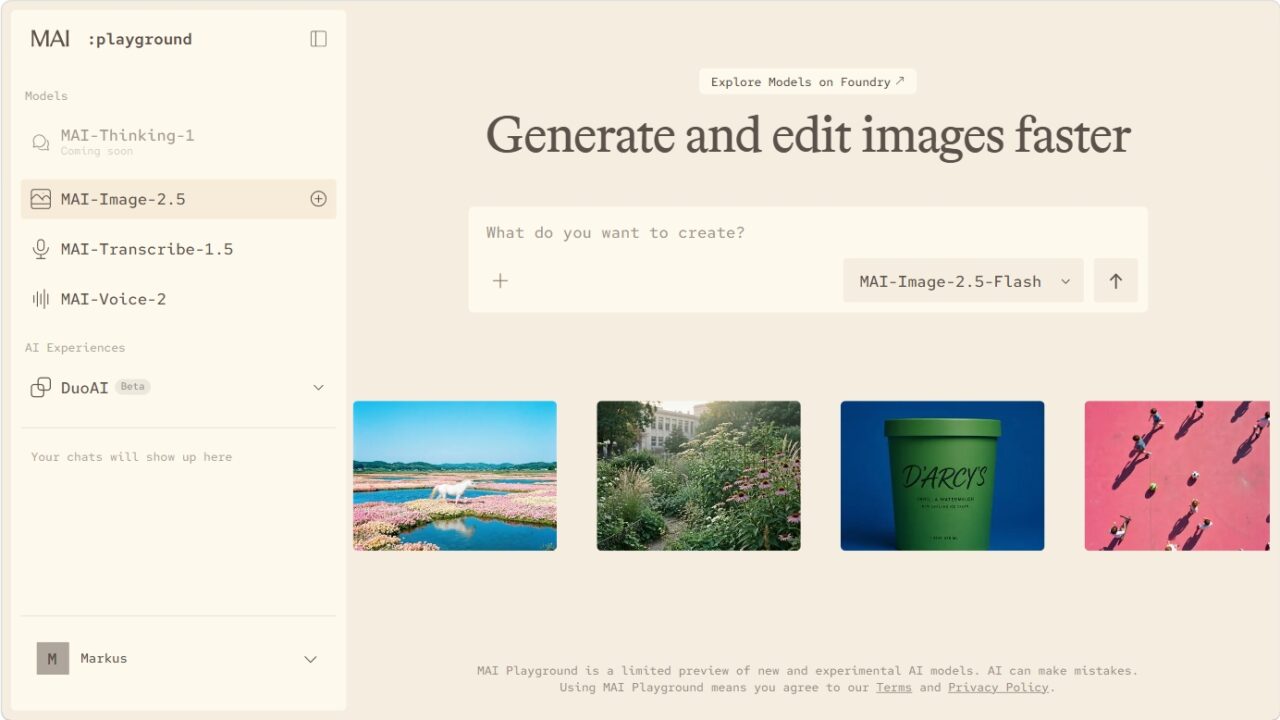
Voice, Transcription, and the Reality of Production Readiness
Alongside its headline models, Microsoft introduced MAI‑Transcribe‑1.5 for speech‑to‑text and MAI‑Voice‑2 (plus 2 Flash) for text‑to‑speech. These are available in limited preview via Microsoft’s Playground, with MAI‑Thinking‑1 still “coming soon” for most users. In my tests, the transcription model handled clear audio well but stumbled on overlapping voices and technical jargon, creating extra review steps that undercut its promise of time savings in meetings and content workflows. MAI‑Voice‑2 produced natural‑sounding speech but felt closer to a cosmetic upgrade than a step‑change in expressiveness or controllability. For enterprises, preview labels matter: integration hooks, SLAs, and observability for errors are as important as raw model quality. Today, the voice and transcription MAI models are suitable for experimentation, pilots, and non‑critical internal tools, but they still lack the battle‑tested feel you’d want before wiring them into customer‑facing production systems.
Clean Data Claims, Compliance Risks, and Cost Questions
Microsoft frames MAI models as trained on “enterprise‑grade, clean and commercially licensed data,” a core part of its trust story for MAI‑Thinking‑1 and the wider lineup. However, training details surfaced later list public‑web and Common Crawl data alongside licensed sources. WinBuzzer notes that this “turns a training‑corpus detail into a trust question” because Common Crawl includes copyrighted pages, and Microsoft has not yet clarified how “appropriately licensed” applies beyond crawler respect for robots.txt. For compliance and procurement teams, that ambiguity matters as much as AI image generation benchmark charts or enterprise AI reasoning scores. Cost efficiency is also heavily implied—MAI‑Code‑1 is called “ultra‑efficient” and Flash variants are pitched for “super‑efficient production workloads”—but Microsoft has not published pricing or hard utilization data. Until licensing language and operational metrics are clearer, MAI models Microsoft offers feel more like promising experiments than risk‑free replacements for existing enterprise AI stacks.





