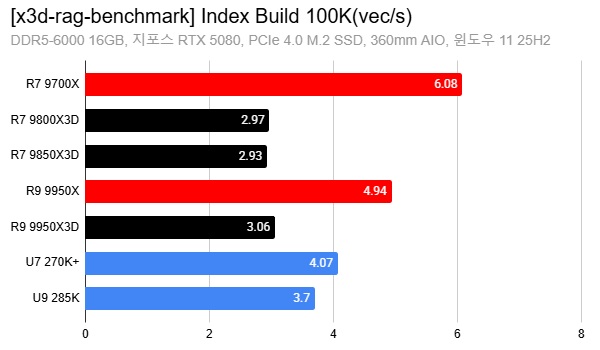
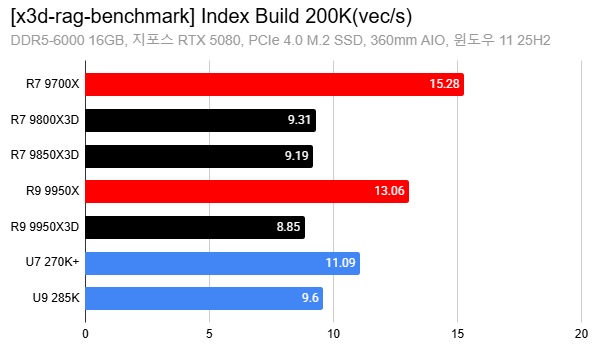
An 88% Surprise: Ryzen X3D’s Big Win in RAG AI Performance
Recent benchmarks suggest that AMD’s 3D V-Cache Ryzen chips can deliver up to an 88% performance boost over non‑X3D CPUs in AI workloads focused on retrieval‑augmented generation. In tests based on the open‑source X3D RAG Benchmark, reviewers evaluated multiple processors, including AMD’s Ryzen 9000X3D lineup, on tasks like graph‑based vector search and index building for local or small‑team RAG pipelines. These scenarios typically involve 100K–200K vectors and are meant to mirror personal‑PC or single‑node setups rather than massive distributed clusters. The results show X3D chips consistently finishing vector search and index‑build stages faster than their standard Ryzen counterparts, confirming that larger on‑chip cache can materially cut CPU‑side latency. Importantly, GPUs still handle the heavy lifting for LLM inference, but as agentic and search‑driven workflows grow, the CPU’s ability to feed the GPU quickly becomes a primary bottleneck—one that cache‑rich designs are unusually good at relieving.
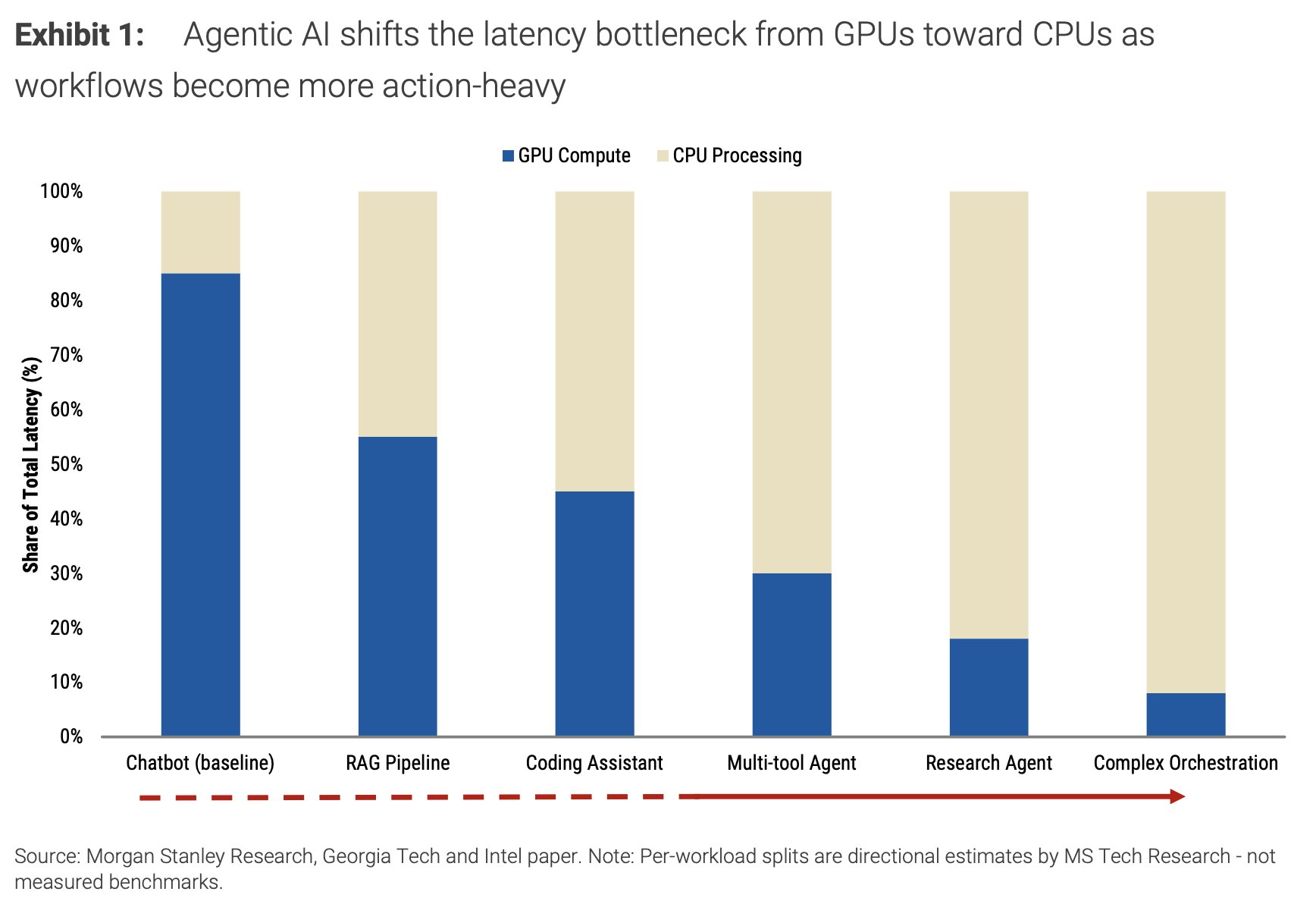
How Retrieval-Augmented Generation Works—and Why the CPU Suddenly Matters
Retrieval‑augmented generation (RAG) bolts a search engine onto a language model. When you ask a question, the system first converts your query into an embedding, then searches a vector database of documents for the closest matches, and finally feeds those results into the LLM to craft a grounded answer. That vector search—often powered by algorithms like HNSW (Hierarchical Navigable Small World)—runs largely on the CPU when the GPU is busy with inference. Because RAG pipelines involve lots of random memory accesses and frequent graph traversals, they are highly sensitive to memory bandwidth, latency, and cache size. Each cache miss forces the CPU to wait on slower main memory, multiplying response times as your document collection grows. As agentic AI and multi‑step workflows become more common, the share of total latency attributed to the CPU increases, turning cache‑efficient processors into a key lever for snappier, more reliable RAG AI performance.
What 3D V-Cache Actually Is—and Why It Helps Token Retrieval
AMD’s 3D V‑Cache technology stacks an extra slab of SRAM vertically on top of the CPU’s existing cache, dramatically increasing the total L3 capacity without widening the chip’s footprint. Compared with standard Ryzen designs, X3D variants offer far more on‑chip storage for hot data like vector graph structures, frequently accessed embeddings, and routing metadata. In practical terms, this means HNSW and similar search algorithms can keep more of their working set in cache, reducing trips to slower DRAM and accelerating both index builds and query‑time lookups. For RAG AI performance, that translates into faster token retrieval and lower end‑to‑end latency between “question in” and “answer out.” Since the X3D RAG Benchmark specifically targets personal and small‑team, single‑node setups, the gains are directly relevant to local AI chatbot setups, where a single machine must juggle LLM inference on the GPU and intensive vector search on the CPU without the safety net of a large distributed cluster.
What This Means for Home Tinkerers, Small Teams, and Gamer-Creators
For home experimenters running a local AI chatbot setup, a Ryzen X3D for AI can shorten response times and make multi‑document question‑answering feel less sluggish, especially when dealing with 100K–200K vector collections. Small businesses building internal knowledge assistants may see even bigger benefits: as query volume rises, CPU‑side bottlenecks dominate, and cache‑heavy chips help keep latencies predictable without immediately resorting to complex multi‑node infrastructure. Gamers who also want strong AI performance are a particularly interesting group. X3D chips already have a reputation for high frame‑rate gaming thanks to their enlarged caches; the same hardware characteristics now pay dividends for RAG workloads, offering a balanced option for hybrid gaming‑and‑AI rigs. However, these users must also consider thermals, platform compatibility, and whether their workloads are cache‑bound enough to justify a specialized CPU rather than a more general upgrade path.

Should You Buy a 3D V-Cache CPU—or Stick with GPUs and Cloud?
Choosing AMD 3D V‑Cache for RAG AI work makes the most sense when your bottleneck is CPU‑side vector search rather than GPU compute. If you’re running a modest local AI chatbot setup with a mid‑range GPU and a growing document collection, upgrading to an X3D chip can be more impactful than a marginally faster graphics card. For small teams hosting on‑prem assistants, cache‑heavy CPUs are an appealing way to reduce latency without relying entirely on cloud services. That said, not every workload justifies this path. If you mostly run large foundation models with minimal retrieval, a standard Ryzen or other modern CPU may suffice, and investing in a stronger GPU—or offloading inference to the cloud—could be more beneficial. Likewise, organizations with highly bursty or massive workloads may still prefer cloud RAG stacks, trading hardware control for elastic scaling and managed infrastructure.