What Claude Opus 4.8 Is—and Why It Matters Now
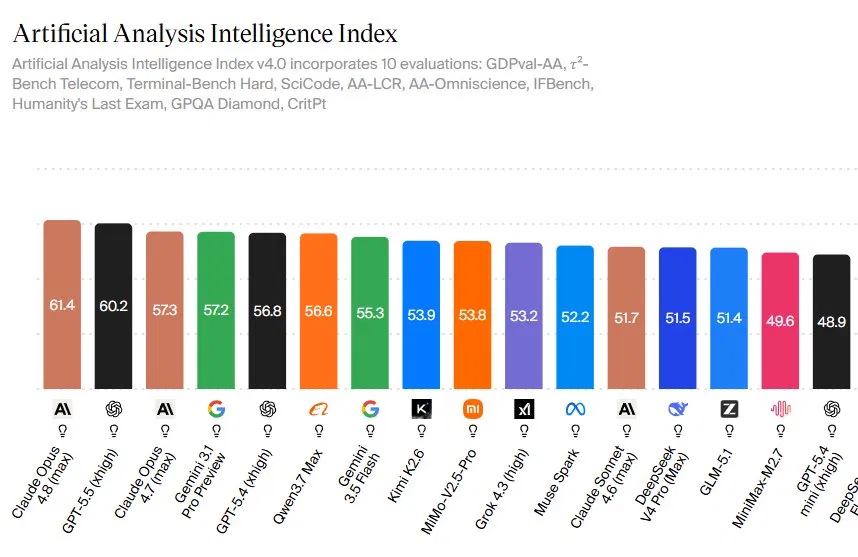
Claude Opus 4.8 is Anthropic’s latest flagship AI model that surpasses previous Claude versions and GPT 5.5 on independent capability and real‑world task benchmarks, while adding cost‑saving modes and new controls that make it more practical and predictable for enterprise AI performance at scale. On the Artificial Analysis Intelligence Index v4.0, Claude Opus 4.8 scores 61.4, edging past GPT 5.5’s 60.2 and its own predecessor’s 57.3. The index aggregates 10 evaluations that cover coding, reasoning, system use, and scientific and exam‑style tests, giving a broad picture of AI model benchmark standings instead of a single narrow score. This marks Claude Opus 4.8 as the current leader among frontier models, signaling a shift in the GPT 5.5 comparison conversation from “who is bigger” to “who converts model power into dependable business outcomes.”
Benchmark Wins: From Composite Index to GDPval-AA
On headline metrics, Claude Opus 4.8’s 61.4 score on the Artificial Analysis Intelligence Index reflects consistent gains across domains rather than a one‑off spike. Anthropic’s internal data also show strong task‑specific results: 69.2% on SWE‑Bench Pro for agentic coding, leading Humanity’s Last Exam with tools at 57.9%, and 83.4% on OSWorld‑Verified for agentic computer use. The more important shift for enterprise AI performance is on the GDPval‑AA benchmark, which measures agentic performance on real‑world work tasks across 44 occupations and 9 industries using web and shell access. Claude Opus 4.8 reaches an Elo of 1890, 121 points ahead of GPT 5.5 and 137 points above Opus 4.7 at max effort. According to Artificial Analysis, this translates to an implied win rate of about 67% in head‑to‑head matches against GPT 5.5 xhigh, making it a clear leader in economic task value.
Enterprise Trade-offs: Quality, Turns, and Cost Dynamics
For businesses comparing Claude Opus 4.8 to GPT 5.5, the story is not only who wins the AI model benchmark, but at what operational cost. Opus 4.8 is more efficient than Opus 4.7, using 15% fewer turns and 35% fewer output tokens on GDPval‑AA, yet it still needs about 30% more turns than GPT 5.5 to complete the same tasks. That means higher quality and higher Elo scores, but potentially more API calls per workflow. Anthropic offsets this with pricing structure and modes rather than raw turn efficiency. Opus 4.8 launches at the same price as Opus 4.7, and Anthropic adds a Fast Mode that runs the same model about 2.5 times faster at one‑third the standard cost. For large agentic workloads, this mix gives enterprises a way to route complex tasks to full‑effort Opus while using Fast Mode for cheaper, high‑throughput routines.
Honesty, Safety, and the GPT 5.5 Comparison
Claude Opus 4.8 is not only about higher scores; Anthropic says it “reaches new highs on our measures of prosocial traits.” The model is designed to better support user autonomy, refuse misuse, and reduce deceptive behavior. Internal evaluations show it is more likely to flag uncertainty instead of producing confident but unverified claims. Anthropic also reports that Opus 4.8 is four times less likely to omit flaws in code it writes, which matters in long‑running enterprise AI deployments where hidden errors can be expensive to track and fix. In the GPT 5.5 comparison, this positions Claude as the model that trades some turn efficiency for higher transparency and self‑critique. For regulated industries or safety‑sensitive workflows, that shift from raw output speed to honest, inspectable reasoning can be as important as the latest benchmark win.
New Features: Effort Controls and Dynamic Workflows
Beyond raw capability, Claude Opus 4.8 arrives with product features aimed at giving teams more direct control over cost, latency, and depth of reasoning. Users can now set Effort levels—Low, Medium, High, and Max—to tune how long the model thinks and how detailed its answers are. Lower effort returns faster, lighter replies, while higher effort burns more tokens and time but pushes performance toward the model’s benchmark ceiling. Anthropic recommends Max for only the hardest tasks, which fits well with mixed‑mode enterprise pipelines. A new Dynamic workflows feature, now in research preview, goes further by letting multiple Claude instances coordinate on complex jobs, mirroring Anthropic’s demonstrations of parallel agents building software systems. Combined with Fast Mode’s lower pricing, these controls turn Claude Opus 4.8 from a single powerful model into a flexible platform for orchestrated, budget‑aware automation.





