What RTX Spark Is and Why Local AI Agents Matter
NVIDIA RTX Spark is a new class of Windows PC built around a superchip that runs local AI agents directly on your machine, combining up to 1 petaflop of AI compute, 128GB of unified memory, and NVIDIA’s full graphics and AI software stack to deliver private, responsive, on-device intelligence without depending on cloud connectivity. Positioned for creators, AI developers and gamers, RTX Spark systems are designed for slim laptops with all-day battery life and compact desktops, turning the traditional PC into what NVIDIA calls a “personal AI computer.” These Windows PC AI systems aim to move from launching individual apps to interacting with local AI agents that can understand tasks, coordinate multiple tools, and run generative models on-device. For anyone worried about latency, connectivity issues, or sensitive data leaving their machine, RTX Spark’s local AI agents promise a faster, more controlled alternative to cloud-only assistants.
OpenShell and Windows Security: Enterprise-Style Control on Consumer PCs
The most important shift RTX Spark brings is not only raw performance, but a Windows platform designed for secure local AI agents. Microsoft is adding new security primitives around identity, containment, policy and end-to-end security so agents can run natively under clear guardrails. On top of this, NVIDIA’s OpenShell runtime gives users direct policy control: you can decide what each agent may access, which apps it can automate, and when it must fall back to a cloud model. OpenShell can route queries to local models first based on your privacy rules, and disguise personal details whenever an external service is required. According to NVIDIA, this same security and privacy layer is already being adopted by Hermes Agent and OpenClaw, which plan to let AI agents execute tasks in Windows apps, coordinate cross-app workflows, generate media and search local files semantically, all while staying under explicit user control.
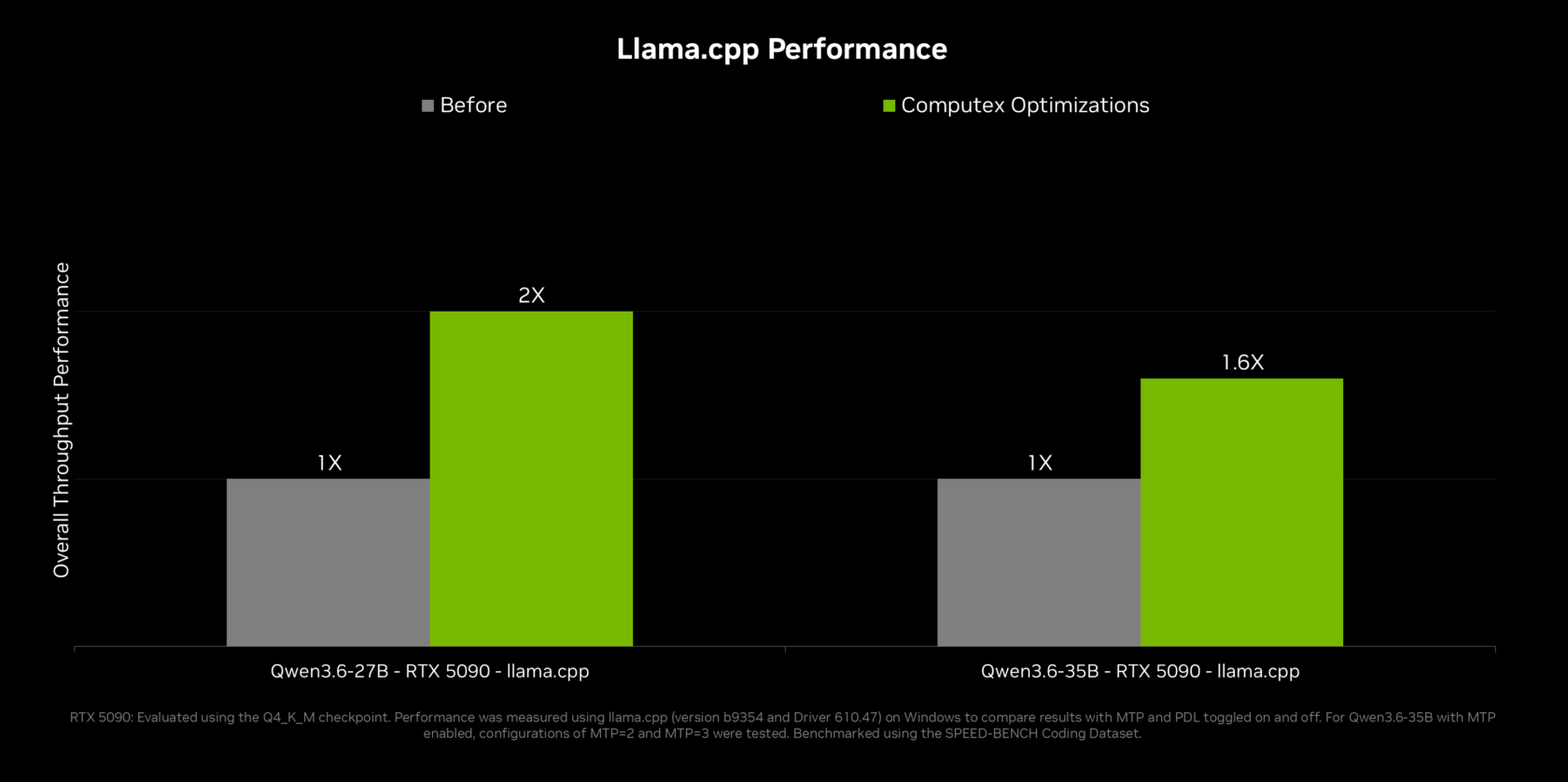
llama.cpp Performance Gains: 2x Faster Local Inference for Agents
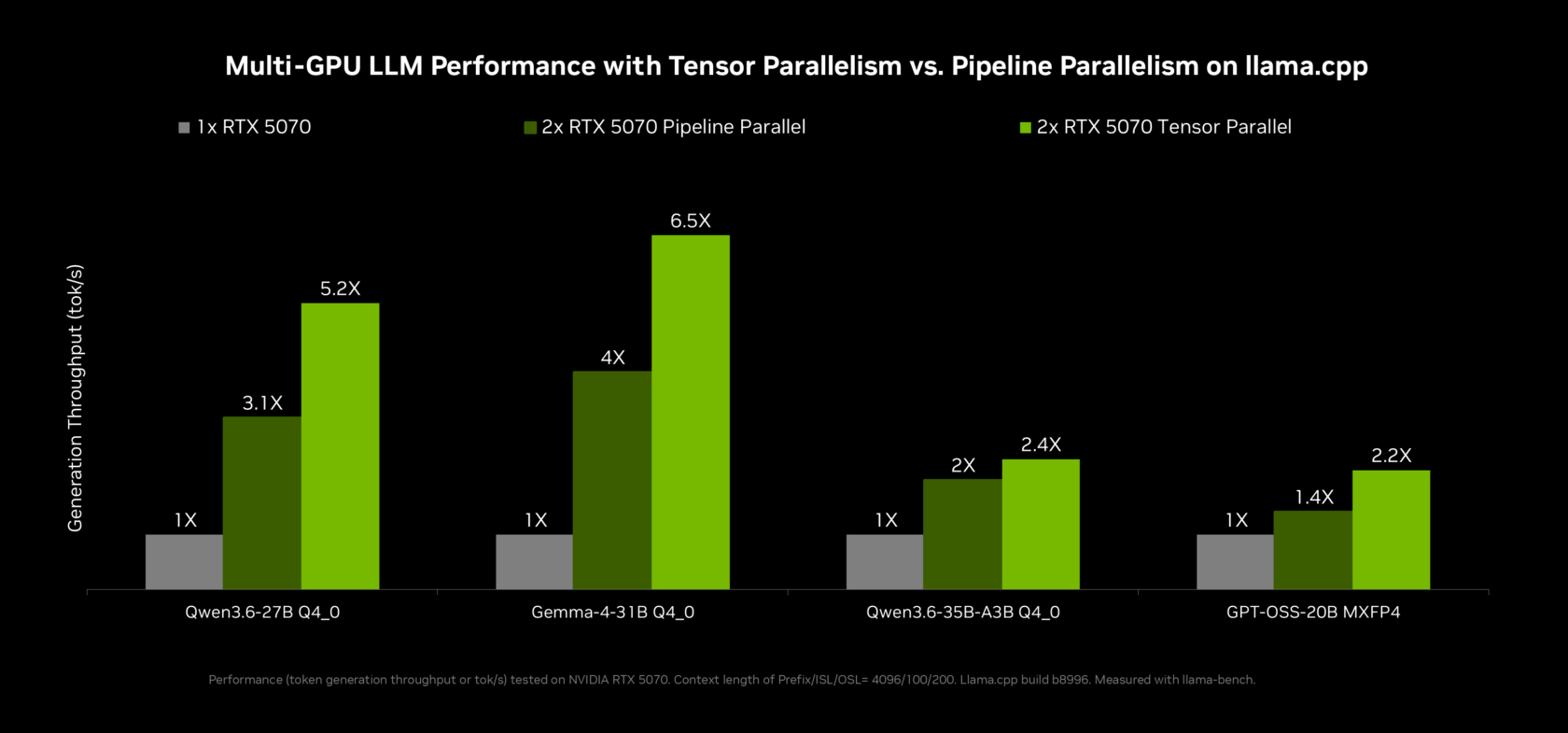
For local AI agents to feel competitive with cloud tools, inference speed is critical—and this is where NVIDIA’s work with llama.cpp matters. By collaborating with the open source community on features like multi-token prediction, where a smaller draft model proposes several tokens that the main model verifies in one pass, RTX hardware delivers up to 2x throughput on Qwen 3.6 and 3.5 27B and around 1.6x on the 35B variants when running on a GeForce RTX 5090. These optimizations, accessible through the llama.cpp web UI and LM Studio, directly improve Windows PC AI workflows built on local AI agents. Multi-GPU users gain further boosts from new tensor parallelism support, which can provide up to 2x memory and 1.8x compute on two equivalent GPUs. Together, these updates make llama.cpp performance viable for demanding, agentic use cases such as multi-step reasoning, code assistance, and continuous desktop automation.
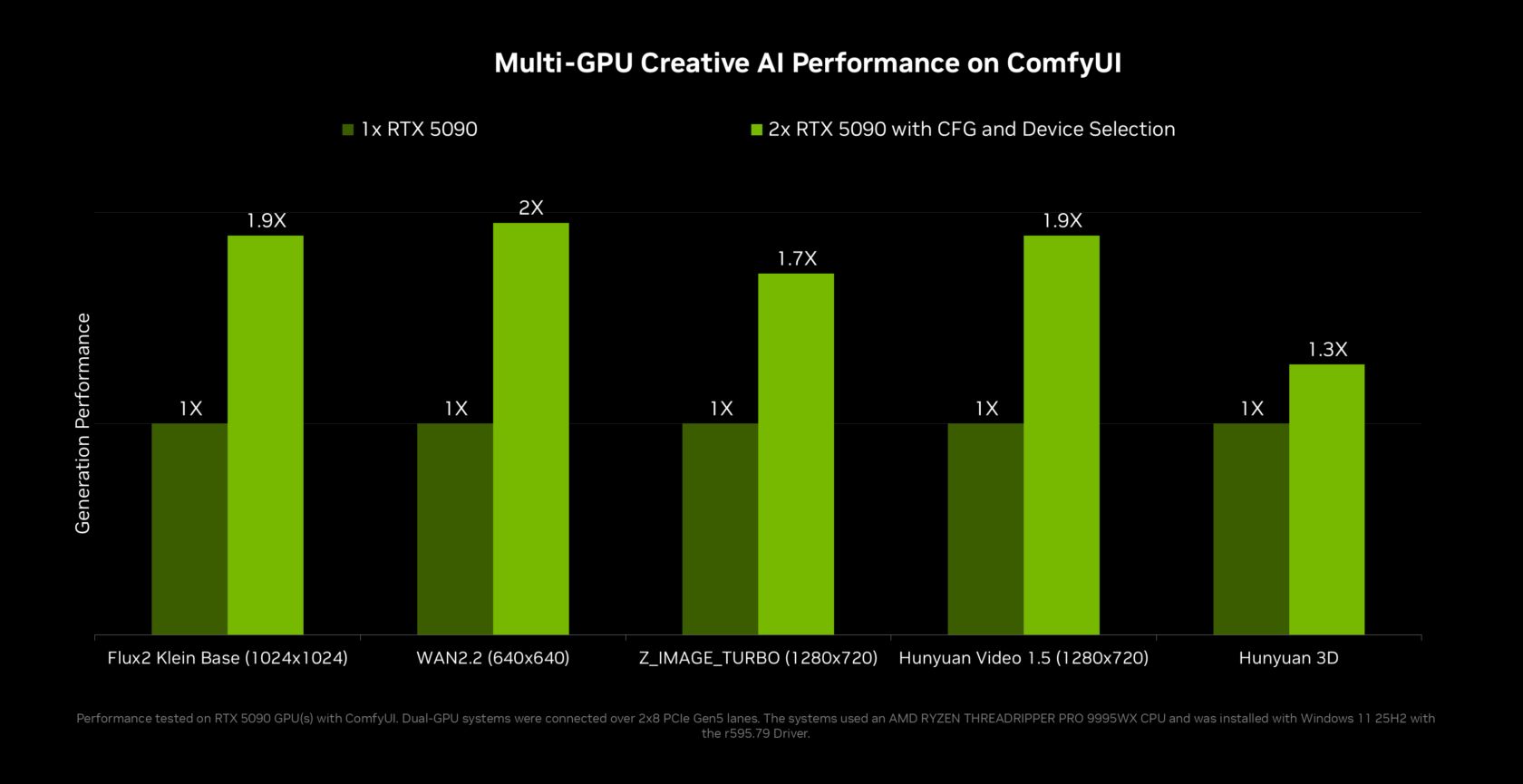
Adobe, ComfyUI and Creative Apps: What Changes for Content Makers
RTX Spark is launching alongside a quiet but important rework of creative tools to run better with local AI agents. Adobe is rearchitecting Photoshop and Premiere around this new stack, signaling that on-device generative features and AI-assisted editing will increasingly tap RTX Spark’s unified memory and Tensor Cores to improve responsiveness and reduce the memory footprint. Blender is adding DLSS 4.5 Ray Reconstruction, and NVIDIA is bringing RTX Video Frame Generation to ComfyUI, which also gains faster diffusion workflows thanks to multi-GPU support and new classifier-free guidance methods. For content creators, that means more of the AI pipeline—frame interpolation, style transfers, intelligent masking, or asset generation—can run on a local RTX Windows PC without offloading to the cloud. As agents mature, expect “AI assistants” that can understand project context, manage file assets and automate repetitive edits right on your desktop.
Why Privacy-Conscious Users Should Care About RTX Spark
Local AI agents on RTX Spark directly answer growing concerns about data privacy and cloud dependence. Instead of sending documents, code, or personal media to remote servers, most inference and agent reasoning can now occur on your local RTX Windows PC. The OpenShell framework, combined with new Windows security primitives, lets you decide when data may leave the device, which models stay local, and what information must be masked before any cloud call. This aligns local AI agents with expectations more familiar from enterprise security, but in a consumer form factor. At the same time, optimizations in llama.cpp and vLLM, plus the 1 petaflop-class compute available on RTX Spark systems, keep inference speeds competitive with hosted APIs for many workflows. For privacy-conscious users and professional creators, the trade-off between control and convenience is no longer one-sided: RTX Spark makes local by-default a practical option.





