What “Cheapest AI Models” Means in Practice
Cheapest AI models are language or reasoning models priced to minimise cost per token while still delivering acceptable quality for tasks like summarisation, coding, and document generation across real workflows. This pricing focus has reshaped how teams think about AI usage: instead of only chasing frontier performance, many now balance cost per token against speed, context length, and reliability. Token consumption leaderboards from platforms like OpenRouter show that low-cost, high-throughput models dominate real-world usage, especially where long context windows and bulk generation matter more than perfect accuracy. At the same time, developers must accept tradeoffs: budget models can hallucinate more often, respond slower, or offer smaller context windows than premium options. Understanding how AI model pricing comparison tables translate into day-to-day performance is now essential for anyone running substantial workloads, from solo developers to large enterprises.
AI Model Pricing Comparison: How Blended Costs Work
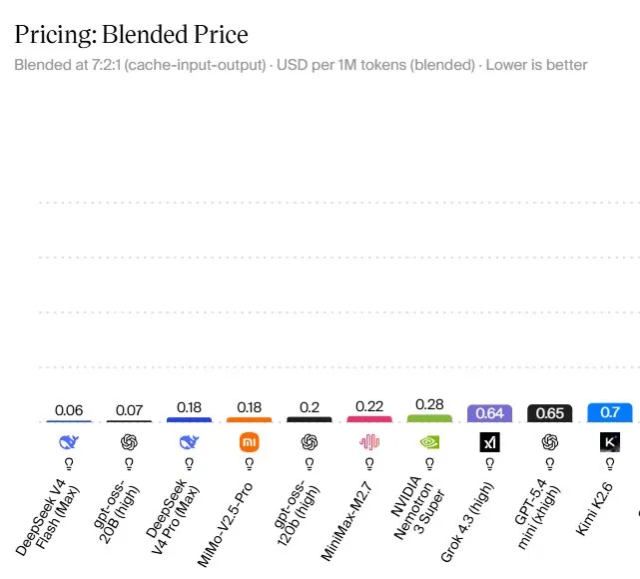
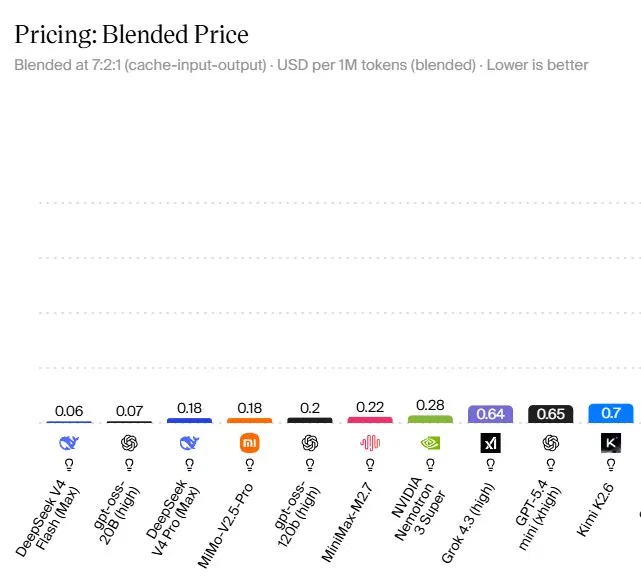
Most current AI model pricing comparison charts rank models by blended price, which accounts for cache hits and both input and output tokens rather than only headline rates. One common method uses a 7:2:1 ratio for cache-hit, input, and output tokens, highlighting how long prompts and repeated calls can reduce effective cost per token. DeepSeek V4 Flash (Max) leads this ranking at a blended rate of USD 0.06 (approx. RM0.28) per million tokens, while GPT-OSS-20B (High) follows at USD 0.07 (approx. RM0.32). A second tier, including DeepSeek V4 Pro (Max) and MiMo-V2.5-Pro, sits at USD 0.18 (approx. RM0.83) per million tokens. These figures show that small changes in per-token pricing compound quickly at scale, making blended cost a more realistic guide than list prices for output-heavy workloads.
Which Budget AI Alternatives Dominate Real Workloads?
Usage data shows that some of the cheapest AI models also rank among the most widely used. OpenRouter’s leaderboard reports DeepSeek V4 Flash consuming 10.9 trillion tokens, with token usage growth of 995%, signalling heavy adoption in production pipelines. Hy3 Preview closely follows with 10.7 trillion tokens and growth above 999%, helped by its low input token price of USD 0.063 (approx. RM0.29) per million and strong performance on complex web research benchmarks. These models benefit from mixture-of-experts designs that activate only a fraction of total parameters, keeping inference economical. However, there are caveats: DeepSeek V4 Flash is reported to hallucinate 96% of the time when it lacks an answer, which makes it better suited to speed-sensitive, low-risk tasks than high-stakes decision-making. In short, popularity aligns with cost advantage, but not always with reliability.
Do Cheaper Models Work for Common Tasks?
Budget AI alternatives are most effective when tasks emphasise throughput over perfection. DeepSeek V4 Flash, with its 1 million token context window and USD 0.06 (approx. RM0.28) per million blended cost, suits document generation, bulk summarisation, and high-volume chat where occasional errors are acceptable. GPT-OSS-20B, at USD 0.07 (approx. RM0.32) per million, handles lightweight classification, routing, or short-form summarisation where its smaller parameter count is an advantage for speed and cost. For more demanding workflows, such as multi-step agents or non-trivial coding, mid-priced models like DeepSeek V4 Pro and GPT-OSS-120B at USD 0.18–0.20 (approx. RM0.83–0.92) per million tokens provide better reasoning depth without frontier-level costs. In many pipelines, a hybrid routing approach works best: cheap models cover routine steps, while stronger models handle planning, critical reasoning, or final verification.
Different Tradeoffs for Enterprises and Individual Developers
Enterprises and individual developers face different cost-benefit tradeoffs when picking the cheapest AI models. Large teams often route simpler tasks to mid-tier models like Claude Sonnet, keeping frontier options such as Claude Opus for complex reasoning and high-stakes coding, since reliability and consistency matter as much as cost per token. Smaller developers or startups are more likely to prioritise minimum blended price, gravitating toward DeepSeek V4 Flash or GPT-OSS-20B to stretch budgets and handle high-traffic workloads. For them, occasional hallucinations can be mitigated with extra validation or human review. Enterprises, by contrast, may accept higher prices for models with better abstention behaviour or stronger benchmarks, especially in regulated domains. Ultimately, cost per token is only one dimension; context size, error patterns, and integration strategy all shape whether a budget model is a safe substitute for premium options.