
What Claude Opus 4.8’s ‘Honesty Engine’ Really Means
Claude Opus 4.8 is Anthropic’s new flagship large language model that combines higher task performance with an “honesty engine” designed to admit uncertainty, reduce hallucination, and avoid false confidence across coding, research, and professional workflows. Instead of focusing only on raw benchmark scores, Anthropic has tuned Opus 4.8 to be less deceptive, more cautious about unsupported claims, and more explicit when it does not know an answer. The model introduces refined effort controls, cheaper fast mode, and expanded dynamic workflows for large coding projects, but its standout AI honesty feature is the way it flags flaws in its own outputs. According to Anthropic, Opus 4.8 is “around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked,” signaling a shift toward trustworthy AI models that prioritize user safety and autonomy.
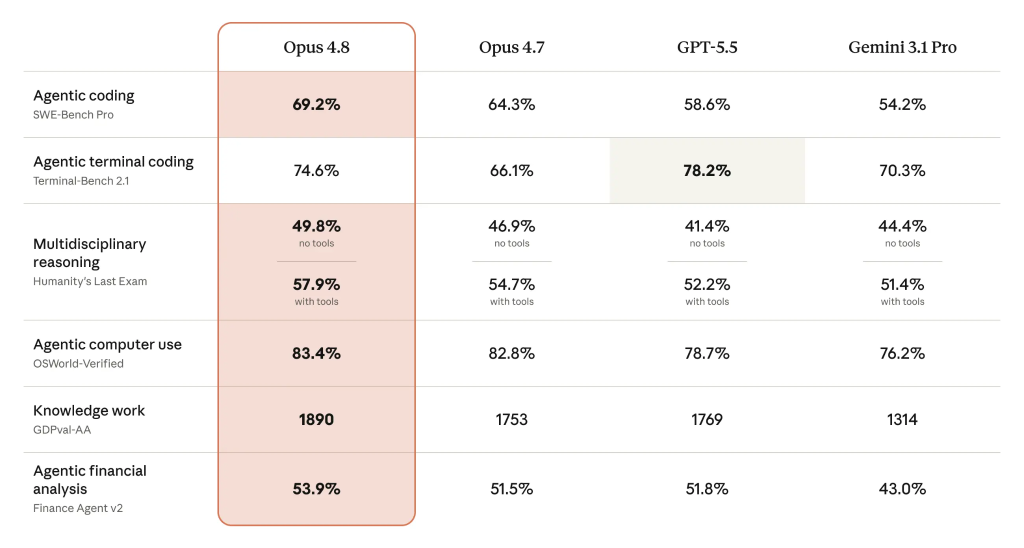
Beating GPT-5.5 and Gemini While Hallucinating Less
Benchmarks suggest Claude Opus 4.8 is not trading honesty for strength; it is raising both. Anthropic reports that Opus 4.8 surpasses Opus 4.7, GPT-5.5, and Gemini 3.1 Pro on most evaluated tasks, including agentic coding and agentic compute use, with only agentic terminal coding still favoring GPT-5.5. This matters because earlier generations of large models often scored well while quietly producing confident but incorrect answers. Opus 4.8 is designed to reduce hallucination and unsupported claims, while still handling complex, multi-step coding and reasoning tasks. In internal evaluations, the model is less likely to cooperate with misuse and displays lower rates of deception than prior Opus versions, moving closer to Anthropic’s earlier Mythos alignment work. For organizations that care about trustworthy AI models, this combination of reduced hallucination and competitive performance changes how benchmarks are interpreted.
Why Honesty Matters in Coding, Research, and Professional Work
The AI honesty feature is most important where silent errors carry real costs: software engineering, research, legal and financial analysis, and expert consulting. In Opus 4.8, Anthropic’s own tests show it is about four times less likely to overlook defects in code it has written, and early users echo that shift. Shopify staff engineer Tom Pritchard says, “Claude Opus 4.8 has noticeably better judgment… it asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound.” For coding teams, that means fewer subtle bugs slipping through AI-assisted refactors or migrations. For researchers and professionals, an assistant that clearly signals uncertainty is easier to audit and integrate into existing review processes. Instead of acting like an overconfident junior, Opus 4.8 is closer to a colleague that explains where its knowledge ends.
Dynamic Workflows, Effort Controls, and Autonomy by Design
Alongside reduced hallucination, Claude Opus 4.8 adds tools that make its honesty usable at scale. Dynamic workflows, now in research preview, allow Claude Code to plan work and spin up hundreds of parallel subagents in a single session, verify their outputs, and return a consolidated result. Anthropic cites examples like codebase-wide migrations across hundreds of thousands of lines of code, where self-checking behavior and explicit uncertainty are vital. Effort controls, previously seen in Claude Code and now extended to Claude.ai and Cowork, let users dial up deeper thinking or favor faster, lighter responses depending on the task. The alignment team reports that Opus 4.8 scores higher on prosocial traits, such as supporting user autonomy and working in the user’s best interests, while showing substantially lower cooperation with misuse. In practice, that means more helpfully cautious behavior when stakes are high.

From Capability Race to Trust Race in AI Development
Claude Opus 4.8 signals a turning point in how top models are judged. For years, the focus has been on who tops the leaderboards; now, honesty, reduced hallucination, and user-aligned behavior are becoming competitive advantages. Opus 4.8 still competes head-on with GPT-5.5 and Gemini 3.1 Pro on coding and reasoning benchmarks, but Anthropic’s framing of honesty as the “killer feature” reframes what progress looks like. Transparent uncertainty and lower deception are not nice-to-have traits; they are prerequisites for deploying AI into high-stakes production systems, from CI pipelines to knowledge workflows. As teams compare trustworthy AI models, questions will shift from “How high is the score?” to “Will this model tell me when it might be wrong?” If that mindset spreads, Opus 4.8 may be remembered less for a single benchmark win and more for helping start an industry-wide trust race.





