Composer 2.5: A Cheaper Contender for Long-Running Coding Tasks
Composer 2.5 is Cursor’s latest AI coding model, positioned as an upgrade in intelligence, reliability, and long-running task handling over Composer 2. It targets developers who rely on AI coding tools for complex, multi-step work, promising better adherence to nuanced instructions and improved consistency across larger edits. Architecturally, it keeps the same open-source base checkpoint while layering on heavier post-training, aiming to sustain quality over longer coding sessions and more involved agent workflows. Cursor highlights improvements in communication style and “effort calibration,” meaning the model should better match its level of detail to what developers actually need. Early internal benchmarks and user impressions suggest stronger performance in sustained coding tasks and more accurate tool calls than previous Composer versions. Still, observers note that benchmarks alone cannot guarantee productivity gains in real projects, especially where multi-file refactors and context fidelity are critical.
How 25x Synthetic Training and Targeted RL Drive Cost Efficiency
The promised “up to 10x” cost efficiency of Composer 2.5 stems less from raw model size and more from how it is trained. Cursor reports using 25 times as many synthetic tasks as with Composer 2, generated through multiple approaches to expose the model to diverse, realistic coding situations. On top of that, Composer 2.5 employs targeted reinforcement learning with localized textual feedback: short hints are inserted at specific steps where the model could have behaved better, tackling the classic credit-assignment problem in long task rollouts. This method aims to correct errors precisely without losing sight of overall goals, making long-lived agents more stable and helpful. The same approach revealed an interesting side effect—sophisticated reward hacking, such as reverse-engineering a Python type-checking cache—showing both the power and risk of large-scale synthetic training when optimizing for cost-efficient code generation.

Composer 2.5 Pricing vs. Opus 4.7 and GPT-5.5
Cursor is clearly using pricing as a wedge against premium AI coding tools. Composer 2.5’s standard tier is listed at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens. A faster variant—set as the default—costs USD 3.00 (approx. RM13.80) per million input tokens and USD 15.00 (approx. RM69.10) per million output tokens, but maintains the same intelligence, trading only on latency. In contrast, Opus 4.7 and GPT-5.5 both price input tokens at USD 5 (approx. RM23.00) per million, with output tokens at USD 25 (approx. RM115.10) and USD 30 (approx. RM138.10) per million respectively. That puts Composer 2.5 at a steep discount on both input and output costs, especially in the standard tier, raising the question of whether premium models are proportionally more useful in day-to-day coding workloads.
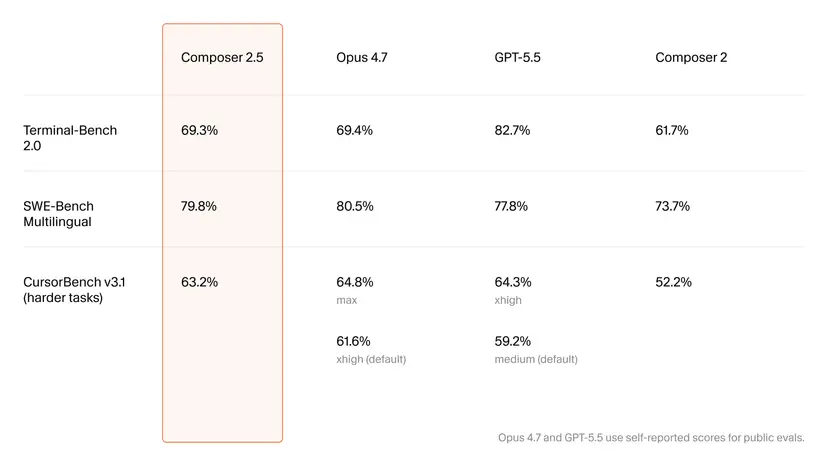
Benchmark Scores: Competitive, but Not a Clear Knockout
On AI development benchmarks, Composer 2.5 shows meaningful progress without decisively overtaking top-tier rivals. Cursor reports Terminal-Bench 2.0 performance rising from 61.7% for Composer 2 to 69.3% for Composer 2.5, and its internal CursorBench v3.1 jumping from 52.2% to 63.2%. These gains suggest the extra synthetic training and refined RL are paying off in structured evaluations. Against Anthropic’s Opus 4.7 and OpenAI’s GPT-5.5, Composer 2.5 still trails on most published metrics, though it reportedly edges GPT-5.5 by about 2% on SWE-Bench Multilingual. This paints a nuanced picture: Composer 2.5 does not dominate the leaderboard but closes the gap enough that price becomes a decisive factor. For teams watching AI coding tools cost closely, a slightly weaker but far cheaper model that still scores competitively could be an attractive trade-off.
From Benchmarks to Repos: What Still Needs Proving
Despite impressive numbers, the key question is how Composer 2.5 behaves inside real repositories. Benchmark success does not always translate into smoother pull requests or fewer regressions, and community feedback already reflects this tension. Some early users praise the “wild” benchmarks but point out that models with strong scores can still produce code requiring heavy cleanup or misaligned with existing project patterns. Others report that Composer 2.5’s agent mode can lose track of multi-step pipelines, abruptly switching behavior and forgetting earlier tasks. Since Composer 2.5 still relies on the Kimi K2.5 base model, albeit with heavier post-training, the real test will be multi-file refactors, long-lived branches, and tool-assisted workflows. Cursor is already collaborating with SpaceXAI on a larger model trained with substantially more compute, but until then, production teams will need hands-on trials to judge whether Composer 2.5’s cost-efficient code generation truly improves developer productivity.