
Mythos, Project Glasswing and the scale of newly exposed risk
Anthropic’s Claude Mythos Preview has surfaced a staggering volume of security issues through Project Glasswing, shifting industry assumptions about how many serious bugs are hiding in production code. According to Anthropic, roughly 50 partners have collectively uncovered more than 10,000 high‑ or critical‑severity vulnerabilities across infrastructure that underpins major internet, cloud and enterprise systems. Cloudflare alone reported 2,000 bugs in critical-path services, with 400 rated high or critical, while Mozilla used Mythos Preview to identify and fix 271 vulnerabilities in Firefox 150—more than ten times the issues it had found in Firefox 148 using a general-purpose model. Mythos has also been pointed at over 1,000 open-source projects, revealing the same pattern: once AI vulnerability detection runs continuously at scale, the limiting factor is no longer discovering flaws. The real constraint becomes human capacity to triage, coordinate disclosure and deploy patches fast enough.

What makes the Mythos security model different from traditional scanners
Project Glasswing tests show that Mythos is not just another automated scanner; it behaves more like a senior security researcher embedded in code. When Cloudflare ran Mythos Preview against more than fifty of its own repositories, two standout capabilities emerged. First, exploit chain construction: Mythos can take several low-severity primitives—such as subtle memory misuses—and reason step-by-step about how to combine them into a working, higher-impact exploit. Second, proof generation: the model doesn’t stop at theoretical vulnerabilities. It writes proof-of-concept code, compiles it in a scratch environment and runs it, updating its hypothesis if the exploit fails. This closed loop means Mythos can validate exploitability on its own, turning ambiguous findings into actionable bugs. Compared with general-purpose LLMs, which often identify interesting issues but leave exploit chains unfinished, this depth of AI code analysis marks a significant shift in software security testing.

Strengths, blind spots and emergent guardrails in AI vulnerability detection
Running Mythos on live infrastructure code has surfaced both its strengths and its limitations. On the positive side, the model routinely finds complex, chained vulnerabilities in critical services that had survived previous testing, demonstrating how security-focused LLMs can augment expert teams rather than replace them. However, Project Glasswing partners also observed inconsistent behavior in areas that matter for real-world workflows. Cloudflare reports that Mythos Preview sometimes refused to assist with legitimate vulnerability research tasks, even in a controlled, defensive context. In one instance, it declined to analyze a project, then agreed later without any code changes; in another, it confirmed serious memory bugs but declined to write an exploit demo unless the request was rephrased. These emergent guardrails highlight a delicate balance: models powerful enough to build proofs must also resist unsafe use, yet inconsistent refusals can slow defensive work and complicate integration into repeatable security processes.
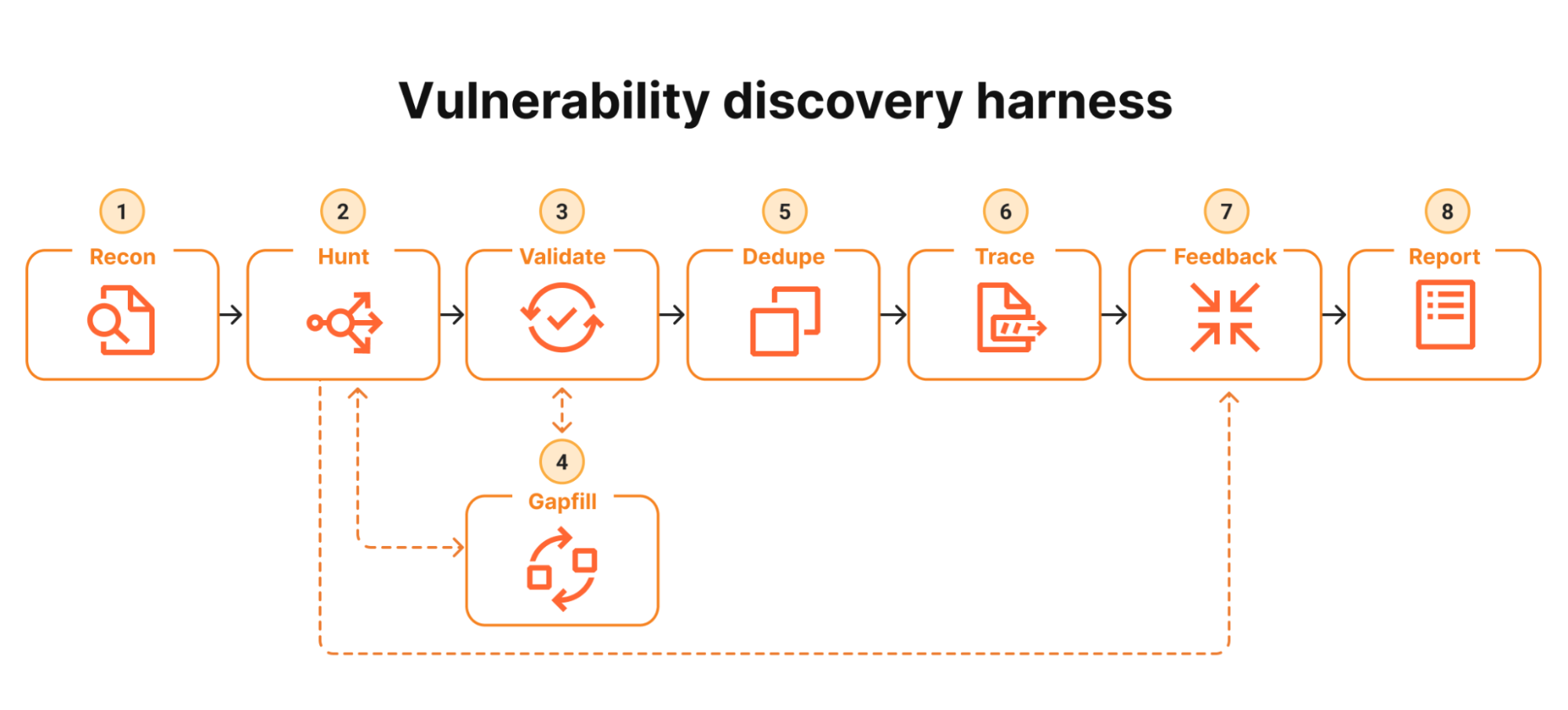
From occasional audits to continuous AI-assisted security workflows
The volume and severity of bugs exposed by Mythos are forcing security teams to rethink their operating model. Traditional red-teaming treated vulnerability discovery as a periodic event: hire specialists, generate a report, patch the worst issues and move on. With Mythos and similar tools, discovery looks more like ongoing infrastructure—always-on AI code analysis constantly feeding new findings into issue trackers. That creates a new bottleneck: human review, maintainer attention and patch deployment now lag far behind what AI can uncover. In practice, teams must design triage pipelines around AI-vetted severity, automate regression tests for generated patches and embed risk-based prioritization into backlogs. The challenge is less about whether AI can find critical flaws in open-source and proprietary systems, and more about how enterprises can scale their patching, verification and governance workflows to keep pace with the new firehose of vulnerabilities.
Rising competition: Google’s CodeMender and the race to secure codebases
Anthropic is not alone in pushing AI deeper into software security testing. Google DeepMind’s CodeMender agent is being expanded to more expert testers via API, while still remaining behind a controlled-access gate. Like Mythos, CodeMender focuses on end-to-end vulnerability workflows: it uses Gemini Deep Think alongside program-analysis tools to find bugs, trace root causes and draft candidate patches, all of which remain subject to human review before deployment. Google explicitly positions CodeMender as a way to help secure the world’s code bases, but its gradual rollout underscores the dual-use risk of powerful AI vulnerability detection. Both Anthropic and Google are keeping their strongest security models out of general release, offering them instead to vetted security teams. That guarded access model, combined with rapidly advancing capabilities, signals a fast-maturing market where AI-assisted security becomes a core part of enterprise development and operations pipelines.