A Flash-Tier Model That Plays in Frontier Territory
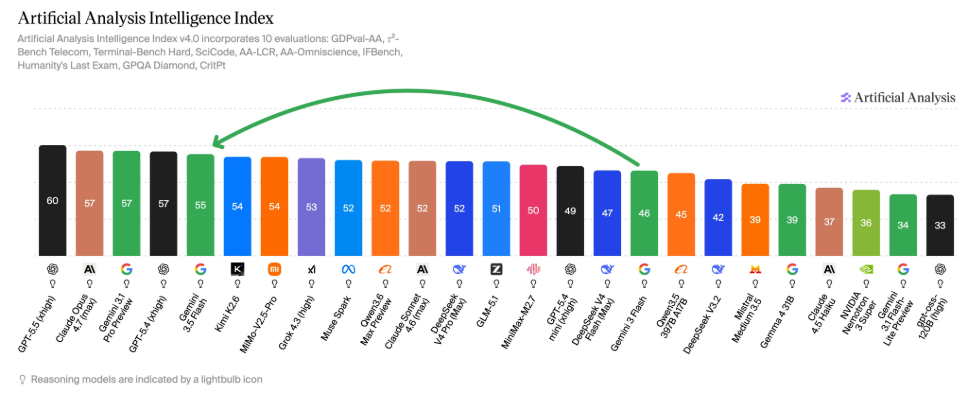
Gemini 3.5 Flash marks a strategic reset for Google’s model lineup. Traditionally, Flash variants have been the lighter, cheaper counterparts to Pro models, but this release lands squarely in frontier AI territory. On the independent Artificial Analysis Intelligence Index, Gemini 3.5 Flash scores 55, placing it within two points of Anthropic’s Claude Opus 4.7 and five points behind GPT-5.5 while ranking fifth overall. That composite score is notable because Flash is priced at roughly one third of GPT-5.5’s per-token cost, signaling a new phase of AI capability compression: more intelligence, for less. For developers weighing AI model performance comparison data, this means a Flash-tier option now offers frontier-level reasoning without frontier-level pricing. It also raises expectations for the forthcoming Gemini 3.5 Pro, which could push even higher on the index while still undercutting rival flagship models on cost.

Benchmark Performance: Coding, Agents, and Multimodal Strengths
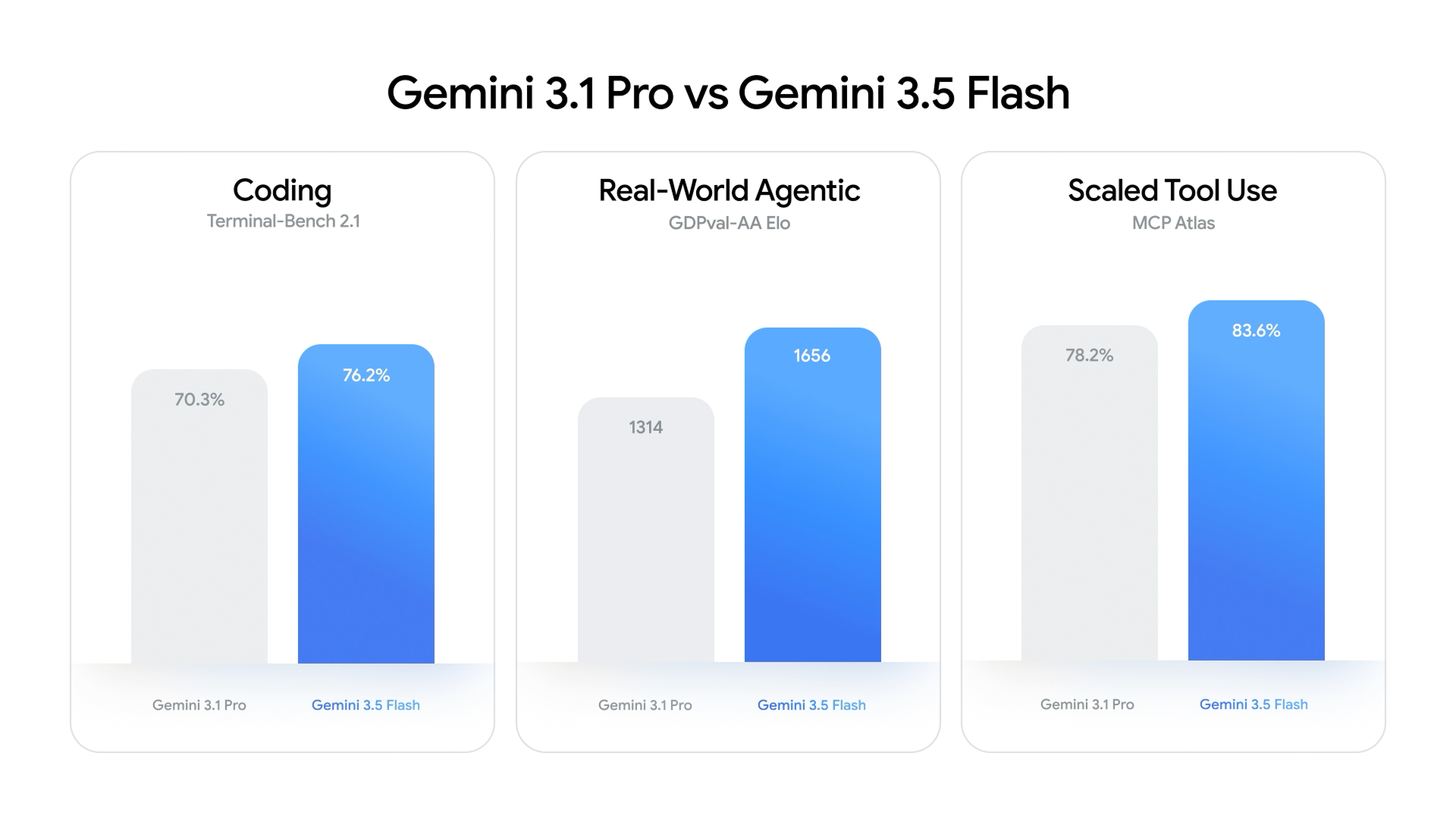
On task-specific benchmarks, Gemini 3.5 Flash is less a budget model and more an all-round workhorse. It posts 76.2% on Terminal-Bench 2.1, a strong coding benchmark result that edges out Gemini 3.1 Pro. On GDPval-AA, which measures real-world economically valuable agentic AI tasks, the model reaches an Elo of 1,656, far ahead of Gemini 3 Flash and Gemini 3.1 Pro and just behind GPT-5.4 (xhigh). It also scores 83.6% on MCP Atlas for scaled tool use, confirming that it can orchestrate complex tool chains rather than simply answer questions. Multimodally, Gemini 3.5 Flash achieves 84% on MMMU-Pro and supports image, video, speech, and text inputs, extending Google’s lead over several frontier AI models that remain image-only. For teams building agents and multimodal workflows, these Gemini 3.5 Flash benchmarks position it as a credible default choice.
Speed and Cost: Redefining the Economics of Agents
If performance brings Gemini 3.5 Flash into frontier company, speed and pricing shift the competitive landscape. The model delivers around 289 output tokens per second, with Google framing this as roughly four times faster than comparable frontier models. On Artificial Analysis’s speed–intelligence scatter plot, Gemini 3.5 Flash sits in the coveted upper-right quadrant alongside other high-performance Gemini variants, but no rival lab has multiple models on that Pareto frontier. Pricing compounds the advantage: Gemini 3.5 Flash is listed at USD 1.50 (approx. RM6.90) for input and USD 9.00 (approx. RM41.40) for output per million tokens, versus GPT-5.5’s USD 5.00 (approx. RM23.00) input and USD 30.00 (approx. RM138.00) output. For developers running persistent agents, batch refactors, or large-scale code analysis, this cost–speed profile can dramatically reduce infrastructure spend while enabling more ambitious, long-horizon workloads.
Beating Yesterday’s Pro: What Capability Compression Means
Perhaps the most telling data point is historical: a Flash-tier model now outperforms Google’s own flagship from just months ago. Gemini 3.5 Flash surpasses Gemini 3.1 Pro on key coding and agentic benchmarks, including Terminal-Bench 2.1, GDPval-AA, and MCP Atlas. This reflects rapid capability compression—features and performance that once required a premium Pro model are now available in a faster, cheaper tier. On GDPval-AA, for example, Gemini 3.5 Flash’s 1,656 Elo represents a leap over Gemini 3.1 Pro and earlier Gemini 3 Flash models, and it now clears previous leaders like Claude Sonnet 4.6 on agentic metrics. For AI adoption strategies, this compresses upgrade cycles: teams can no longer assume that last quarter’s Pro will remain superior to today’s “lite” tiers. Model selection becomes less about brand hierarchy and more about fresh, benchmark-driven evaluation.

Implications for Developers: Choosing Gemini 3.5 Flash as a Default
Google is signaling its own answer to the model selection question by making Gemini 3.5 Flash the default AI model for the Gemini app and AI Mode in Search. The model is explicitly designed for long-horizon, action-oriented workflows: planning across massive codebases, deploying multiple subagents in parallel via platforms like Antigravity, and sustaining complex multi-step processes. It also powers Gemini Spark, a personal AI agent that runs continuously on a user’s behalf. For developers, the practical takeaway is clear. When evaluating AI model performance comparison data for new products, Gemini 3.5 Flash should be considered a first-line option for coding-heavy, agentic AI tasks where latency and cost matter as much as raw intelligence. Pro-tier models may still be justified for edge cases, but the default assumption now tilts toward a fast, capable Flash model at significantly lower operating cost.