What Gemma 4 12B Is and Why It Matters for Local AI
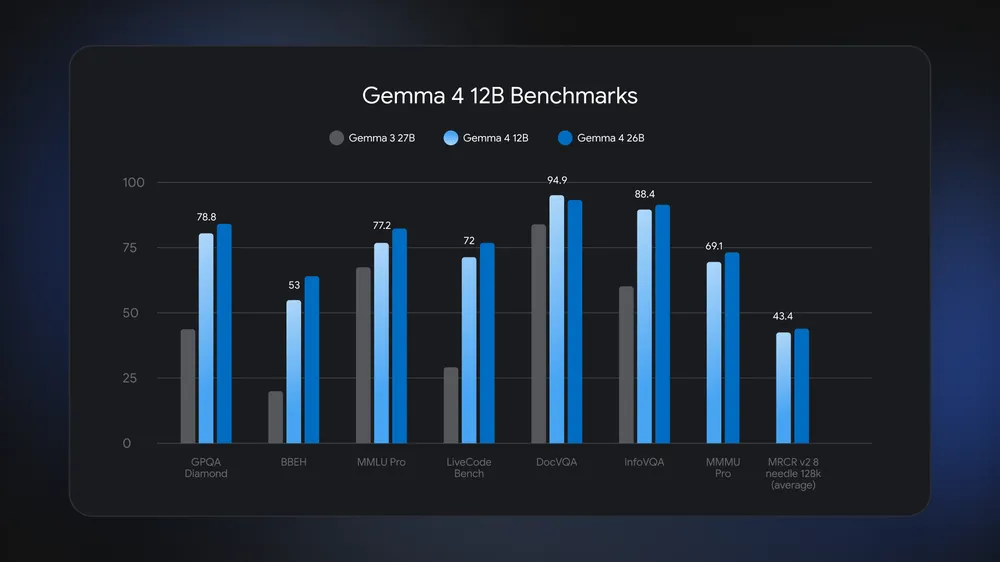
Gemma 4 12B is an open-weights, encoder‑free multimodal AI model that you can run locally on a standard laptop with 16GB RAM, handling text, images, audio, code, and tools without requiring any dedicated GPU or special accelerator hardware. Google DeepMind designed this 12‑billion‑parameter model to fill the gap between small phone‑class models and heavy workstation‑class systems, while keeping quality close to the larger Gemma 4 26B Mixture of Experts model. It uses roughly half the memory of the 26B variant, yet outperforms the older Gemma 3 27B on benchmarks like GPQA Diamond, MMLU Pro, and DocVQA. Because the weights are released under Apache 2.0 and are available on platforms such as Hugging Face and Kaggle, you can treat Gemma 4 12B as the foundation of a privacy‑friendly multimodal AI laptop that runs entirely on-device.

Setting Up Gemma 4 12B on a 16GB RAM Laptop
To run Gemma 4 locally, start by confirming you have at least 16GB of system RAM or VRAM; this is enough for the full model, which weighs just under 18GB. Download the open weights from a supported hub such as Hugging Face or Kaggle, then choose an inference framework that fits your workflow: LiteRT‑LM for speed and Multi‑Token Prediction, or desktop tools like LM Studio and Ollama for a friendlier interface. According to Google, Gemma 4 12B “runs locally on any laptop with 16GB of system RAM or VRAM,” making it practical for on-device machine learning and local AI inference on everyday machines. If you prefer a server-style setup, LiteRT‑LM can start an OpenAI‑compatible endpoint using a single serve command, while llama.cpp support lets you integrate the 16GB RAM AI model into existing local tooling.

How the Encoder-Free Multimodal Architecture Boosts Laptop Performance
Most multimodal AI laptop setups rely on separate vision and audio encoders, which add memory use and latency. Gemma 4 12B removes that overhead by feeding multimodal inputs directly into a single decoder‑only transformer with the same advanced decoder design as Gemma 4 31B Dense. For images, a compact 35‑million‑parameter vision embedder splits each image into 48×48 pixel patches and projects them into the model’s hidden space with a single matrix multiplication, replacing 27 layers of a vision transformer and roughly 550 million parameters used in other medium Gemma 4 models. Audio is even more direct: 16 kHz waveforms are sliced into 40‑millisecond frames and linearly projected into the same vector space as text, giving you native audio support without a separate encoder. This unified path keeps memory use tight and simplifies fine‑tuning, since a single set of weights covers text, images, and audio.
Optimizing Local Inference with LiteRT-LM and Multi-Token Prediction
Once Gemma 4 12B is installed, you can push local AI inference performance further using LiteRT‑LM. This framework is tuned for on-device machine learning and supports Multi‑Token Prediction (MTP) drafters that use spare compute cycles to guess several future tokens at once, making text generation faster and smoother in long conversations. Google reports that LiteRT‑LM can deliver up to 2.2× faster inference with MTP on supported hardware, which matters when you are running a 12B model on a CPU‑first multimodal AI laptop. Gemma 4 12B is also the first Gemma 4 model that ships with MTP enabled by default, so you benefit immediately when using compatible runtimes. Because the architecture is encoder‑free and uses shared weights for multimodal inputs, standard adapter techniques like LoRA can update the full multimodal loop in one pass, keeping tuning runs efficient on 16GB machines.
Building Practical Multimodal Agents on Your Laptop
With Gemma 4 12B running locally, you can build agentic workflows that combine text, images, audio, and tool calls on a single laptop. The model supports speech recognition, speaker diarization, code generation, image understanding, and even video analysis, as shown in a demo where it processed a five‑minute Google I/O keynote clip with 313 video frames and synchronized audio. Integration with Google AI Edge means you can build and experiment locally using tools like the AI Edge Gallery app, which can turn natural language prompts into working scripts or webpages. You might create a multimodal AI laptop assistant that reads PDFs, summarizes charts, inspects screenshots, and runs shell commands or Python tools entirely on-device. Because everything runs via local AI inference on a 16GB RAM AI model, you get faster iteration, better privacy, and fewer dependencies on remote cloud services.





