Cursor Tries to Break Out of Claude’s Shadow
Cursor has spent recent quarters watching Anthropic’s Claude Code dominate the conversation around AI coding tools. While Cursor still reports a billion lines of accepted code per day and usage across most large enterprises, market sentiment has shifted toward autonomous coding agents and vertically integrated model providers. Anthropic, in particular, enjoys a structural advantage: Cursor must pay Anthropic for inference even as it competes with Claude inside the IDE. Composer 2.5 is Cursor’s attempt to change that dynamic by fielding its own competitive in-house model, tuned specifically for coding. By matching or approaching headline benchmarks from leading Claude and GPT models while undercutting them on code generation pricing, Cursor is signaling that it does not intend to remain a thin interface over third-party models. Instead, the company is repositioning Composer as a full-fledged coding agent that can stand beside Claude and GPT rather than sit beneath them.

Cost-Efficient Code Generation: Up to 10x Cheaper on Benchmarks
Composer 2.5’s most aggressive differentiation is economic. Cursor prices the standard model at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster default variant at USD 3.00 (approx. RM13.80) per million input and USD 15.00 (approx. RM69.00) per million output tokens. Cursor argues that, when normalized against benchmark performance, this yields up to 10x better cost efficiency than rival AI coding tools built on Claude or GPT. That framing directly targets organizations that are starting to feel the financial weight of large-scale agentic workflows and multi-file refactors. By pairing near-frontier benchmark scores with significantly lower per-token pricing, Composer 2.5 turns code generation pricing itself into a competitive weapon. For teams that run continuous, long-horizon coding jobs—such as large refactors, framework upgrades, or test generation—the cumulative savings could become a decisive factor in tool selection.
Reinforcement Learning and 25x Synthetic Training for Coding Reliability
Rather than swapping out its base model, Cursor kept Moonshot’s Kimi K2.5 checkpoint and focused on post-training. Composer 2.5 was exposed to 25 times more synthetic coding tasks than its predecessor, alongside tougher reinforcement learning environments. Cursor highlights the use of targeted reinforcement learning with localized textual feedback, allowing the system to correct specific missteps during long task rollouts instead of only scoring entire trajectories. This approach aims to improve behavioral calibration: communication style, adherence to nuanced instructions, and consistency of code changes across a project. By scaling synthetic data and fine-grained RL corrections, Composer 2.5 is engineered not just to pass benchmarks, but to behave more predictably as a coding agent working inside complex repositories. For developers, this should translate into fewer derailments mid-session, better handling of tool calls, and more stable multi-step editing sequences compared with prior Composer releases.

Benchmarking Against Opus and GPT on Long-Running Coding Tasks
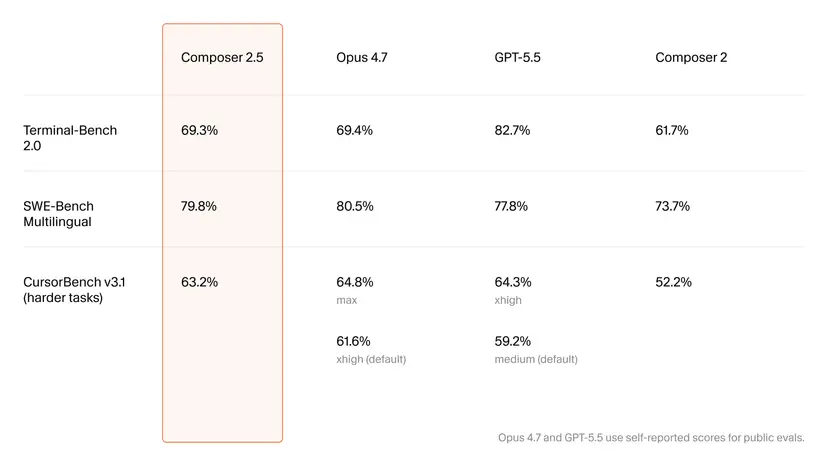
On headline benchmarks, Composer 2.5 now sits in the same conversation as top Claude and GPT models. It scores 79.8% on SWE-Bench Multilingual, narrowly trailing Opus 4.7’s 80.5% while edging past GPT-5.5’s 77.8%. On Terminal-Bench 2.0, it reaches 69.3%, up from Composer 2’s 61.7% and nearly identical to Opus 4.7’s 69.4%, though still behind GPT-5.5 at 82.7%. Cursor’s own harder CursorBench v3.1 shows 63.2% for Composer 2.5, compared with Opus 4.7’s 64.8% in its max setting and 61.6% in its default configuration; GPT-5.5’s default sits at 59.2%. These results suggest that, especially at default settings, Composer 2.5 can match or beat stronger but more expensive competitors on the kind of extended, multi-step coding tasks that matter for real development workflows, reinforcing its positioning as a viable Claude alternative for sustained agentic work.
Strategic Comeback or Just Another Benchmark Bump?
Composer 2.5 arrives amid skepticism that benchmark wins automatically translate into better day-to-day coding productivity. Developers on community forums note that even top models often produce code needing heavy cleanup or failing to respect project context. Cursor itself acknowledges that the real test will be live multi-file refactors and long-running agent sessions inside existing repositories. Still, the company has momentum: four Composer versions in seven months, visible gains on Terminal-Bench and its own CursorBench, and a roadmap that includes a larger model built with SpaceXAI using significantly more compute. If Composer 2.5 can turn its reinforcement learning advances and cost efficiency into noticeably smoother long-horizon coding sessions, Cursor could shift the narrative from "interface on top of Claude" to first-class AI coding platform. In a market where Claude and GPT set the bar, Cursor is betting that cheaper, tuned, and task-specific will beat pure model size.