
What Local GPU Processing Means for AI Workloads
Local GPU processing is the practice of running AI models and automation tasks directly on a user’s own graphics hardware, shifting on-device AI inference away from distant cloud servers to reduce latency, cut infrastructure costs, and keep data closer to its source for privacy and control. This shift is driven by the growing power of consumer GPUs and edge GPU computing, which allow laptops, desktops and small-form-factor devices to handle workloads that previously demanded data center resources. For enterprises, the trend also aligns with the need to increase GPU utilization and avoid idle accelerated compute. Instead of paying for cloud-only AI infrastructure, organizations and individuals can offload a growing share of AI inference and agent workloads to PCs, local stations and compact accelerators while still reaching out to the cloud for selective, high-value tasks when needed.
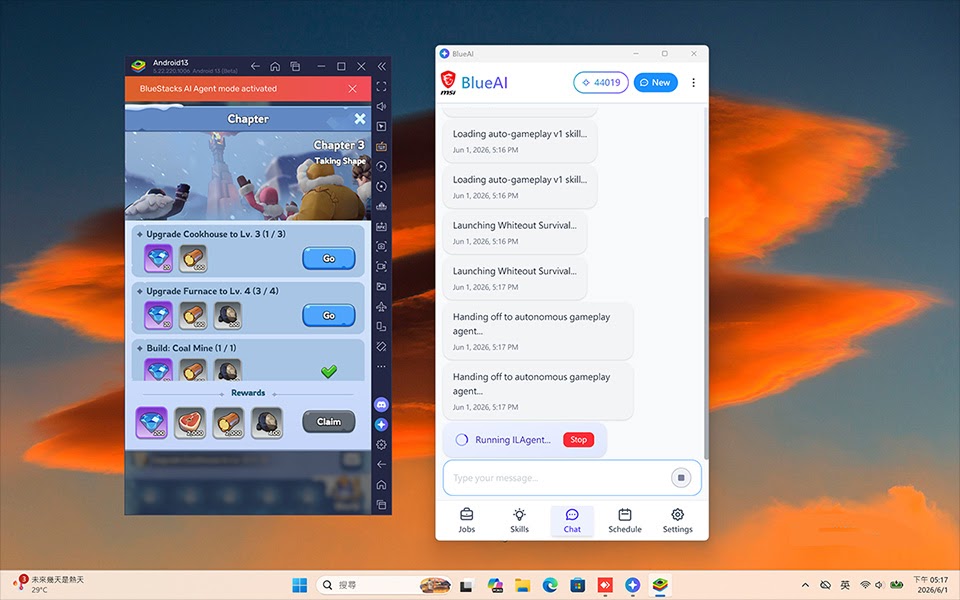
MSI and BlueStacks Turn Gaming Laptops into Local AI Agents
MSI and BlueStacks’ Blue AI Worker shows how GPU acceleration laptops can run cloud-free AI workloads in everyday devices. The software installs on MSI gaming lines such as Titan, Raider, Stealth, Crosshair, Katana and Cyborg, using the onboard GPU for on-device AI inference. A locally tuned vision-language model reads the laptop display to interpret game events instead of streaming high-resolution video to remote servers. Only light, symbolic reasoning calls go to the cloud, shrinking bandwidth needs and improving privacy. Blue AI Worker also uses idle GPU cycles when gamers switch windows, turning unused compute into background task automation. To highlight savings versus API-driven services, MSI introduces a “Token Mileage” metric on product sheets and within the software, estimating how much work is processed locally rather than billed per token in the cloud, and showing in real time how local GPU processing displaces recurring cloud usage.
OWC Stack AI Extends GPU Memory for Local LLMs
Running large language models locally is often limited by GPU memory, especially on compact systems like small desktops. OWC’s Stack AI aims to ease that constraint by expanding effective GPU memory across a Thunderbolt 5 connection. Physically resembling a small aluminum hub that can sit under a desktop machine, Stack AI combines storage with high-speed flash that acts as an external working memory pool for the host GPU. Unlike an external GPU enclosure, it is described as a memory enhancement rather than a separate processor, so it focuses on letting larger models fit into an on-device AI inference flow. Initial support targets Windows and Linux, with plans for future compatibility with more platforms. Because it is portable and desk-friendly, a team can share one unit between notebooks or workstations, helping more users experiment with cloud-free AI workloads that would otherwise exceed their native VRAM capacity.
NVIDIA and Microsoft Build a PC-to-Cloud Agentic AI Stack
NVIDIA and Microsoft are building a common stack that connects RTX-based consumer PCs with enterprise systems such as DGX Station for Windows and Azure Local. RTX Spark PCs are positioned as personal-agent machines, offering up to 1 petaflop of AI performance and as much as 128 GB of unified memory for local GPU processing of sizeable models. For deskside deployments, DGX Station for Windows brings the GB300 Grace Blackwell Ultra Desktop Superchip with up to 748 GB of coherent memory and up to 20 petaflops of FP4 performance, capable of running models up to 1 trillion parameters on premises. According to eeNews Europe, this stack is meant to let developers “build, run and scale agents across Windows devices, Azure cloud services and local deployments,” turning Windows endpoints into managed nodes for agentic AI while still integrating Linux tooling through Windows Subsystem for Linux where needed.
Qumulo’s Data Fabric Keeps Distributed GPUs Fed
While local GPU processing shifts compute closer to users, enterprises still need to keep distributed accelerators busy. Qumulo’s Cloud AI Accelerator focuses on data access rather than raw hardware, presenting a real-time AI data fabric that links on-premises storage, edge locations and multi-cloud environments to GPU resources without replication or staging delays. According to Qumulo’s analysis, average enterprise GPU utilization sits near 5%, meaning expensive accelerators remain idle most of the time because data must be copied and moved before inference can start. The Cloud AI Accelerator combines Cloud Native Qumulo, Qumulo Cloud Data Fabric and Qumulo NeuralCache to create what the company calls GPU liquidity, allowing workloads to run wherever GPUs are available instead of wherever data is stuck. For edge GPU computing and hybrid deployments, this approach reduces data-gravity bottlenecks and improves the effective return on both local and cloud AI investments.









